Introduction à l’intelligence artificielle
Algorithmique – Session 6
- Qu’est-ce que l’intelligence artificielle ?
- Applications de l’apprentissage automatique
- Algorithmes standards pour l’apprentissage automatique
- Une introduction large au deep learning
Qu’est-ce que l’intelligence artificielle ?
AI and Machine Learning
Intelligence artificielle (IA)
- Une famille de techniques qui visent à extraire des connaissances à partir d’observations afin de résoudre des tâches d’automatisation
Apprentissage automatique (Machine Learning - ML)
-
Le machine learning (ML) est un sous-ensemble des algorithmes d’IA qui utilisent des données pour apprendre implicitement des solutions
-
Les données sont généralement multidimensionnelles, on considère donc des matrices de données, avec des échantillons en lignes et des caractéristiques en colonnes
Deep learning (DL)
- Un type d’approche ML qui s’est avéré très efficace pour résoudre des tâches très complexes telles que la compréhension du langage naturel ou la compréhension d’images
Applications de l’apprentissage automatique
Vision par ordinateur
Qu’est-ce que la vision par ordinateur ?
- Le domaine qui manipule les images pour prendre des décisions à partir de celles-ci.
Tâches courantes
- Classification d’images – Classifier la catégorie principale représentée dans l’image
- Détection d’objets – Détecter et localiser toutes les instances d’objets connus dans une image
- Segmentation sémantique – Chaque pixel de l’image est associé à une catégorie prédéfinie spécifique
- Estimation de pose humaine – Prédire la pose/action à partir d’une image
- Imagerie biomédicale – Segmentation des tissus (ex. tumeur, organes), diagnostic automatique, médecine prédictive, …
Applications de l’apprentissage automatique
Traitement du langage naturel
Que sont les grands modèles de langage (LLMs) ?
Les LLMs sont des modèles de deep learning très larges capables de modéliser plusieurs langues
Tâches courantes
- Traduction entre langues
- Reformulation, résumé
- Réponse à des questions
- Tâches de raisonnement basique
- Conversation, jeu de rôle
- Programmation logicielle
Applications de l’apprentissage automatique
Traitement du signal & autres applications
Traitement de la parole
Le deep learning moderne peut aussi traiter la parole parlée, en abordant les tâches suivantes :
- Speech to text – Transcrire la parole en texte écrit
- Voice cloning – Cloner votre voix dans une langue différente
Application à d’autres signaux
- Audio – Vocalisations animales (bioacoustique), reconnaissance d’événements sonores, localisation d’événements sonores,…
- Musique – Reconnaître le genre, transcrire notes / rythmes, séparer pistes / instruments individuels, améliorer la qualité du signal, générer de la nouvelle musique, …
- Biosignaux – Interfaces cerveau-ordinateur ou diagnostic automatique utilisant des signaux cardiaques / cérébraux
- Prévision – prédire le futur d’une série temporelle (finance, énergie, météo, …)
Algorithmes standards pour l’apprentissage automatique
Généralités
Cadre multidimensionnel
-
$f:\mathbb{R}^d \to \mathbb{R}^p $,
-
Entrée $d$-dimensionnelle $x$ et sortie $p$-dimensionnelle telle que $y = f(x)$
-
$f$ est défini par un ensemble de paramètres
Phase d’entraînement : apprentissage des paramètres de $f$
- Un jeu de données d’entraînement est utilisé pour optimiser les paramètres de $f$ en minimisant une fonction de perte $\mathcal{L}$
Inférence
Utiliser $f$ sur un jeu de test composé de données non vues pendant l’entraînement
Algorithmes standards pour l’apprentissage automatique
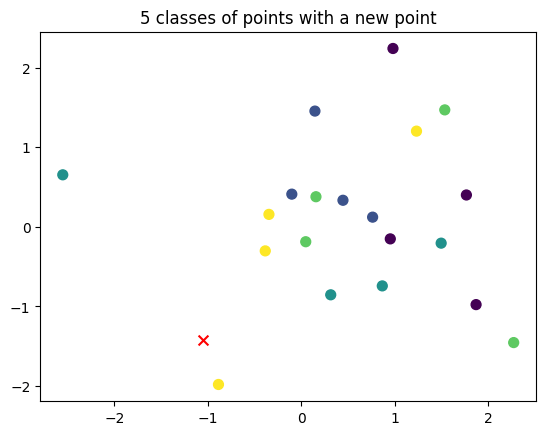
k-nearest neighbors
Cadre
- $k$-NN pour classifier $C$ classes
- Un jeu d’entraînement d’échantillons $x \in \mathbb{R}^d$
- Chaque échantillon du jeu d’entraînement est associé à une étiquette catégorielle de vérité terrain $y \in [1,\dots, C]$
Principe
-
Étant donné un entier strictement positif $K$, un jeu d’entraînement d’échantillons
-
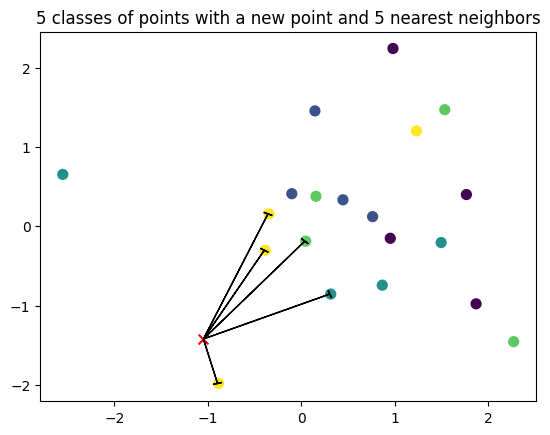
Pour chaque élément $x_{test}$ du jeu de test :
- Calculer toutes les distances paires avec les éléments du jeu d’entraînement
- Associer l’étiquette correspondant au vote majoritaire des étiquettes des $K$ exemples les plus proches
Algorithmes standards pour l’apprentissage automatique
k-nearest neighbors
Algorithmes standards pour l’apprentissage automatique
k-nearest neighbors
Algorithmes standards pour l’apprentissage automatique
k-means
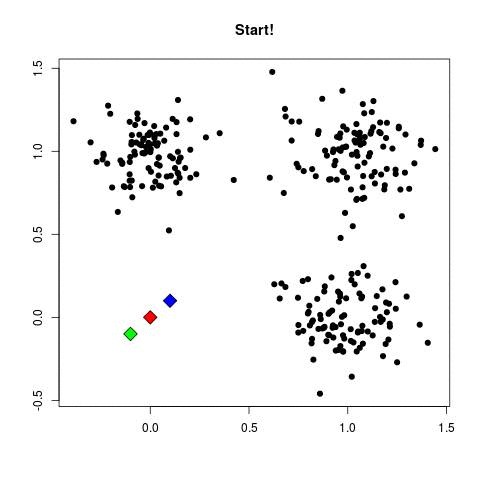
Input:
- Dataset: {x_1, x_2, ..., x_N}, where x_i ∈ ℝ^d
- Number of clusters: K
- Convergence threshold: ε (e.g., 10^-4)
Output:
- K cluster centroids {μ_1, μ_2, ..., μ_K} and cluster assignments {C_1, C_2, ..., C_K}
Steps:
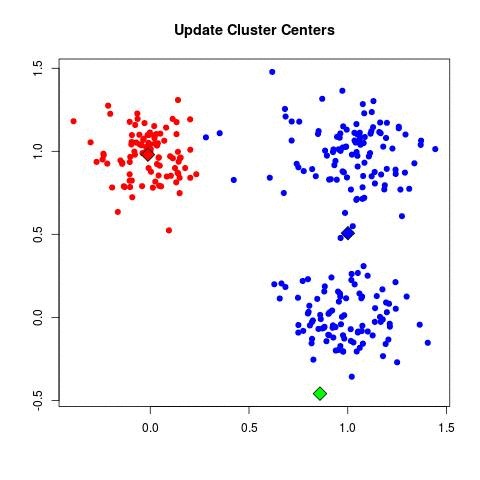
1. (initialize centroids):
- Randomly select K data points as the initial centroids {μ_1, μ_2, ..., μ_K}.
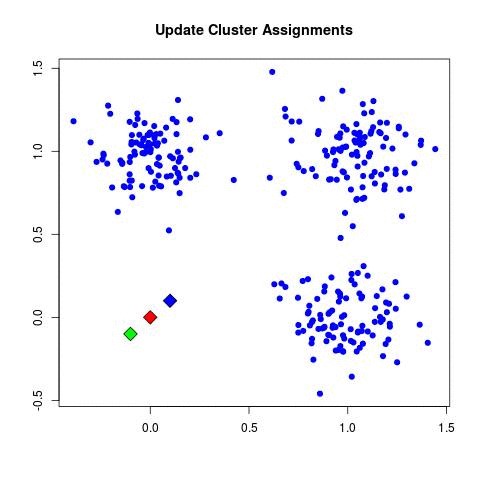
2. (repeat until convergence):
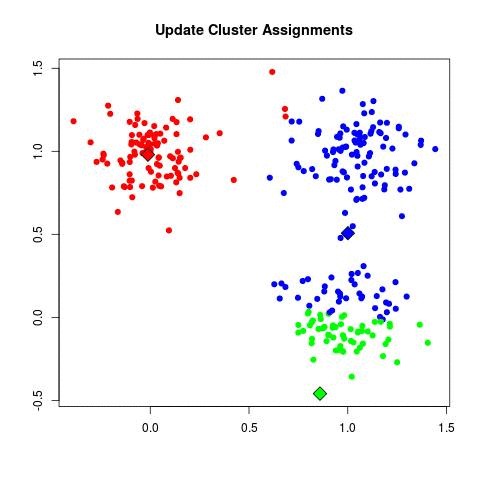
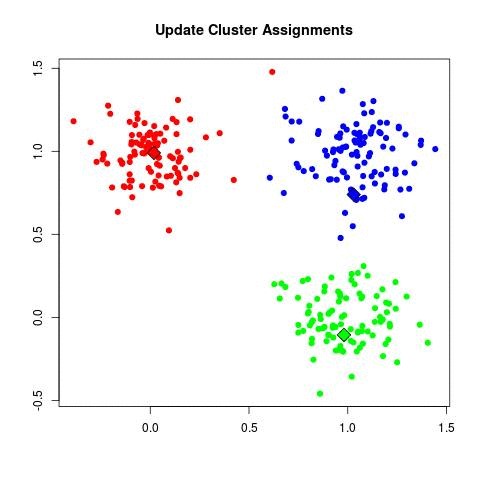
| a. (assign points to nearest centroid):
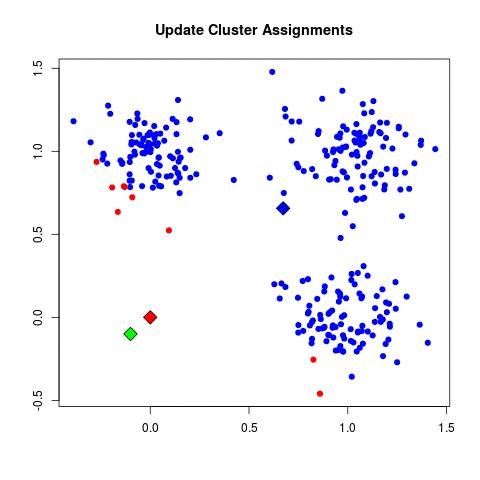
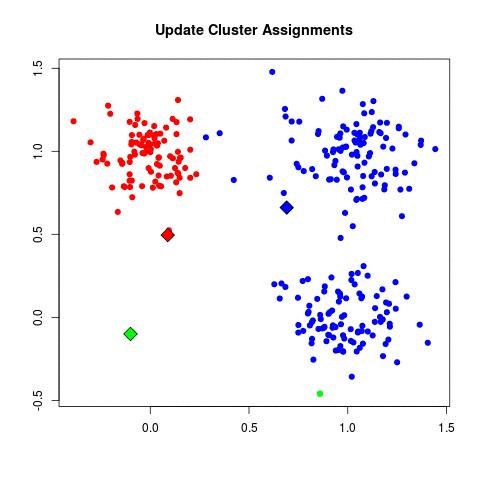
| - For each data point x_i:
| - Assign x_i to the cluster C_k where k = argmin_j ||x_i - μ_j||^2.
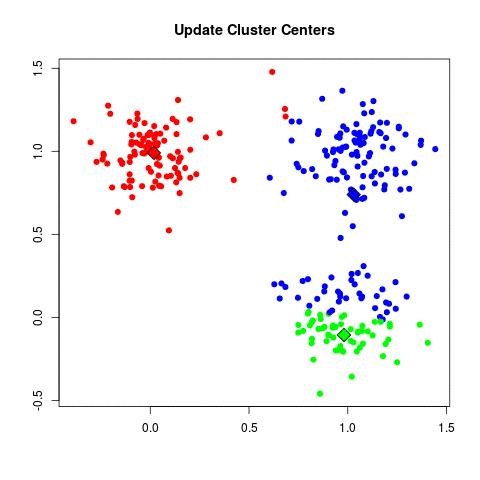
| b. (update centroids):
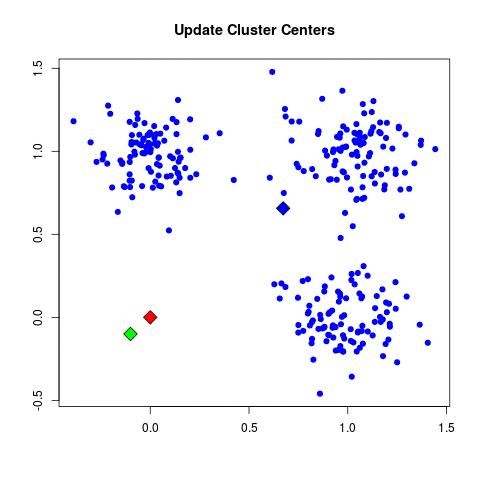
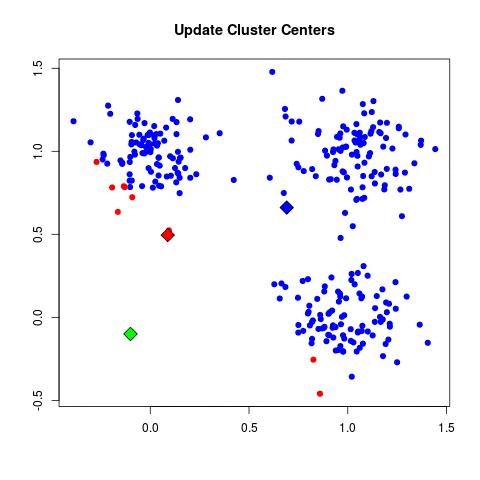
| - For each cluster C_k, recompute the centroid:
| - Set μ_k = (1 / |C_k|) Σ_{x_i ∈ C_k} x_i.
| c. Check for convergence:
| - Compute the change in centroids Δ = Σ_k ||μ_k^new - μ_k^old||.
| - If Δ < ε, stop the iteration.
3. (return the final centroids and cluster assignments)Algorithmes standards pour l’apprentissage automatique
k-means
Algorithmes standards pour l’apprentissage automatique
k-means
Algorithmes standards pour l’apprentissage automatique
k-means
Algorithmes standards pour l’apprentissage automatique
k-means
Algorithmes standards pour l’apprentissage automatique
k-means
Algorithmes standards pour l’apprentissage automatique
k-means
Algorithmes standards pour l’apprentissage automatique
k-means
Algorithmes standards pour l’apprentissage automatique
k-means
Algorithmes standards pour l’apprentissage automatique
k-means
Algorithmes standards pour l’apprentissage automatique
k-means
Algorithmes standards pour l’apprentissage automatique
k-means
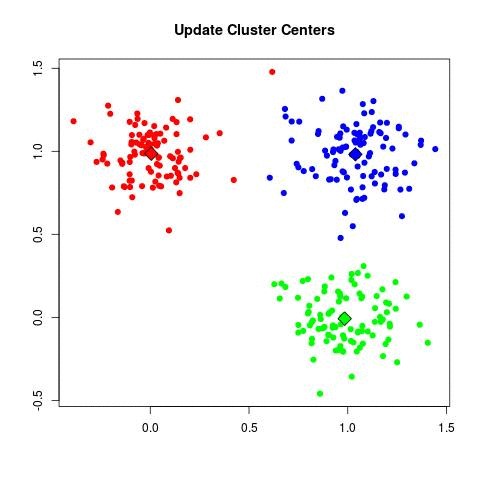
Algorithmes standards pour l’apprentissage automatique
k-means
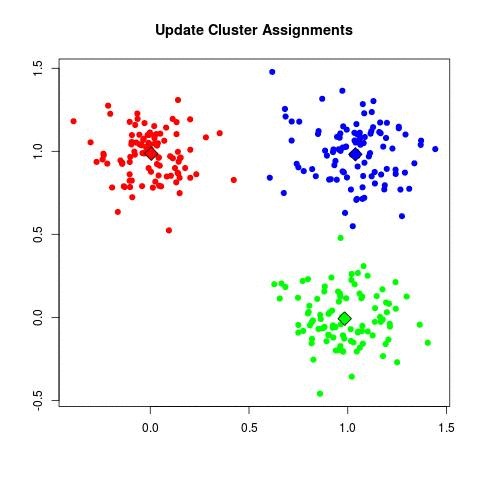
Algorithmes standards pour l’apprentissage automatique
k-means
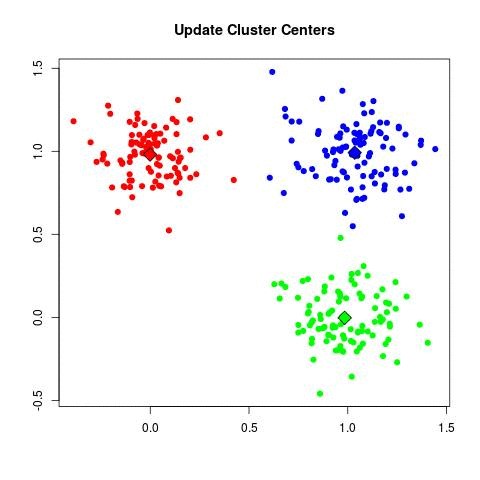
Algorithmes standards pour l’apprentissage automatique
k-means
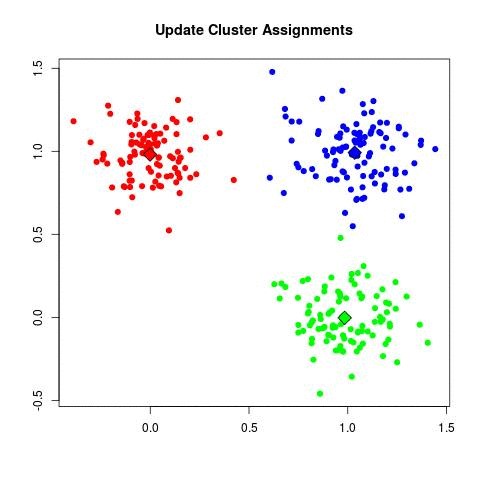
Une introduction large au deep learning
Qu’est-ce que le deep learning ?
Éléments principaux
-
Une famille de méthodes d’apprentissage automatique, basées sur des compositions de fonctions simples appelées couches
-
Appris de bout en bout à partir de données brutes, avec peu ou pas de prétraitement
-
Entraîné en utilisant la différentiation automatique
Exemple - Perceptron multi-couches (MLP)
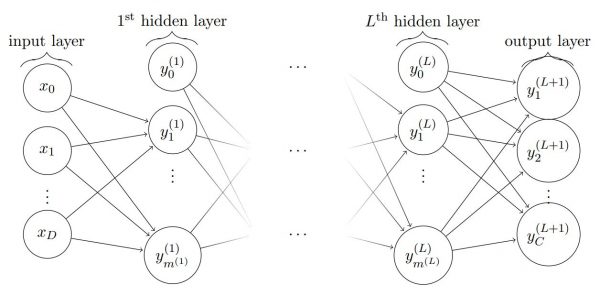
Récapitulatif de la session
Éléments principaux à retenir
-
L’intelligence artificielle est une famille de techniques qui visent à extraire des connaissances à partir d’observations afin de résoudre des tâches d’automatisation
-
Le machine learning est un sous-ensemble des algorithmes d’IA qui utilisent des données pour apprendre implicitement des solutions
-
Les modèles ML doivent être entraînés sur un jeu d’entraînement et évalués sur un jeu de test
-
Ils sont utilisés pour résoudre un large éventail de tâches dans de nombreux domaines, tels que la vision par ordinateur, le traitement du langage naturel, le traitement du signal, …
-
Les algorithmes standards pour l’apprentissage automatique incluent $k$-NN et $k$-means
Récapitulatif de la session
Et ensuite ?
Activité pratique (~2h30)
Programmer les algorithmes standards
- $k$-NN
- $k$-means
Après la session
- Revoir les articles de la session
- Vérifier votre compréhension avec le quiz
- Compléter l’activité pratique
Évaluation
- L’évaluation finale couvrira toutes les sessions du cours
- Les modalités seront annoncées plus tard par mail