Properties of algorithms
Algorithmics – Session 4
- Algorithmic complexity
- Binary search tree
- Randomized algorithms
Algorithmic complexity
How to measure the performance of an algorithm?
What kind of performance?
-
Intituively, we are interested in capturing the speed and the space that an algorithm takes on your computer.
-
Constraint – The performances measures should be machine independent.
Complexity
-
Solution – For an input of a given size, count the number of fixed-time operations taken by the algorithm to finish.
-
Depending on the studied algorithms you can focus on other types of measures such as the size of memory taken, number of rounds, the number of messages exchanged.
$\rightarrow$ For the rest of the course, we will focus on the speed of an algorithm.
Algorithmic complexity
Why this constraint?
Problem
- The time taken by an algorithm may vary from one execution to another.
Why?
- System resources availability (like CPU, memory, and disk access).
- Background processes running concurrently.
- Caching effects.
- Randomized execution.
Algorithmic complexity
Methods
-
There are several methods to complexity analysis:
- Pessimistic analysis – The most studied one, only focuses on worst-case scenario.
- Average analysis – Usually an upper bound on the average time taken by an algorithm. Classical in machine learning.
- In both cases, we are focusing in computing lower-bound (what can we hope), and upper-bound (what we have achieved).
-
The complexity of an algorithm is always related to a measurable input:
- Size of the data to process.
- Number of computers to reach.
- …
Algorithmic complexity
Main categories of complexity
-
When we do a pessimistic analysis, we usually want to ignore constant factors and low order terms.
-
Notations – Upper bounds ($O$), lower bounds ($\Omega$), tight bounds ($\Theta$).
Approximate time on a 1 GHz single-core machine
| Input $(n)$ | Constant $\Theta(1)$ | Log. $\Theta(log(n))$ | Linear $\Theta(n)$ | Log-linear $\Theta(n\times log(n))$ |
|---|---|---|---|---|
| 1000 | 1 | ≈ 10 | 1000 | ≈ 10,000 |
| Time | 1 ns | 10 ns | 1 μs | 10 μs |
| Input $(n)$ | Quadratic $\Theta(n^2)$ | Polynomial $\Theta(n^c)$ | Exponential $\Theta(2^n)$ |
|---|---|---|---|
| 1000 | 1,000,000 | $1000^c$ | $2^{1000}$ ≈ $10^{301}$ |
| Time | 1 ms | $10^{3c−9}$ s | $10^{281}$ millennia |
Binary search tree
Why do we need a new data structure?
An example
-
Challenge – Scheduling machine learning jobs in a high-performance computing cluster, where jobs have varying urgency based on factors like deadlines, computational needs, and impact.
-
Scenario – Urgent jobs (e.g., medical diagnosis model fine-tuning) should receive resources before less critical jobs (e.g., movie recommendation model training), regardless of submission time.
-
Question – How to efficiently prioritize and select the most urgent job as new jobs continuously arrive in the system?
What do you think?
-
Which data structure would you choose to easily add new jobs and quickly remove the most urgent?
-
Why is it a bad idea to store jobs in a list or in a sorted list?
Binary search tree
Definition
Binary search tree property
-
We say that a binary tree satisfies the binary search tree property if for every node:
- Keys in a node’s left subtree are less than the key stored at the node.
- Keys in the node’s right subtree are greater than the key stored at the node.
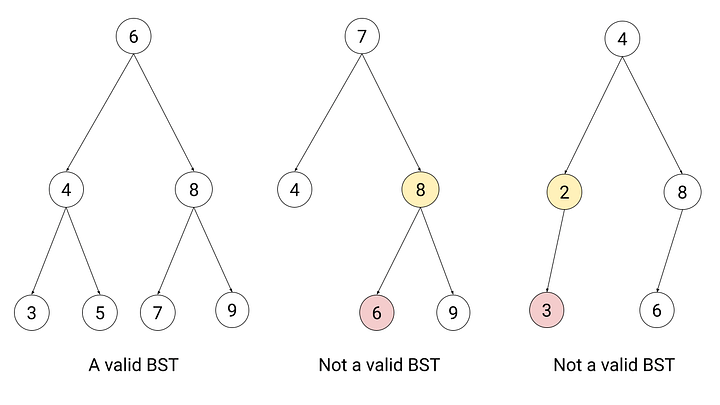
Binary search tree
How to use it?
Classical operations
- Insertion – Add a new node while maintaining the BST property.
- Search – Find a node by traversing from the root, following left or right based on key comparison.
- Deletion – Remove a node and adjust the tree to maintain the BST property, handling cases like no children, one child, or two children.
- Traversal – Visit all nodes in a specific order (in-order, pre-order, post-order) to process or display the tree’s contents.
- Finding minimum/maximum – Find the minimum (leftmost node) or maximum (rightmost node) value in the tree.
Remark
The complexity of all these operations is of $O(h)$, where $h$ is the height of the tree.
Randomized algorithms
What is a randomized algorithm?
Probabilistic algorithm
-
An algorithm that generates a random number $r \in \{ 1, \ldots, R \}$ and makes decisions based on the value of $r$.
-
Note that given the same input on different executions, a randomized algorithm may:
- Run a different number of steps.
- Produce a different output.
Types of Probabilistic Algorithms
-
Monte-Carlo – Polynomial time, correct with high probability:
- Used when exact correctness is not essential, but performance is critical.
- e.g., $pi$ estimation from randomly generated points in the unit square.
-
Las-Vegas – Expected polynomial time, always correct:
- Used when correctness is non-negotiable, but performance may be variable.
- e.g., find a location of a 1 in large and sparse binary vector using randomly generated indexes.
Recap of the session
What’s next?
Practical activity (~2h30)
Complexities of operations on lists and BSTs
- Determine complexities of algorithms
- Compare complexities
- Manipulate BSTs
- Manipulate random numbers
After the session
- Review the articles of the session
- Check your understanding with the quiz
- Complete the practical activity
- Check next session’s “Before the class” section
Evaluation
- Not yet, but get ready for a MCQ during session 6
- Revise everything up to session 4 included