Introduction to artificial intelligence
Algorithmics – Session 6
- What is artificial intelligence?
- Applications of machine learning
- Standard algorithms for machine learning
- A broad introduction to deep learning
What is artificial intelligence?
AI and Machine Learning
Artificial intelligence (AI)
- A family of techniques that aim at extracting knowledge from observations in order to solve automation tasks
Machine Learning (ML)
-
Machine learning (ML) is a subset of AI algorithms that use data to implicitely learn solutions
-
Data is usually multidimensional, hence we consider data matrices, with samples in rows and features in columns
Deep learnng (DL)
- A type of ML approach that has proved to be very efficient at solving very complex tasks such as natural language understanding or image understanding
Applications of machine learning
Computer vision
What is Computer vision?
- The domain that manipulates images to make decisions out of them.
Common tasks
- Image classification – Classify the main category that is represented in the image
- Object detection – Detect and localize all instances of known objects in an image
- Semantic segmentation – Each pixel of the image is associated with a specific predefined categories
- Human pose estimation – Predicting the pose/action based on a picture
- Biomedical imaging – Tissue segmentation (e.g., tumor, organs), automatic diagnosis, predictive medicine, …
Applications of machine learning
Natural language processing
What are large language models (LLMs)?
LLMs are very large deep learning models that can model several languages
Common tasks
- Translation between languages
- Reformulation, summary
- Question answering
- Basic reasoning tasks
- Conversation, role play
- Software coding
Applications of machine learning
Signal processing & other applications
Speech processing
Modern Deep Learning can also deal with spoken speech, adressing the following tasks:
- Speech to text – Transcribe speech into written text
- Voice cloning – Clone your voice in a different language
Application to other signals
- Audio – Animal vocalizations (Bioacoustics), sound event recognition, sound event localization,…
- Music – Recognize the genre, transcribe notes / rhythms, separate individual tracks / instruments, enhance signal quality, generate new music, …
- Biosignals – Brain-computer interfaces or automatic diagnosis using cardiac / brain signals
- Forecasting – predicting the future of a time series (finance, energy, weather, …)
Standard algorithms for machine learning
Generalities
Multidimensional setting
-
$f:\mathbb{R}^d \to \mathbb{R}^p $,
-
$d$-dimensional input $x$ and $p$-dimensional output such as $y = f(x)$
-
$f$ is defined by a set of parameters
Training phase: learning the parameters of $f$
- A training dataset is used to optimise the parameters of $f$ by minimizing a loss function $\mathcal{L}$
Inference
Use $f$ on a test set composed of data not seen during training
Standard algorithms for machine learning
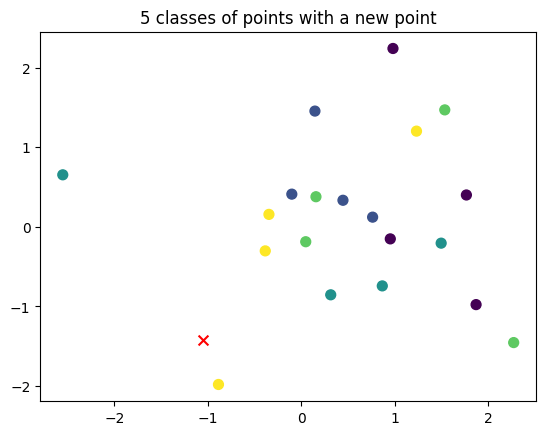
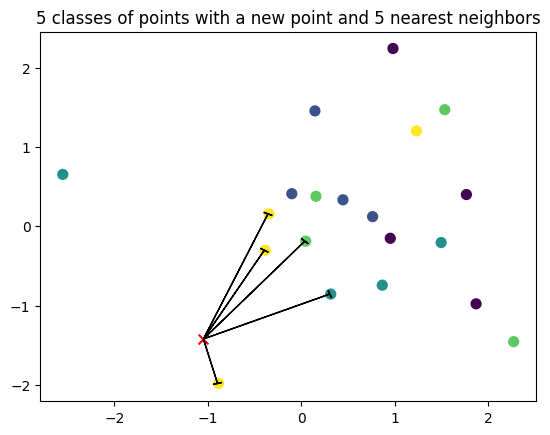
k-nearest neighbors
Setting
- $k$-NN for classifying $C$ classes
- A training set of samples $x \in \mathbb{R}^d$
- Each sample of the training set associated with a ground truth categorical label $y \in [1,\dots, C]$
Principle
-
Given a strictly positive integer $K$, a training set of samples
-
For each element $x_{test}$ of the test set:
- Compute all pairwise distances with elements of the training set
- Associate the label corresponding to the majority vote of the labels of the $K$ closest examples
Standard algorithms for machine learning
k-nearest neighbors
Standard algorithms for machine learning
k-nearest neighbors
Standard algorithms for machine learning
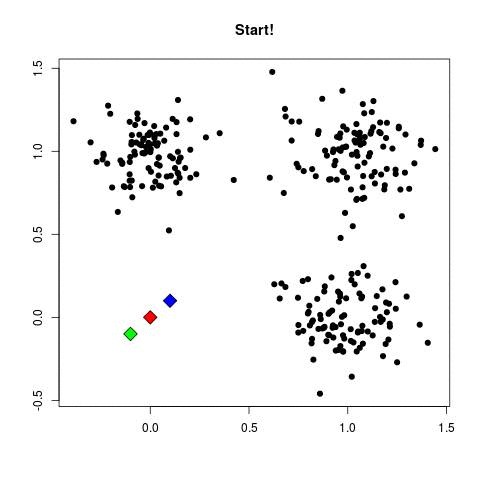
k-means
Input:
- Dataset: {x_1, x_2, ..., x_N}, where x_i ∈ ℝ^d
- Number of clusters: K
- Convergence threshold: ε (e.g., 10^-4)
Output:
- K cluster centroids {μ_1, μ_2, ..., μ_K} and cluster assignments {C_1, C_2, ..., C_K}
Steps:
1. (initialize centroids):
- Randomly select K data points as the initial centroids {μ_1, μ_2, ..., μ_K}.
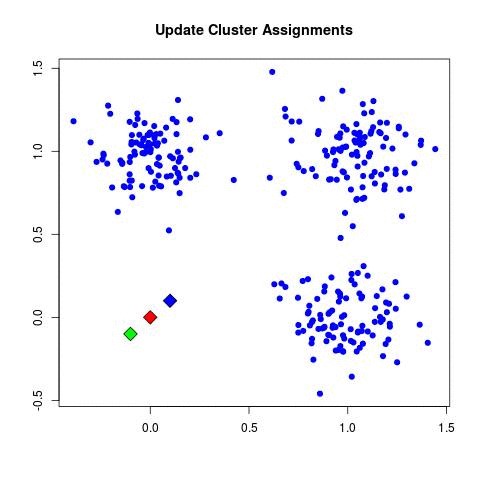
2. (repeat until convergence):
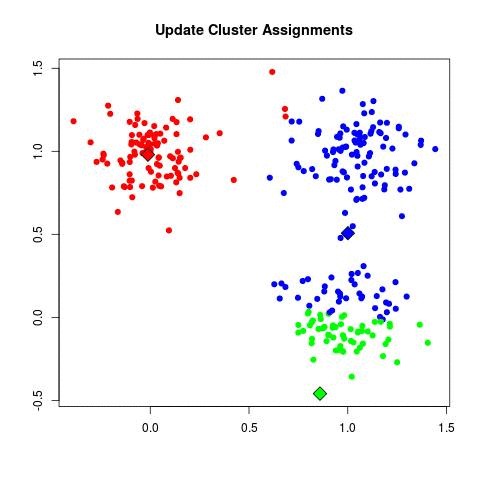
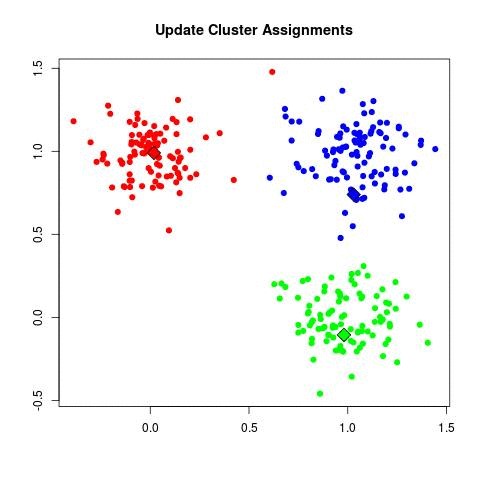
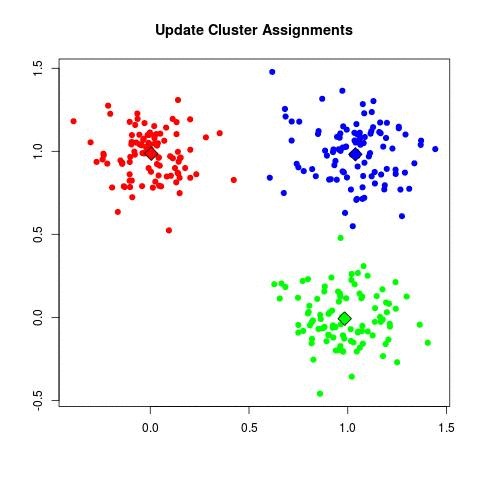
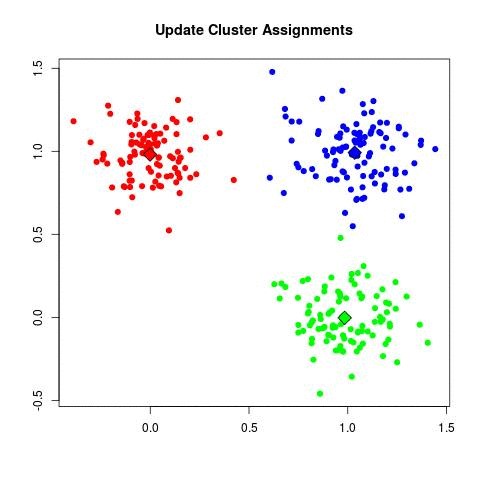
| a. (assign points to nearest centroid):
| - For each data point x_i:
| - Assign x_i to the cluster C_k where k = argmin_j ||x_i - μ_j||^2.
| b. (update centroids):
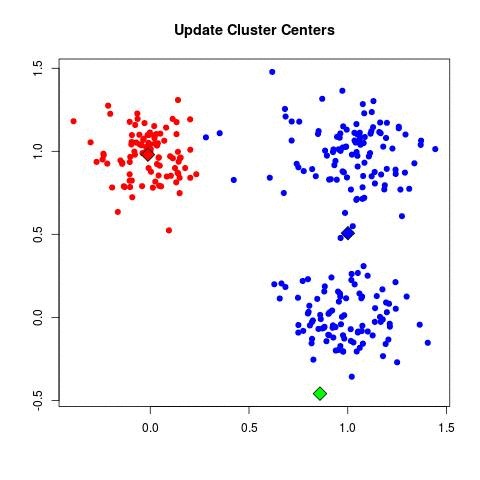
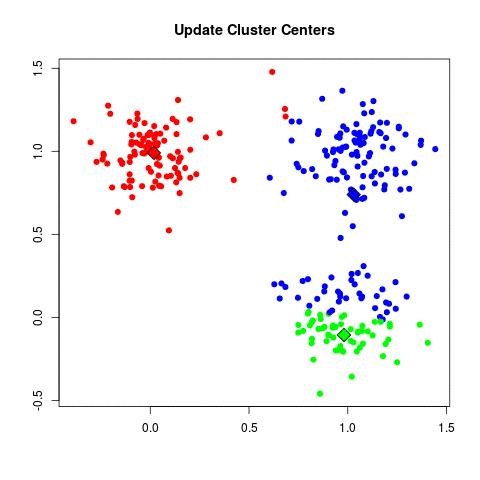
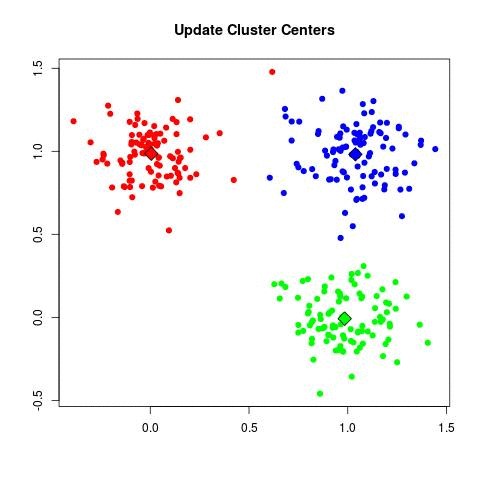
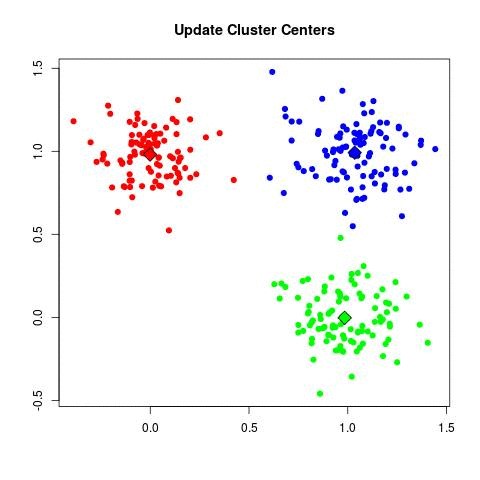
| - For each cluster C_k, recompute the centroid:
| - Set μ_k = (1 / |C_k|) Σ_{x_i ∈ C_k} x_i.
| c. Check for convergence:
| - Compute the change in centroids Δ = Σ_k ||μ_k^new - μ_k^old||.
| - If Δ < ε, stop the iteration.
3. (return the final centroids and cluster assignments)Standard algorithms for machine learning
k-means
Standard algorithms for machine learning
k-means
Standard algorithms for machine learning
k-means
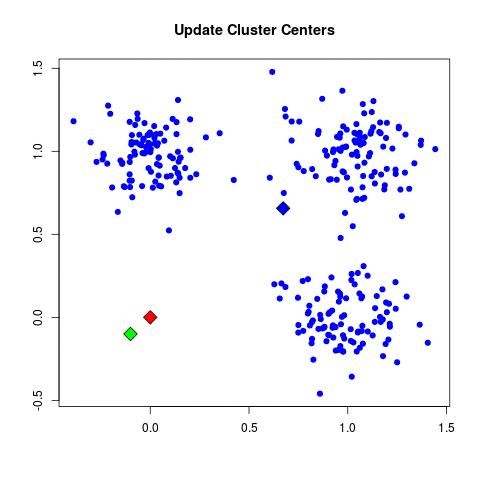
Standard algorithms for machine learning
k-means
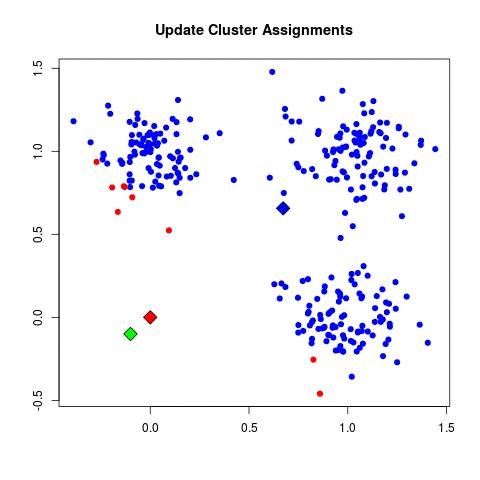
Standard algorithms for machine learning
k-means
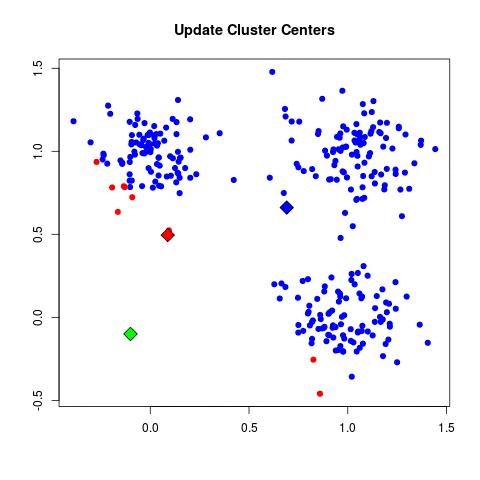
Standard algorithms for machine learning
k-means
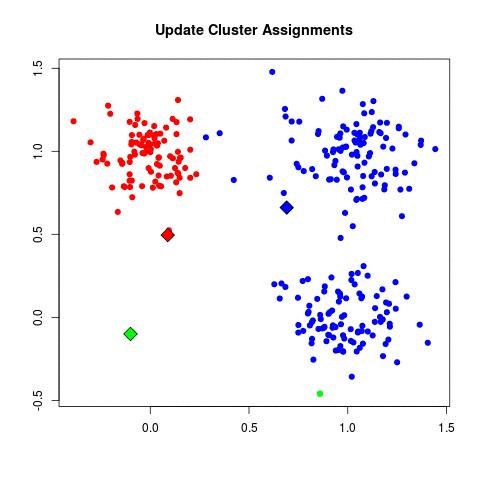
Standard algorithms for machine learning
k-means
Standard algorithms for machine learning
k-means
Standard algorithms for machine learning
k-means
Standard algorithms for machine learning
k-means
Standard algorithms for machine learning
k-means
Standard algorithms for machine learning
k-means
Standard algorithms for machine learning
k-means
Standard algorithms for machine learning
k-means
A broad introduction to deep learning
What is deep learning?
Main elements
-
A family of machine learning methods, based on compositions of simple functions called layers
-
Learnt end-to-end from raw data, from no to little preprocessing
-
Trained using automatic differentation
Example - Multi-layer perceptron (MLP)
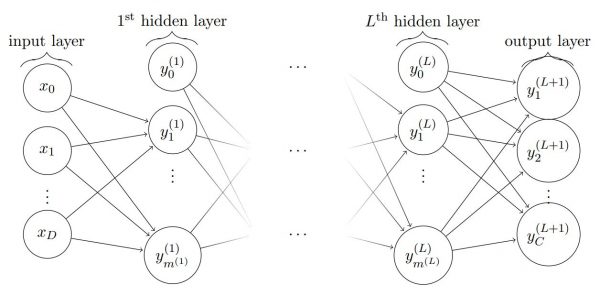
Recap of the session
Main elements to remember
-
Artificial intelligence is a family of techniques that aim at extracting knowledge from observations in order to solve automation tasks
-
Machine learning is a subset of AI algorithms that use data to implicitely learn solutions
-
ML models need to be trained on a training set and evaluated on a test set
-
They are used to solve a wide range of tasks in many domains, such as computer vision, natural language processing, signal processing, …
-
Standard algorithms for machine learning include $k$-NN and $k$-means
Recap of the session
What’s next?
Practical activity (~2h30)
Program standard algorithms
- $k$-NN
- $k$-means
After the session
- Review the articles of the session
- Check your understanding with the quiz
- Complete the practical activity
Evaluation
- Final evaluation will cover all sessions of the course
- Modalities will be announced later by mail