What is artificial intelligence?
Reading time15 minEn bref
Résumé de l’article
L’objectif de cet article est d’introduire les généralités sur l’intelligence artificielle (IA) et les sujets importants qui y sont liés. Il existe différentes façons de définir l’IA, mais dans la recherche moderne et les applications, l’IA fait souvent référence à des algorithmes qui apprennent à partir de données.
Dans cet article, nous proposons une brève définition de l’IA et des sujets importants associés : l’apprentissage automatique (ML) et l’apprentissage profond (DL).
Points clés
-
L’intelligence artificielle (IA) est une famille très large de techniques visant à extraire des connaissances à partir des données pour résoudre des tâches d’automatisation.
-
Les données sont généralement multidimensionnelles, c’est pourquoi on considère des matrices de données, avec des échantillons en lignes et des caractéristiques en colonnes.
-
L’apprentissage automatique (ML) est un sous-ensemble des algorithmes d’IA qui utilisent les données pour apprendre implicitement des solutions.
-
L’apprentissage profond (DL) est un type d’approche ML qui s’est avéré très efficace pour résoudre des tâches très complexes telles que la compréhension du langage naturel ou la compréhension d’images.
Contenu de l’article
1 — Qu’est-ce que l’IA ?
1.1 — Une définition simpliste
Une définition simple de l’IA peut être donnée comme suit :
L’IA est une famille de techniques visant à extraire des connaissances à partir d’observations afin de résoudre des tâches d’automatisation.
Cette définition peut être trop simple, mais définir l’IA ainsi est pratique car elle englobe tous les algorithmes et techniques qui peuvent être définis et implémentés sur un ordinateur.
Avec cette définition, les éléments suivants pourraient être considérés comme de l’IA :
- Une fonction mathématique.
- Un moteur de recherche.
- Un système de navigation qui trouve le chemin le plus court entre un point de départ et une destination.
- Un agent qui navigue dans un environnement.
- Un système qui recommande de la musique en fonction de l’historique d’écoute.
- Un chatbot.
- Un système qui reconnaît les espèces d’oiseaux à partir d’une photo ou d’un enregistrement de son chant.
Dans les cours précédents, vous avez vu plusieurs exemples d’algorithmes (recherche d’arbre, tri, …) qui peuvent entrer dans cette définition, car ils automatisent une certaine tâche. De nombreux algorithmes peuvent être définis dans le contexte des mathématiques discrètes (par exemple, en utilisant des graphes, arbres, chemins, …) afin de définir des algorithmes déterministes, ou peuvent également s’appuyer sur des algorithmes stochastiques (probabilistes).
1.2 — De quoi parle-t-on ?
Plus largement, l’IA peut aussi être définie comme permettant à une machine de raisonner sur des choses, ce qui est un pilier de la science-fiction depuis des siècles. Ainsi, le terme “intelligence artificielle” est généralement assez vague, et tend à désigner quelque chose de différent selon les époques.
À notre époque, pour la plupart des gens, l’IA désigne généralement des assistants “intelligents” (par exemple, ChatGPT, GitHub Copilot) mais aussi des modèles génératifs pour les images (par exemple, Midjourney), l’audio (par exemple, Suno), les vidéos (par exemple, Sora), etc. Bien que ces outils puissent sembler différents, ils reposent tous sur une technique commune, appelée “apprentissage automatique”.
Vous verrez ci-dessous et dans d’autres articles de cette session que l’apprentissage automatique lui-même peut être organisé en sous-catégories, selon le type de données disponibles, la tâche à résoudre, et le type d’algorithme utilisé. Le diagramme suivant (source) donne un bon aperçu de certains mots-clés que vous pouvez rencontrer :
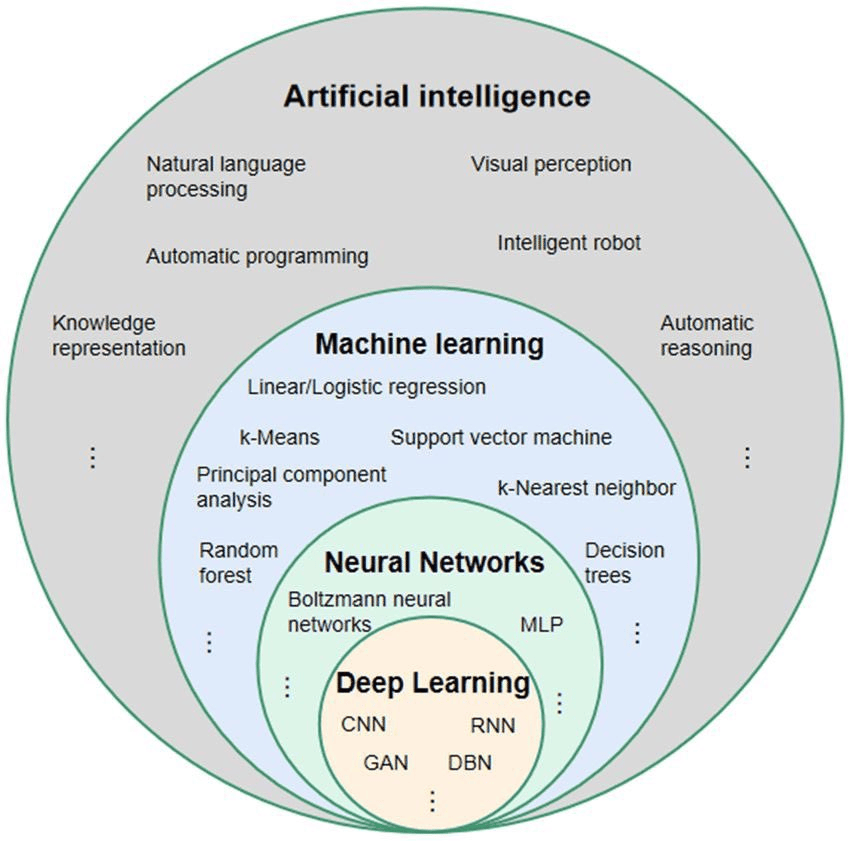
2 — Apprentissage automatique
2.1 — Définition générale
Comme mentionné ci-dessus, nous nous intéressons principalement à l’apprentissage automatique, qui vise à apprendre un modèle d’un concept large, à partir de données, avec un certain degré d’automatisation.
Formellement, dans la plupart des cas, nous pouvons modéliser l’extraction de connaissances comme une fonction $f:\mathbb{R}^d \to \mathbb{R}^p $ qui associe une entrée $d$-dimensionnelle $x$ à une sortie $p$-dimensionnelle $y = f(x)$. En général, $f$ est une fonction paramétrique, c’est-à-dire que sa sortie dépend de certains paramètres qui doivent être fixés avant d’utiliser la fonction.
L’apprentissage automatique (ML) est une famille de techniques qui tentent de apprendre cette correspondance directement à partir des données, pendant une phase dite de formation.
Pendant la phase de formation, un jeu de données est utilisé pour estimer les paramètres de $f$. Le but de cette phase est d’obtenir des paramètres qui vont généraliser à de nouveaux jeux de données qui n’ont pas été utilisés pendant la formation. Ces paramètres sont obtenus en minimisant une fonction de perte $\mathcal{L}$, qui est définie selon le problème à résoudre (voir les exemples dans les pages suivantes sur l’apprentissage supervisé et non supervisé).
Une fois les paramètres fixés par cette phase de formation, la fonction (généralement appelée modèle) peut être utilisée pour faire des prédictions.
Le ML implique généralement des données multidimensionnelles, généralement représentées sous forme matricielle. Un jeu de données d’échantillons $x \in \mathbb{R}^d$ est ainsi représenté comme une matrice $X \in \mathbb{R}^{N \times d}$, où $N$ est le nombre d’échantillons (c’est-à-dire les données disponibles). Les $d$ dimensions de chaque échantillon sont aussi appelées caractéristiques (c’est-à-dire le nombre d’attributs représentant les données).
Avec seulement cette définition, il est déjà clair que le ML est une tâche très difficile, pour au moins les raisons suivantes :
- Le ML est mal posé, dans le sens où il existe de nombreuses solutions possibles pour un problème donné.
- Le ML dépend fortement des données utilisées lors de la phase de formation.
- L’espace d’entrée est typiquement de très haute dimension (par exemple, une image en niveaux de gris de taille 224x224 pixels).
2.2 — Types de ML
Le ML est généralement considéré en trois types principaux (détaillés dans les pages suivantes) :
- Apprentissage supervisé – Apprendre $f$ à partir d’exemples d’entrées $x$ connaissant les sorties correspondantes $y$.
Par exemple, nous avons un jeu de données de photos d’animaux, et les noms correspondants. Nous pouvons entraîner un modèle pour une tâche de classification, en apprenant à prédire “chien” lorsque nous montrons la photo d’un chien.
- Apprentissage non supervisé – Apprendre $f$ à partir d’exemples de $x$ uniquement (inclut aussi “l’apprentissage auto-supervisé”).
Par exemple, nous avons beaucoup de chansons, mais nous n’avons pas les noms et styles des chansons. Nous pouvons apprendre à regrouper les chansons qui partagent le même rythme pour déterminer des groupes cohérents, en utilisant des descripteurs de groove, vibe, etc., basés sur la similarité des chansons. Cela s’appelle le clustering.
- Apprentissage par renforcement – Une forme dynamique d’apprentissage qui considère la fonction $f$ pour naviguer dans un environnement, et reçoit des signaux de récompense en fonction des actions.
Par exemple, dans un labyrinthe PyRat, nous pouvons faire plusieurs parties et apprendre de nos erreurs, afin de faire progressivement mieux dans la partie suivante.
2.3 — Utiliser des caractéristiques pour représenter les données
Une approche classique en ML est de réduire la complexité et la dimensionnalité de l’entrée en extraitant des caractéristiques. L’extraction de caractéristiques peut être réalisée en utilisant des processus prédéfinis tels que :
- Analyse fréquentielle ou temps-fréquence, comme la transformée de Fourier ou la transformée en ondelettes.
- Statistiques, telles que les comptages, moyennes, variances des dimensions individuelles à travers les échantillons.
- Caractéristiques définies par des experts, telles que des filtres spécifiques pour détecter les couleurs ou les contours, ou un prétraitement basé sur des connaissances expertes spécifiques à un domaine.
- Caractéristiques apprises à partir d’une méthode ML préalablement entraînée, comme un modèle fondation entraîné en utilisant deep learning.
Puisque le nombre de caractéristiques est généralement plus petit que la dimension des données, il est beaucoup plus facile d’entraîner un modèle ML à partir des caractéristiques que directement à partir des données. De plus, cela rend la prédiction plus compréhensible du point de vue humain. En effet, si nous prédisons l’espèce d’un arbre uniquement en fonction de sa hauteur, nous savons que la prédiction est liée uniquement à cette caractéristique.
Cependant, notez que les modèles plus récents basés sur l’apprentissage profond ne s’appuient pas sur des caractéristiques personnalisées pour faire des prédictions. Au contraire, ces méthodes supposent que le modèle apprendra de meilleures caractéristiques que celles qu’un humain pourrait produire. Ainsi, ils font directement des prédictions à partir des données, et calculent leurs propres caractéristiques intermédiaires pour préparer leurs décisions.
Ces modèles sont donc moins interprétables, mais surpassent généralement les autres modèles en termes de performance (de loin).
Pour aller plus loin
4 — Idées reçues sur l’IA
Il est important de noter que le terme “IA” est souvent mal utilisé, et sujet à des idées reçues ou des fantasmes, alimentés par la science-fiction, des reportages exagérés ou d’autres événements. Au cœur de ces idées reçues se trouvent des questions philosophiques liées à l’anthropomorphisme (c’est-à-dire le processus de considérer comme humain le comportement d’un agent IA), ou des questions sur la manière dont l’IA peut être considérée comme une vie artificielle ou une conscience. Cela peut conduire à des attentes irréalistes sur ce que l’IA peut accomplir, telles que l’hypothèse qu’elle possède une conscience, une conscience de soi, ou des intentions similaires à celles des humains. Ces questions, bien que philosophiquement intrigantes, ne sont généralement pas le centre d’intérêt de l’informatique et sortent du cadre de ce cours. Pour ceux qui souhaitent explorer ces thèmes, des ressources comme l’article fondamental d’Alan Turing “Computing Machinery and Intelligence” et les travaux de Shannon Vallor sur l’éthique de l’IA fournissent des éclairages fondamentaux.
Ajoutant à la confusion, le débat en cours sur l’Intelligence Artificielle Générale (AGI), le concept théorique de machines capables d’effectuer toute tâche intellectuelle qu’un humain peut faire. L’AGI reste une idée controversée et mal définie, sans consensus parmi les chercheurs sur sa faisabilité, son calendrier, ou même ses caractéristiques fondamentales. Les discussions sur l’AGI deviennent souvent mêlées à des récits globaux sur les risques existentiels, le déplacement d’emplois, et l’avenir de l’humanité, ce qui peut amplifier les peurs et les idées fausses. Ces questions, bien que philosophiquement et socialement significatives, ne sont pas le sujet de ce cours. Pour approfondir l’AGI et ses implications, des ouvrages comme Superintelligence de Nick Bostrom et les critiques d’experts en IA comme Gary Marcus offrent des perspectives variées.
5 — Considérations éthiques
Lorsqu’on parle d’intelligence artificielle (IA), les considérations éthiques sont primordiales. Les sujets clés incluent l’équité, la responsabilité, la transparence, et l’impact sociétal des systèmes d’IA. L’équité garantit que l’IA ne perpétue pas ou n’amplifie pas les biais, tandis que la responsabilité exige une clarté sur qui est responsable des décisions de l’IA. La transparence consiste à rendre les systèmes d’IA compréhensibles pour les utilisateurs et les parties prenantes, et l’impact sociétal considère des conséquences telles que la perte d’emplois ou les préoccupations liées à la vie privée.
Quelques excellentes ressources sur l’éthique de l’IA :
- Weapons of Math Destruction - Kathy O’Neil.
- Playlist Science4all sur l’éthique et les algorithmes (en français).
Concernant la gouvernance, consultez des initiatives comme les Lignes directrices éthiques pour l’IA de la Commission européenne et les ressources du Partnership on AI qui fournissent des cadres pour la conception éthique de l’IA. Pour approfondir, explorez l’AI Now Institute. Ces outils offrent des perspectives pratiques pour intégrer les principes éthiques dans le développement de l’IA.
Pour aller au-delà
- Cours RL par David Silver Lecture 1 Introduction to Reinforcement Learning.
Une bonne introduction à l’apprentissage par renforcement, non couverte dans ce cours. ```