Dijkstra's algorithm
Reading time20 minEn bref
Résumé de l’article
Dans cet article, vous apprendrez comment naviguer dans un graphe pondéré. Vous verrez que les parcours vus précédemment ne peuvent pas être utilisés directement. Nous introduisons donc un autre algorithme de parcours : l’algorithme de Dijkstra.
Points clés
-
L’algorithme de Dijkstra étend le BFS pour effectuer un parcours sur des graphes pondérés.
-
Il trouve le chemin le plus court entre des sommets dans des graphes à poids positifs.
-
En général, il a une complexité de $O(|E| + |V| \cdot log(|V|))$.
Contenu de l’article
1 — Vidéo
Veuillez regarder la vidéo ci-dessous. Vous pouvez également lire les transcriptions si vous préférez.
Bonjour, et bienvenue dans cette leçon sur l’algorithme de Dijkstra ! Cette semaine, nous allons parler des plus courts chemins dans les graphes pondérés. Les algorithmes de parcours de graphe que nous avons déjà vus dans la leçon précédente ne peuvent pas être appliqués directement pour trouver les plus courts chemins dans les graphes pondérés.
Graphe pondéré
Pour illustrer pourquoi les algorithmes de parcours de graphe déjà présentés ne fonctionnent pas nécessairement pour les graphes pondérés, considérez le graphe jouet suivant.
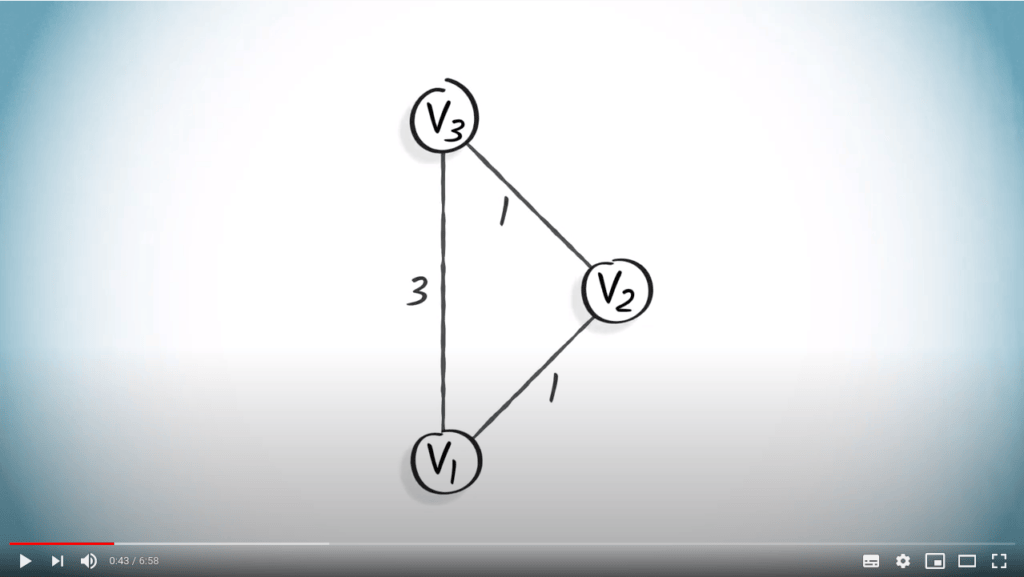
C’est parce qu’un BFS privilégie un plus petit nombre de sauts depuis le sommet initial, indépendamment des poids.
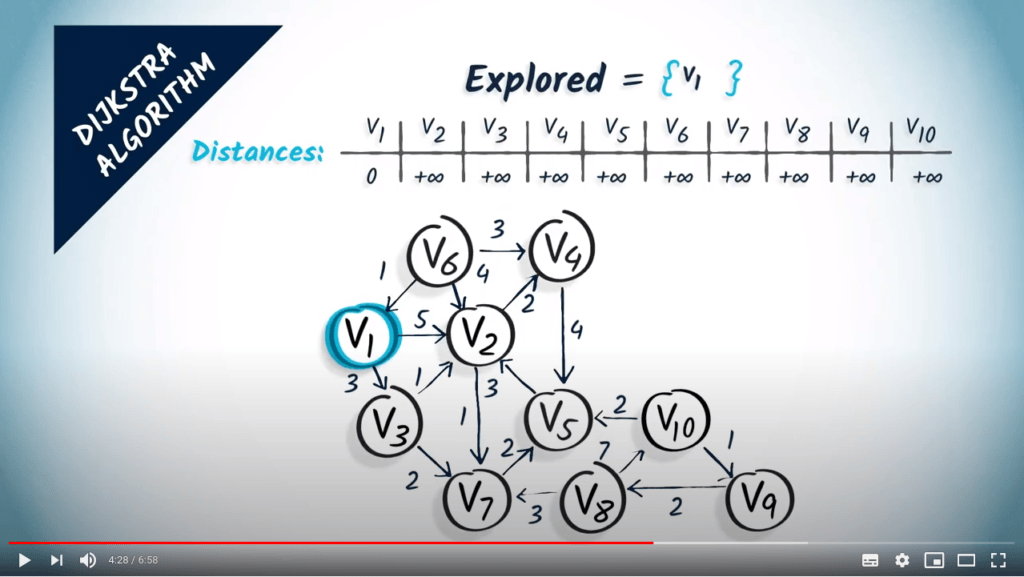
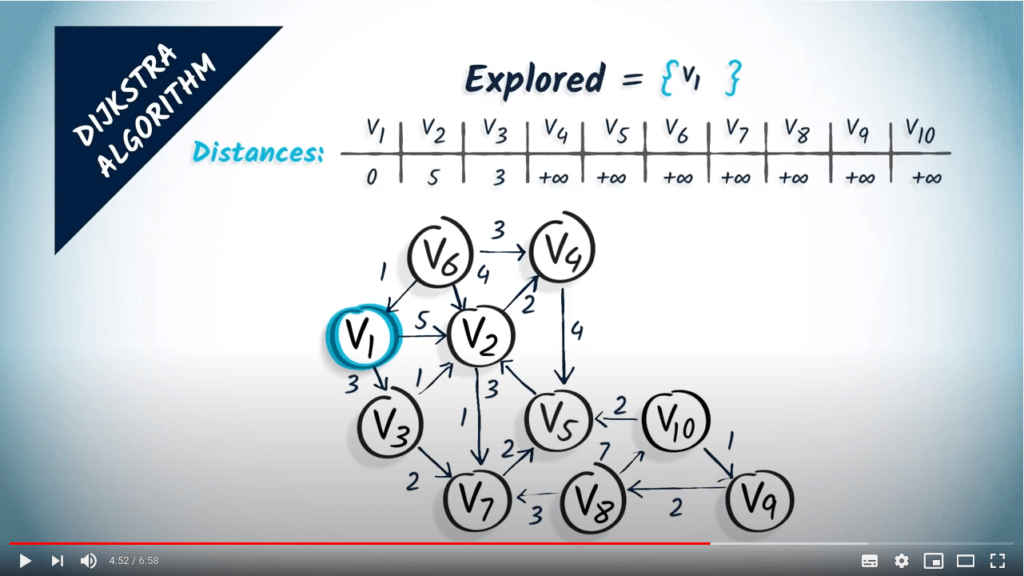
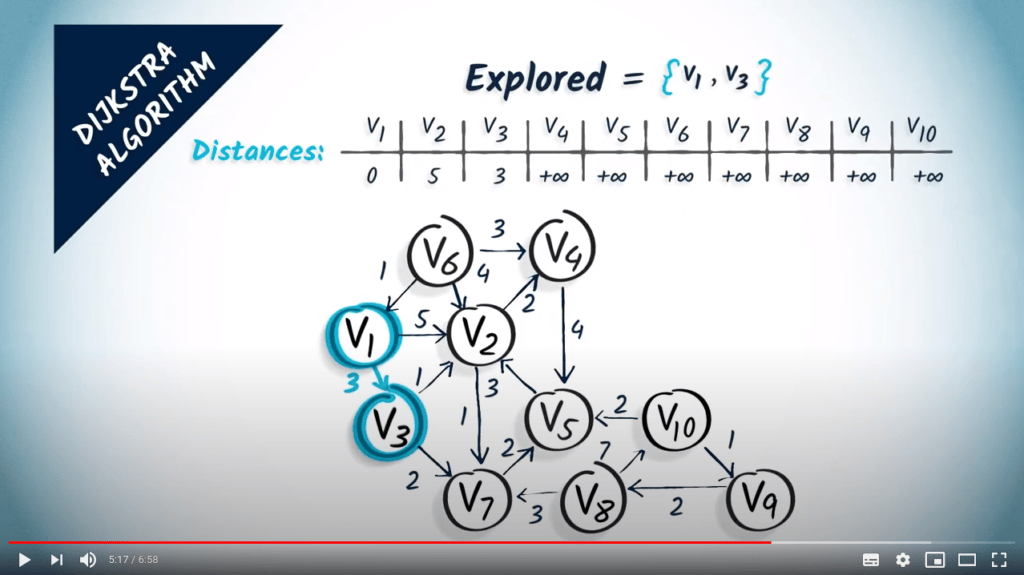
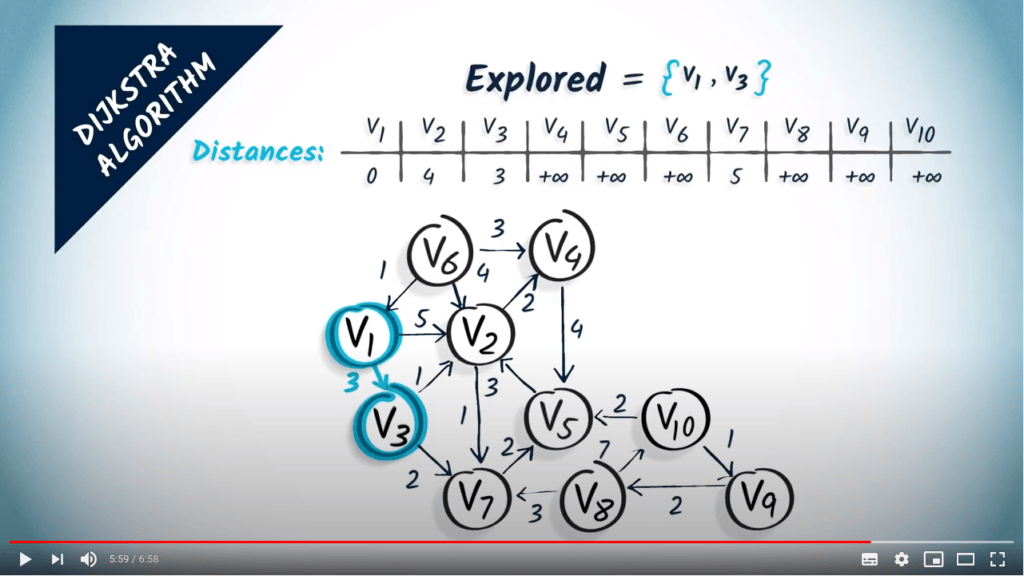
Algorithme de Dijkstra
L’algorithme de Dijkstra est une modification du BFS qui nous permet de trouver les plus courts chemins, même en présence de poids, à condition que ceux-ci soient non négatifs.

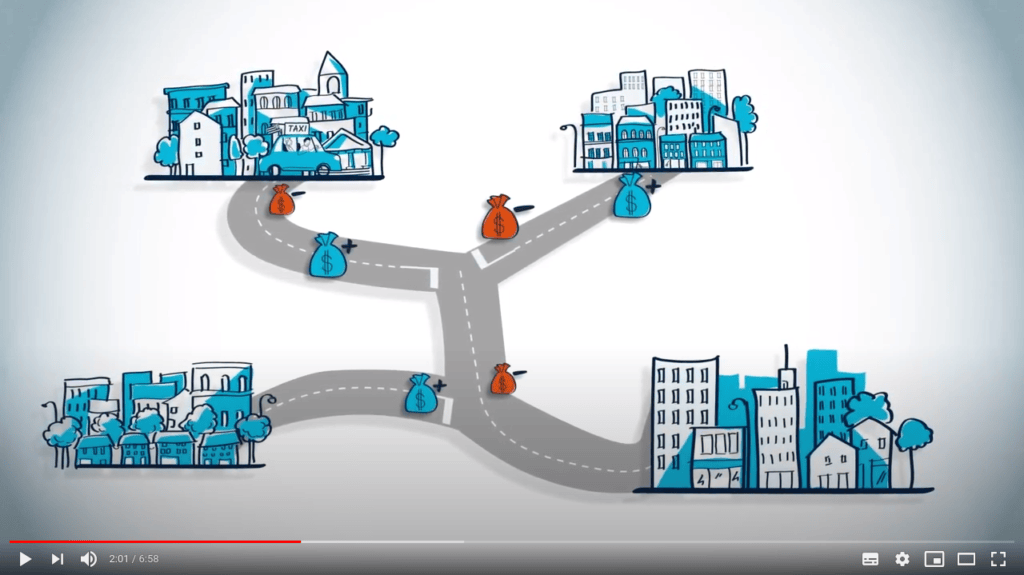
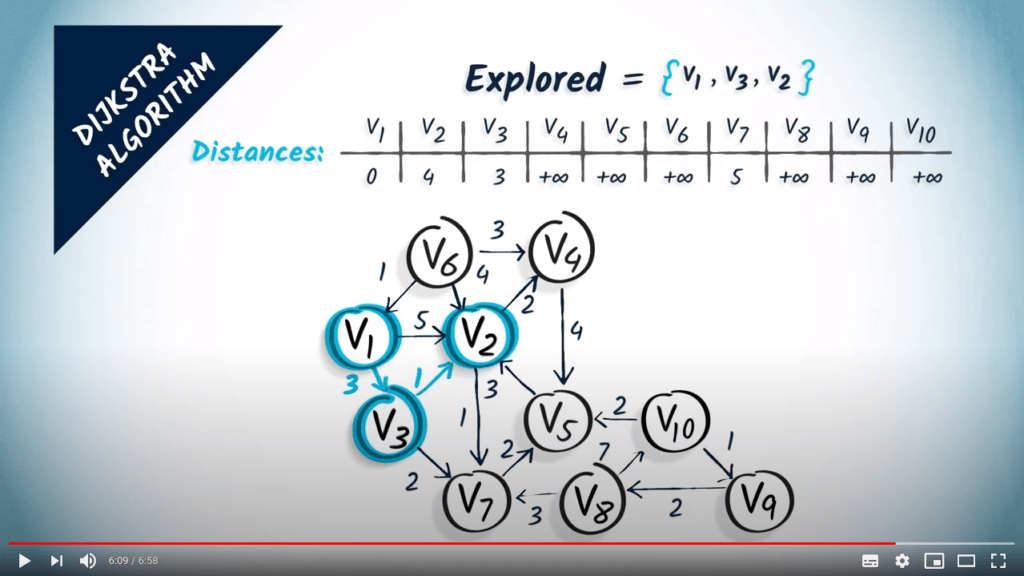
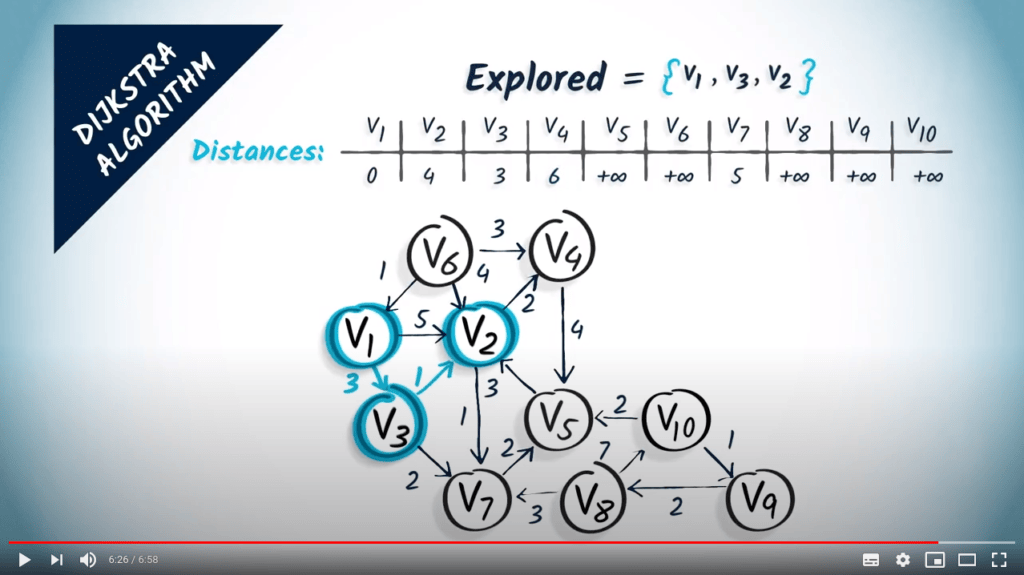
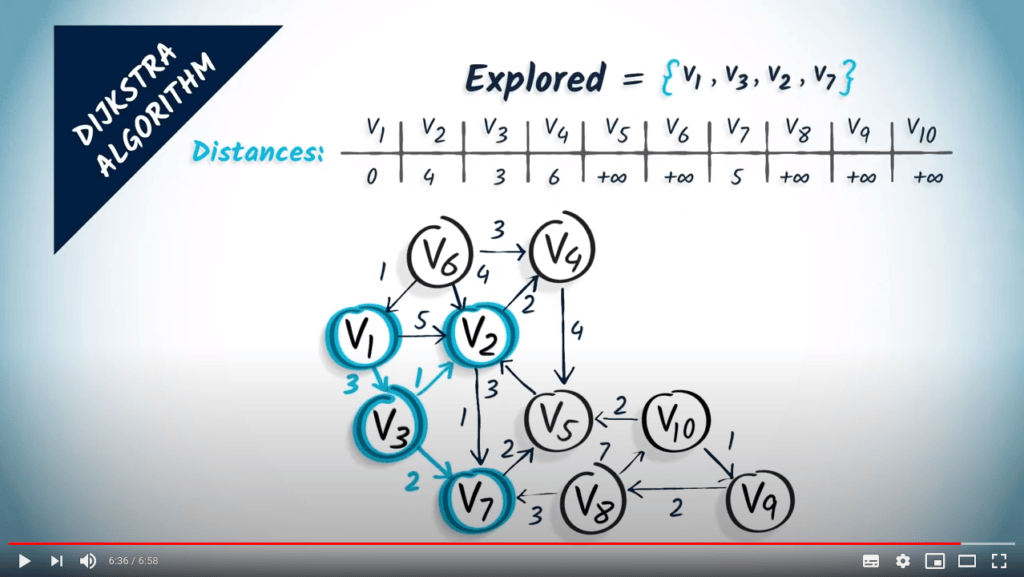
Revenons aux graphes avec des poids non négatifs. La façon la plus simple de décrire l’algorithme de Dijkstra est d’imaginer le sommet de départ comme un robinet d’où coule de l’eau. L’eau progressera le long des sommets et traversera le graphe à une vitesse inversement proportionnelle aux poids des arêtes, donc elle atteindra d’abord les sommets les plus proches.
En d’autres termes, l’algorithme de Dijkstra est un algorithme de parcours dans lequel les sommets sont visités par ordre croissant de distance depuis le sommet initial.


Notez que l’algorithme donne toujours un arbre couvrant des chemins minimum dans le graphe, à condition que les poids soient non négatifs. Nous n’allons pas prouver ce résultat ici, mais ce n’est pas si difficile de faire un très bel exercice si vous souhaitez approfondir un peu plus les concepts décrits dans cette leçon.
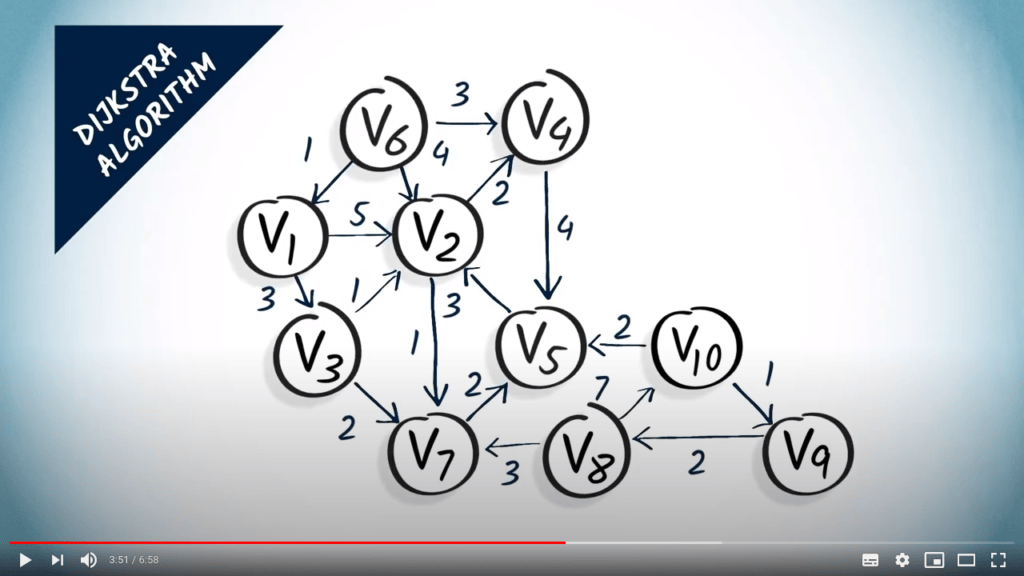
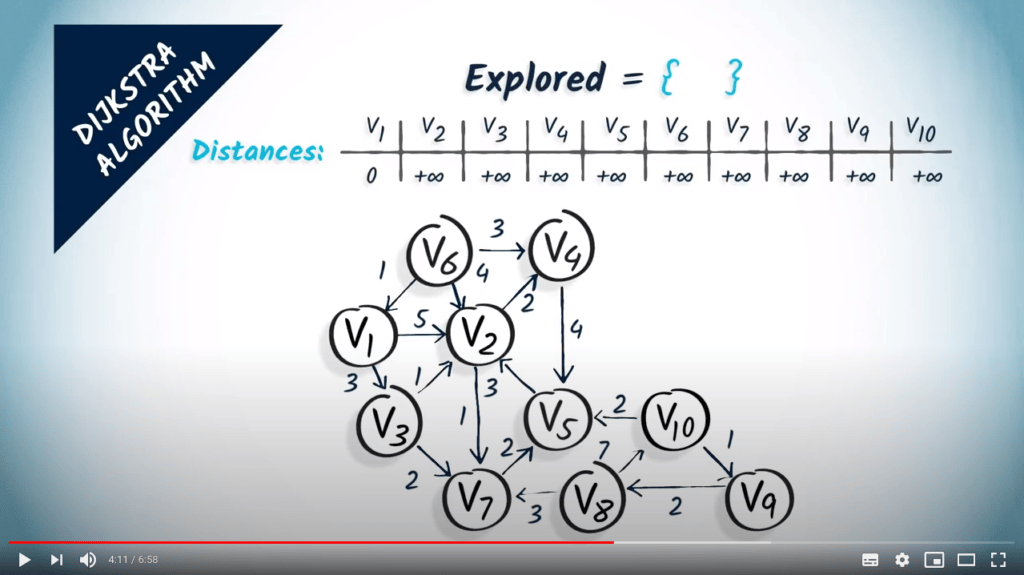

Mots de conclusion
C’est tout pour cette leçon ! Nous verrons ensuite comment implémenter l’algorithme de Dijkstra en utilisant des tas minimum.
Pour aller plus loin
2 — Propriétés de l’algorithme de Dijkstra
2.1 — Terminaison & correction
L’algorithme de Dijkstra se termine et est correct si tous les poids dans le graphe sont strictement positifs.
2.2 — Complexité
La complexité de l’algorithme dépend fortement de la file de priorité utilisée. On peut montrer que la complexité $O(|E| + |V| \cdot log(|V|))$ peut être atteinte en utilisant une structure adaptée.
Dans le cas particulier du labyrinthe sur lequel nous travaillons dans PyRat, chaque sommet a au plus 4 voisins. Nous obtenons donc une complexité de $O(|V| \cdot log(|V|))$, puisque $|E|\leq 4|V|$. Comme cette complexité est inférieure à quadratique, elle est tout à fait raisonnable pour notre problème.
Pour aller plus loin
Une structure de données pour améliorer le temps d’exécution de l’algorithme de Dijkstra.