Introduction au mapping objet-relationnel
Durée2h30Objectifs de l’activité
L’objectif de cette activité est d’introduire les principales notions associées à la persistance des données manipulées par une application Java et de les faire pratiquer en utilisant le fournisseur JPA Eclipse Link. A la fin de cette activité vous serez capables de :
- mettre en place des entités JPA au sein d’une application Java. Ces entités ont une clé primaire et des associations de type 1..N avec d’autres entités
- utiliser les méthodes de base de l’Entity Manager de JPA pour créer, charger et modifier des entités
Connexion à la base de données
Comme mentionné dans l’article d’introduction aux ORM, un ORM doit être capable de :
- se connecter à une base de données relationnelle,
- associer les objets, classes et attributs manipulés par une application avec des lignes, des tables, des colonnes et des contraintes d’une base de données relationnelle et
- produire automatiquement les requêtes SQL relatives aux actions CRUD (Create/Read/Update/Delete) sur les objets et de les engager en base de données.
Dans cette première partie on va étudier comment un ORM peut se connecter à la base de données qui va stocker
les informations manipulées par l’application. Pour ce faire, il faut que le programmeur fournisse, dans un fichier de configuration,
les informations nécessaires à cette connexion. Dans le cas de JPA, c’est le fichier persistence.xml dans src/main/ressources/META-INF (src\main\ressources\META-INF sur Windows)
qui doit contenir cette information. On doit y retrouver notamment l’adresse où se trouve la base de données, et le login et mot de passe que
l’application doit utiliser pour se connecter.
Le fichier de configuration
Ouvrez votre application comrec dans VSCode (Fichier -> Ouvrir le dossier et sélectionnez le répertoire comrec). Trouvez le fichier persistence.xml et analysez son contenu pour retrouver les informations suivantes :
- le nom de la base de données PostgreSQL qui sera utilisée,
- le login utilisé pour accéder à la base,
- le mot de passe correspondant à ce login,
- le mode d’interaction entre l’application et la base de données (propriété
ddl-generation), - le nom des classes Java dont les instances seront « persistées » (on dit qu’elles seront mappées dans la base de données),
- le fournisseur JPA à utiliser.
Concernant le mode d’interaction ddl-generation, quelques précisions sont nécessaires. Ce paramètre indique à JPA comment il doit gérer la base de données lorsque l’application est exécutée :
-
drop-and-create-tables: à chaque démarrage de l’application, le schéma de base de données est recréé à partir de la structure du code. Ce mode est notamment utilisé lors de la phase de test de l’application. -
none: aucun ajustement de la base de données n’est effectué. Ce mode est utilisé en production une fois que l’on est certain que la base de données est conforme au code Java et inversement. -
create-tables: à chaque démarrage de l’application, le schéma de la base de données est comparé à celui de l’application dont le code a pu évoluer. Dans ce cas, la base de données est mise à jour en fonction du code, ce qui est généralement utilisé lors de la phase de développement de l’application.
Toutes ces informations sont regroupées dans un élément <persistence-unit name="comrec-persistence-unit" transaction-type="RESOURCE_LOCAL"> qui les
identifie avec un nom (comrec-persistence-unit).
Question 1
Assurez-vous que les services PostgreSQL et adminer sont démarrés (vous pouvez utiliser l’application Docker Desktop). Allez directement à l’URL d’accès à adminer. Authentifiez-vous (si vous ne l’avez pas encore fait) tel que décrit dans le document prérequis techniques.
Quelles sont les tables de la base ? Quelles sont leur colonnes ? Quelles données elles contiennent ?
Question 2
Lancez l’exécution de l’application. Analysez à nouveau les tables de la base de données ? Y a t’il eu des changements ? Lesquels ?
– OPTIONNEL – Question 3
Changez la valeur de la propriété ddl-generation pourqu’elle soit none. A l’aide de Docker Desktop supprimez le service db et relancez le (docker compose up -d). Analysez les tables de la base de données (nom des colonnes et contenu de la table). Lancez l’application et regardez à nouveau la base. Y a t’il eu des changements ? Lesquels ?
Assurez vous que la valeur de la propriété ddl-generation soit drop-and-create-tables à nouveau. Supprimez le service db et relancez le (docker compose up -d). La base de données est ainsi dans l’état de départ.
Mapping d’une classe
La deuxième fonctionnalité fondamentale d’un ORM est d’associer les objets, classes et attributs manipulés par une application objet avec des lignes, des tables, des colonnes et des contraintes d’une base de données relationnelle. Donc tout fournisseur JPA doit offrir les moyens de faire ces correspondances. Plus concrètement, ce mapping doit faire correspondre :
- une classe (dans le sens programmation) avec une table de la base de données,
- un objet (une instance d’une classe) avec une ligne,
- un attribut d’un objet avec une colonne d’une table de la base de données.
Pour faire ces correspondances en JPA il faut utiliser des annotations.
Une annotation est une forme de métadonnée : elle fournit des données sur un programme mais ne fait pas partie du programme lui-même. Les annotations n'affectent pas directement le code qu'elles annotent, mais elles peuvent être utilisées par le compilateur, les outils de développement ou les environnements d'exécution pour influencer le comportement, générer du code ou fournir des informations supplémentaires. Les annotations en Java sont de la forme `@motClé`. Par exemple, `@Override` est une annotation qui indique que la méthode juste après l'annotation est une méthode héritée de la classe mère.
Mapping classe - table
Dans le jargon JPA, les classes qui doivent être persistées dans une base de données relationnelles sont appelées entités. Pour déclarer une classe comme une entité, il suffit de la précéder de l’annotation @Entity. Ainsi, par exemple, lorsque le code ci-dessous est exécuté par le fournisseur JPA, une table dept sera créée dans la base de données (même nom que la classe) et les instances de cette classe seront persistées comme des tuples (des lignes) de la table.
@Entity
public class Dept {
...
}Lorsqu’on souhaite donner à la table un nom différent de celui de la classe, l’annotation @Table doit être utilisée. Ici, les instances de la classe Dept seront persistées comme des lignes de la table departments.
@Entity
@Table(name = "departments")
public class Dept {
...
}Mapping attribut - colonne
Par défaut, tous les attributs d’une entité sont persistés, le nom de la colonne correspondante dans la base de données étant le même que celui de l’attribut. Pour modifier ce nom, il suffit de précéder l’attribut par l’annotation @Column comme dans le code ci-dessous, où la colonne de la table departments sera dept_no et pas deptnumber.
@Entity
@Table(name = "departments")
public class Dept {
...
@Column(name="dept_no")
private Integer deptNumber;
...
}Question 4
D’après les annotations dans la classe Dept.java fournie, répondez aux questions suivantes :
- quel est le nom de table qui contiendra les instances de la classe ?
- quel est le nom de la colonne correspondant à l’attribut
dName? - modifiez le nom de la colonne correspondant à l’attribut
dName, elle doit s’appelerdept_name
Contraintes de clé primaire
Pour indiquer qu’un attribut doit correspondre à la clé primaire de la table, il faut le précéder de l’annotation @Id. Ainsi, dans le code ci-dessous, la classe Dept a un attribut deptNumber qui correspond à la colonne dept_no qui sera la clé primaire de la table. Les valeurs de la clé dovient par contre être attribuées manuellement lors de l’insertion d’un nouveau tuple (un nouveau département). Cela convient généralement lorsqu’une entité possède un identifiant naturel. Par exemple, un ISBN est attribué à tous les livres publiés. Si nous devions créer un référentiel de livres, nous pourrions l’utiliser comme identifiant et l’attribuer manuellement à chaque livre.
@Entity
@Table(name = "departments")
public class Dept {
...
@Id
@Column(name="dept_no")
private Integer deptNumber;
private String dName;
...
}Pour tout le reste (et c’est, en principe, le cas pour les départements), le fournisseur JPA peut générer automatiquement des valeurs lors de l’insertion de nouvelles entités. Pour ce faire, il faut ajouter l’annotation @GeneratedValue. JPA propose trois stratégies différentes pour générer les valeurs de la clé primaire, vous trouverez ici des informations sur ces stratégies. Dans le code ci-dessous, la stratégie IDENTITY est utilisée : elle génère des entiers de 1 à 231.
@Entity
@Table(name = "departments")
public class Dept {
...
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "dept_no")
private Integer deptNumber;
private String dName;
...
}D’autres éléments d’une entité
Pour que les instances d’une classe puissent être manipulées par JPA il faut en plus deux autres éléments :
- la classe doit contenir un constructeur sans paramètres,
- pour tous les attributs de la classe, elle doit offrir des accesseurs (des getters et des setters). Leur nom doit respecter une syntaxe très précise :
getNomAttribut(setNomAttribut). Par exemple, pour un attributdNameil faut avoir deux méthodes :String getDName()etvoid setDName(String name).
Exercice 1
Ajoutez une classe Emp.java à votre application. Elle représentera les employés d’une entreprise et
sera une entité JPA mappée à une table employees. Pour l’instant la classe doit avoir les attributs suivants :
Integer empnoqui sera la clé primaire de la table dont les valeurs seront générés automatiquement par JPA,String name, mappé dans une colonneename, et qui représente le nom de l’employé,String job, représente le travail fait par l’employé (ANALYST,SALESMAN,MANAGER,CLERK…),Date hiredate, correspond à la date d’embauche de l’employé,float salary, correspond au salaire de l’employé,float commission, il s’agit de dernière commission perçue par l’employé,Emp(String name, String job, Date hiredate, float salary, float commission), un constructeur pour faciliter la création d’objets,String toString(), qui doit donner une description de l’employé de la formeEmp [empno, name, job, hiredate, salary (commission)]
Vérifiez que vous avez bien ajouté la nouvelle entité dans le fichier persistence.xml avant d’exécuter l’application. Quel sont les tables de la base de données après l’exécution de l’application (utilisez adminer pour visualiser le schéma de la base de données) ?
Mapping des associations entre classes
Comme vous le savez déjà, une application objet est constituée d’un ensemble de classes qui sont reliées entre elles par des associations. Pour en tenir compte, JPA définit un ensemble d’annotations dont vous en étudierez ici deux pour introduire les notions principales mais vous pouvez trouver des informations sur les autres annotations ici.
Pour introduire ces annotations, nous allons considérer le schéma conceptuel de la figure ci-dessous. On trouve les classes Dept et Emp sur lesquelles vous avez travaillé jusqu’ici. L’association
work at est une association bidirectionnelle et indique, pour un département, les employés qui y travaillent
et pour un employé, à quel département il est rattaché.
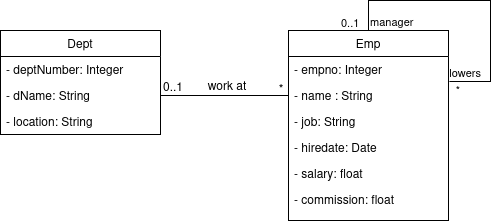
En objet, cette association se traduit par un attribut private Dept dept dans la classe Emp et un autre
private Set<Emp> emps dans la classe Dept. Pour mapper cette association, deux annotations JPA sont nécessaires
(voir le code ci-dessous) :
- @ManyToOne. Elle indique que plusieurs instances d’une
classe (
Empici) peuvent être reliées à la même instance d’une autre classe (Dept). - @OneToMany. Elle indique qu’une instance d’une classe (
Dept) peut être reliée à plusieurs instances d’une autre classe (Emp). Le paramètremappedBy="dept"indique quel attribut de la classeEmpcorrespond à l’association bidirectionnelle (ici l’attributdept).
Ce mapping se traduit par la création, dans la table employees, d’une clé étrangère vers la
table departments. Le nom de la colonne qui correspond à la clé étrangère sera celui de l’attribut (ici dept). Si l’on souhaite
changer ce nom, il suffit d’utiliser l’annotation @JoinColumn. Ainsi, par exemple l’ajout de
l’annotation @JoinColumn(name="dept_fk")permettra de donner le nom dept_fk à la colonne qui est clé étrangère.
@Entity
@Table(name="employees")
public class Emp {
...
@ManyToOne
@JoinColumn(name="dept_fk")
private Dept dept;
...
}@Entity
@Table(name = "departments")
public class Dept {
...
@OneToMany(mappedBy="dept")
private Set<Emp> emps;
...
}Question 5
Modifiez les classes Dept.java et Emp.java pour implémenter l’association work at telle que décrite précédemment
(pensez à ajouter les accesseurs des nouveaux attributs et à modifier la méthode toString qui donne une description de l’instance).
Exécutez l’application et vérifiez que les changements dans les tables de la base de données ont bien eu lieu.
Exercice 2
Modifiez la classe Emp.java pour implémenter l’association manager-lowers. Le nom de la clé étrangère doit être mngr_fk
(à nouveau, pensez à modifier la méthode toString). Vérifiez que les changements dans la table employees ont bien eu
lieu. Quels sont ces changements ?
L’Entity Manager
Les annotations JPA que nous avons vues, ne servent à rien si elles ne sont pas exploitées dans le programme.
Dans JPA, l’interface centrale qui va exploiter ces annotations est la classe EntityManager. À partir d’une instance de cette classe,
un programme peut manipuler les entités afin de les créer, les modifier, les récupérer dans le programme à partir de la base de données ou les supprimer.
Pour cela, la classe EntityManager offre six méthodes (find, persist, merge, detach, refresh et remove). L’instance de l’EntityManager
sur laquelle on exécute ces méthodes prendra en charge la relation des objets avec la base de données et la génération des requêtes SQL nécessaires
en fonction des méthodes appelées.
Le modèle de programmation avec JPA est le suivant. Lorsqu’on souhaite travailler avec des entités :
-
on récupère une instance de l’
EntityManager. Pour cela il faut :- Créer une instance d’une classe particulière (
EntityManagerFactory) en indiquant le nom de l’unité de persistence à utiliser (rappelez vous, le nom a été donné dans le fichierpersistence.xml) :
EntityManagerFactory emf = Persistence.createEntityManagerFactory("comrec-persistence-unit");- Lui demander d’instancier la classe
EntityManager:
EntityManager em = emf.createEntityManager() - Créer une instance d’une classe particulière (
-
on crée un contexte transactionnel, c.-à-d. on ouvre une transaction,
-
on fait les opérations souhaitées sur l’(les) entité(s),
-
on valide ou on annule le contexte transactionnel, c.-à-d. on valide ou annule la transaction.
Cette manière indirecte (sans utiliser explicitement le constructeur d'une classe) de créer des objets est très utilisée en programmation et est appelée "factory design pattern" (patron de conception "fabrique"). Elle permet de rendre le code qui crée un objet, indépendant des détails de la création de cemio-ci. L'utilisation de ce patron de conception dans JPA permet de bien séparer la configuration et initialisation de l'unité de persistance (connexion au SGBDR, "mapping" des entités, etc) faite par le "EntityManagerFactory" des opérations sur les données (requêtes SQL, transactions) assurées par l'instance de la classe "EntityManager".
Le contexte transactionnel
Une transaction est un ensemble d’opérations faites sur des données dans une base de données relationnelles avec la caractéristique
qu’elles seront toutes validées (commit) ou toutes annulées (rollback). Par exemple, le code
ci-dessous correspond à deux requêtes SQL (un insert et un update) faites sur la base de données
avec des départements. Après le commit() un nouveau département sera présent dans la table departments (département dont le nom sera MO) et le département avec dept_no = 1 s’appelera IngMat.
Par contre, si au lieu du commit() on a un rollback(), alors rien ne sera fait dans la base de données (ni l’insertion ni la mise à jour).
begin();
INSERT INTO departments (dname) VALUES ("MO");
UPDATE SET dname = 'IngMat' WHERE dept_no = 1;
commit();Ce mécanisme des transactions est pris en compte dans JPA. Le code ci-dessous montre comment on crée un contexte transactionnel (ouvre une transaction) et comment on valide et annule une transaction.
1. EntityManager em = ... // Instanciation d'un EntityManager
2. em.getTransaction().begin(); // On ouvre une transaction
try {
// Utilisation des méthodes de l'EntityManager
// Si pas d'erreur, on valide la transaction
3. em.getTransaction().commit();
}
catch (RuntimeException e) {
// Si quelque chose se passe mal, alors on annule la transaction
4. em.getTransaction().rollback();
throw e;
}Les entités manipulées dans un contexte trasactionnel via l’EntityManager (c.-à-d. entre les lignes 2. et 3. ou 4.) sont
dites gérées par l’EntityManager, c.-à-d. la valeur des attributs sera synchronisée avec celle de la base de données.
Une fois la transaction validée (ou annulée) les entités sont dites détachées, c.-à-d. leur lien avec la base de données est perdu. Si
d’autres opérations sont à faire sur celles-ci il faudra explicitement les inclure dans le nouveau contexte transactionnel.
Question 6
Complétez le code de la méthode private void createEmployees(EntityManager em) de la classe Main.java. Elle doit permettre de créer trois employés (king, jones et smith) dans la base de données et doit afficher à la fin les employés existant dans la base de données.
Quelques informations pour vous aider à écrire la méthode :
- Pour la date d’embauche, utilisez la classe
SimpleDateFormatde Java. Par exemple, pour un employé embauché le 17/12/80, la ligne à écrire serait :Date hiredate = new SimpleDateFormat("dd-mm-yy").parse("17-12-80"). - Dans un premier temps, aucun employé n’a de manager ni de département d’affectation (valeur
NULLpour ces attributs). - Inspirez vous du code de la méthode
createDepartmentspour écrire le code permettant d’afficher les employées existant dans la base de données.
Une fois la méthode completée, modifiez la méthode main pour que, lorsqu’on sélectionne l’option 2, les méthodes createDepartments et
la nouvelle méthode createEmployees soient exécutées. Vérifiez le bon fonctionnement de la méthode.
Les méthodes de l’Entity Manager
Nous présentons ici une partie des méthodes uniquement, celles dont vous aurez besoin pour le projet de l’UE. Vous trouverez plus de détails sur ces méthodes et toutes les autres ici et ici.
La méthode persist
Comme vous l’avez déjà constatée, elle permet de modifier la base de données pour tenir compte de la création d’une nouvelle entité. Un détail important sur lequel on n’a pas insisté tout à l’heure est l’affectation d’une valeur à l’attribut correspondant à la clé primaire de l’entité. En fonction des annotations utilisées, cette valeur doit être donnée par le SGBDR. Par exemple, dans le code ci-dessous :
- la ligne 1. crée une instance en mémoire de la classe
Dept(aucune opération dans la base de données n’est réalisée). La valeur de l’attributdeptNumberde l’instance seraNULLpuisqu’elle doit être générée par la base de données, - la ligne 2. demande à JPA de créer un nouveau tuple dans la table
departments. L’entité persistée est récupérée dans la variabled, son attributdeptNumberaura donc la valeur de la clé primaire générée par la base de données.
EntityManager em = ... // Instanciation d'un Entity Manager
try{
em.getTransaction.begin(); // Ouverture d'une transaction
1. Dept d = new Dept("Info", "Brest"); // Création en mémoire de l'instance. La valeur de l'attribut deptNumber est null
2. em.persist(d); // Création d'une nouvelle ligne dans la table departments. deptNumber vaut la clé primaire
em.getTransaction().commit(); // Validation de la transaction
} catch (RuntimeException e){
em.getTransaction().rollback(); // Annulation de la transaction si problème
}La méthode find
Elle permet de rechercher une entité dans la base de données en donnant sa clé primaire.
Par exemple, la ligne 1. du code ci-dessous, demande à l’EntityManager de chercher dans la base de données
le département dont la clé primaire vaut 1. Le résultat est une instance de la classe Dept. Puisqu’il s’agit d’une opération
de lecture en base de données (un SELECT), le contexte transactionnel n’est pas obligatoire, il aurait ainsi été possible de ne pas créer de contexte
transactionnel avant d’appeler la méthode find (et donc pas besoin non plus de faire un commit ou un rollback).
EntityManager em = ... // Instanciation d'un Entity Manager
try{
em.getTransaction.begin(); // Ouverture d'une transaction
1. Dept d = em.find(Dept.class, 1);
em.getTransaction().commit(); // Validation de la transaction
System.out.println("Department name " + d.getDName()); // Affiche le nom du département 1
} catch (RuntimeException e){
em.getTransaction().rollback(); // Annulation de la transaction si problème
}
...Question 7
Ajoutez la méthode private void createDepartmentsWithEmployees(EntityManager em) à la classe Main. La méthode doit :
- créer deux départements
RESEARCHàBrestetACCOUNTINGàRennes - cinq employés
KING,JONES,BLAKE,SCOTTetFORD. KINGdoit être le manager deJONESet deBLAKEetJONESdoit être le manager deSCOTTet deFORDKINGetJONEStravaillent dans le départementRESEARCHetBLAKE,SCOTTetFORDdansACCOUNTING.
Pour implémenter cette méthode, vous devrez aussi :
- ajouter une méthode
public void affectEmp(Emp e)à la classeDept.javaqui ajoute le nouvel employéeau département, - ajouter une méthode
public void addLower(Emp e)à la classeEmp.javaqui ajoute un nouveau collaborateureà l’employé.
Modifiez la méthode main de la classe Main.java pour qu’elle soit appelée lorsqu’on sélectionne l’option 3.
Vérifiez que les données ont bien été insérées dans la base de données.
Question 8
Modifiez l’application pour qu’elle permette de trouver les collaborateurs d’un employé donné. Pour cela :
- Créez une methode
private Emp findEmployee(EntityManager em, Integer empno)dans la classeMain.javaqui rend l’employé dont la clé primaire vautempno, - Créez une méthode
private Set<Emp> findCollaborators(Entitymanager em, Emp emp)dans la classeMain.javaqui rend l’ensemble de collaborateurs de l’employéemp - Utilisez ces méthodes pour trouver les collaborateurs de l’employé
1lorsque l’utilisateur choisi l’option4.
La méthode merge
Cette méthode est parfois considérée comme la méthode permettant de réaliser les UPDATE des entités en base de données.
Il n’en est rien et la sémantique de la méthode merge est très différente : elle attache une entité à l’EntityManager ;
l’entité fera, après le merge, à nouveau partie des entités gérées par l’EntityManager et donc la valeur des attributs sera synchronisée avec celle des colonnes correspondantes dans la base de données.
Le code ci-dessous montre un exemple typique d’utilisation de cette méthode. L’entité d est récupérée
de la base de données (ligne 1.) et on souhaite faire des opérations sur cette entité, par exemple changer le nom
du département. Puisqu’il s’agit d’une opération de modification, on crée une transaction (ligne 2.), on modifie
l’objet en mémoire (ligne 3.) et on demande à valider la transaction (ligne 4.). Le résultat est néanmoins
une exception de type Entity not Managed puisque l’entité d ne fait pas partie des entités gérées par l’EntityManager
au moment du commit.
EntityManager em = ... // Instanciation d'un Entity Manager
1. Dept d = em.find(Dept.class, 1) // Recherche du département `1` dans la base de données. Pas de contexte transactionnel explicitement
try{
2. em.getTransaction.begin(); // Ouverture d'une transaction
3. d.setName("MARKETING"); // Modification du nom du département en mémoire
4. em.getTransaction().commit(); // Validation de la transaction
} catch(RuntimeException e){
em.getTransaction().rollback(); // Annulation de la transaction si problème
}
...Une solution au problème est d’appeler la méthode merge pour rattacher l’instance au nouveau contexte
transactionnel (ligne 3.). Ainsi, lors du commit, l’EntityManager pourra répercuter les modifications
dans la base de données puisque d fait partie des entités qu’il gère.
EntityManager em = ... // Instanciation d'un Entity Manager
1. Dept d = em.find(Dept.class, 1) // Recherche du département `1` dans la base de données
try{
2. em.getTransaction.begin(); // Ouverture d'une transaction
3. em.merge(d);
4. d.setName("MARKETING"); // Modification du nom du département en mémoire
5. em.getTransaction().commit(); // Validation de la transaction
} catch(RuntimeException e){
em.getTransaction().rollback(); // Annulation de la transaction si problème
}
...Question 9
Modifiez l’application pour qu’elle permette d’affecter une commission (un montant) aux collaborateurs d’un employé donné. Pour cela :
- Créez une methode
void affectCommission(EntityManager em, Set<Emp> collaborators, float totalCommission)qui distribue le montanttotalCommissionentre les employéscollaborators. La distribution de la commission sera proportionnelle au salaire de l’employé - Utilisez la nouvelle méthode et celles créées dans la question précédente pour distributer une commission de
10000euros parmi les collaborateurs de l’employé1lorsque l’utilisateur choisi l’option5.