A broad introduction to Deep Learning
Reading time10 minEn bref
Résumé de l’article
Dans cette page, nous donnons un aperçu très large du Deep Learning (DL), un type particulièrement réussi de méthodes d’apprentissage automatique. Le DL est entraîné en utilisant la différentiation automatique d’un grand nombre de composants simples appelés “couches”, directement à partir de données brutes.
Principaux points à retenir
-
Le DL est une famille de méthodes d’apprentissage automatique.
-
Le DL est basé sur des compositions de fonctions simples appelées couches.
-
Le DL est appris de bout en bout à partir de données brutes, avec peu ou pas de prétraitement. L’extraction des caractéristiques est réalisée par l’approche DL.
-
Les approches DL sont entraînées en utilisant la différentiation automatique.
Contenu de l’article
1 — Généralités sur le deep learning
Le Deep Learning est un ensemble de techniques qui sont un cas particulier de ML, et qui sont particulièrement efficaces pour traiter plusieurs types de données, telles que les images, le langage, l’audio, ainsi que des domaines plus scientifiques comme la biologie ou la physique (voir des exemples plus spécifiques dans la page sur les applications). En conséquence, le Deep Learning a permis un progrès rapide du ML et de l’IA dans son ensemble, et à ce jour (2024) est le paradigme dominant dans la plupart des tâches d’IA.
Le Deep Learning repose sur trois ingrédients :
-
Compositionalité – La fonction $f$ est estimée comme un assemblage de fonctions simples avec peu de paramètres (généralement, une combinaison linéaire de toutes les dimensions d’entrée, suivie de fonctions non linéaires), qui sont généralement appelées couches.
-
Apprentissage de bout en bout – L’extraction des caractéristiques est effectuée par les fonctions apprises (par opposition aux caractéristiques “définies par des experts”).
-
Différentiation automatique – Toutes les fonctions sont entraînées simultanément en calculant les gradients des sorties de toutes les couches en utilisant la descente de gradient (stochastique), par un algorithme appelé “rétropropagation des gradients”.
2 — Architectures modernes pour le deep learning
Nous présenterons ici les architectures les plus utiles dans les pratiques actuelles du DL. Si vous êtes intéressé par une perspective historique, il y a eu de nombreux développements et architectures proposées que vous trouverez dans la section pour aller plus loin ci-dessous.
Les types de fonctions qui peuvent être combinées (ou “couches”) sont assez divers. Dans cette section, nous présentons uniquement les plus courantes.
Dans chaque couche, les combinaisons linéaires sont souvent suivies d’un terme de biais pour ajuster la valeur, avant d’appliquer une fonction non linéaire, telle que la fonction sigmoïde, ou la “rectified linear unit” (ReLU). La ReLU est le maximum entre 0 et la valeur d’entrée.
2.1 — Couches entièrement connectées
Les couches entièrement connectées considèrent une cascade de couches pour lesquelles chaque couche est calculée avec une combinaison linéaire de toutes les dimensions de la couche précédente. Par exemple, voici un exemple composé de $L$ couches.
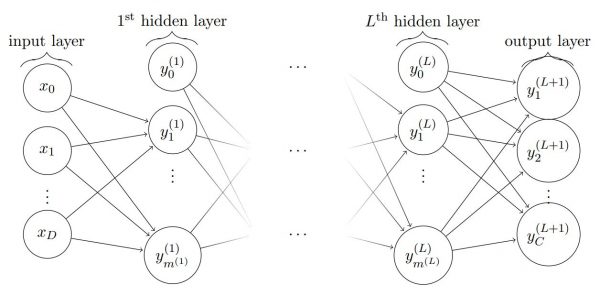
Les modèles qui incluent uniquement de telles couches sont généralement appelés perceptrons multicouches (MLP). Cependant, ces couches apparaissent souvent dans d’autres types de modèles.
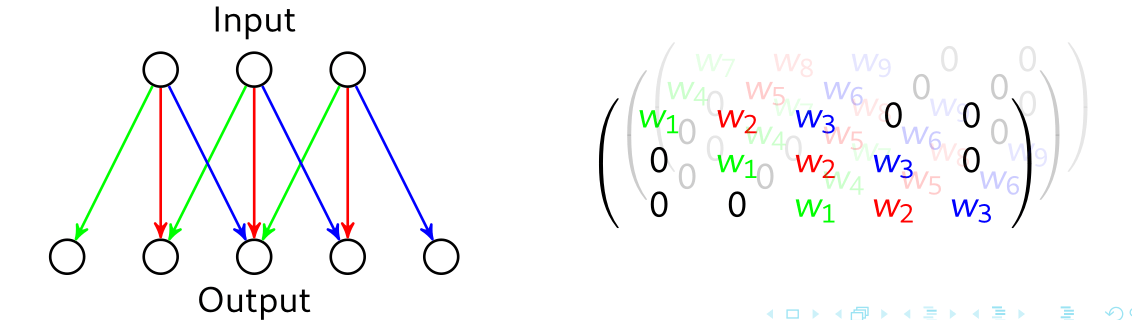
2.2 — Réseaux de neurones convolutionnels (CNN)
Les CNN considèrent que les poids peuvent être partagés entre plusieurs dimensions d’entrée. Cela est particulièrement pertinent avec des données qui présentent des régularités dans leur structure, telles que les images ou l’audio. Les CNN sont basés sur le traitement classique du signal qui utilise un petit ensemble de valeurs, défini comme un noyau, pour traiter une grande entrée.
Dans le cas 2D, une couche convolutionnelle 3x3 (composée de plusieurs noyaux 3x3) peut être représentée comme :
Avec une image en entrée, cela correspondra à la structure suivante (source) :
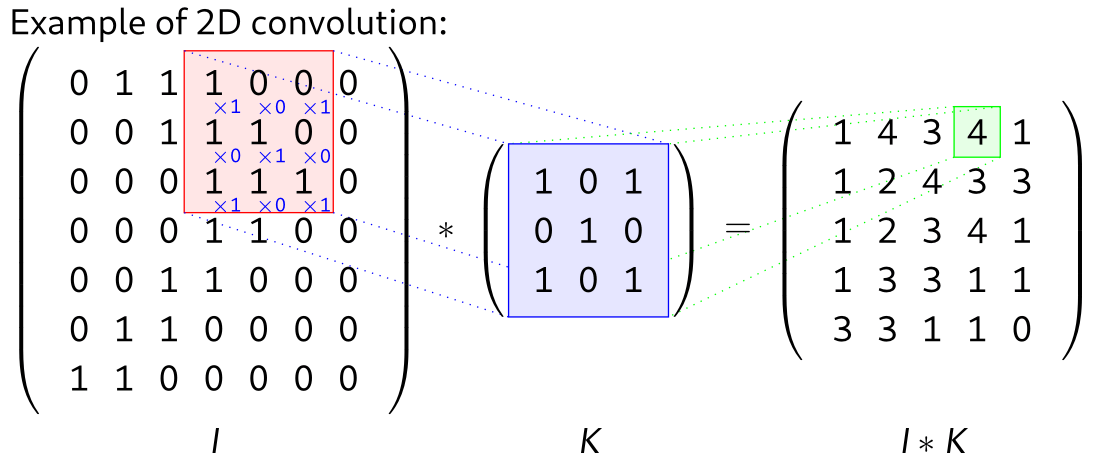
Une couche convolutionnelle dans un CNN est typiquement composée de plusieurs (jusqu’à quelques centaines) noyaux, qui sont recombinés pour produire une sortie. Les CNN ont été l’état de l’art en vision par ordinateur pendant de nombreuses années, et sont encore utilisés en 2024, parfois combinés avec d’autres types de couches telles que les Transformers.
Pour aller plus loin
3 — Transformers
Les Transformers sont la dernière grande innovation dans le domaine du deep learning, et ont permis un progrès très rapide dans les applications linguistiques. Les Transformers sont à la base de la plupart des grands modèles de langage (LLM) (ils sont le T dans GPT : “Generative Pretrained Transformer”).
Un aperçu du fonctionnement des transformers peut être trouvé ici.
4 — Apprentissage auto-supervisé
Il est possible d’entraîner de grands modèles de deep learning en exploitant des manipulations simples sur les données d’entrée, sans avoir besoin d’étiquettes. Cela s’appelle l’apprentissage auto-supervisé.
Il y a deux paradigmes principaux :
-
Masquage / auto-prédiction – L’idée est de masquer certaines parties de l’entrée et de prédire les parties restantes.
Par exemple, pour le texte :
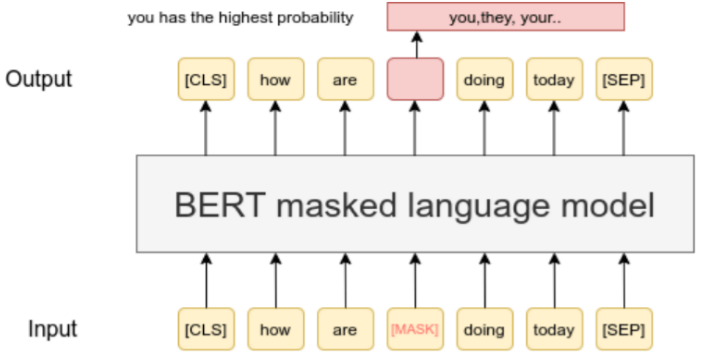 Par exemple, pour les images :
Par exemple, pour les images :
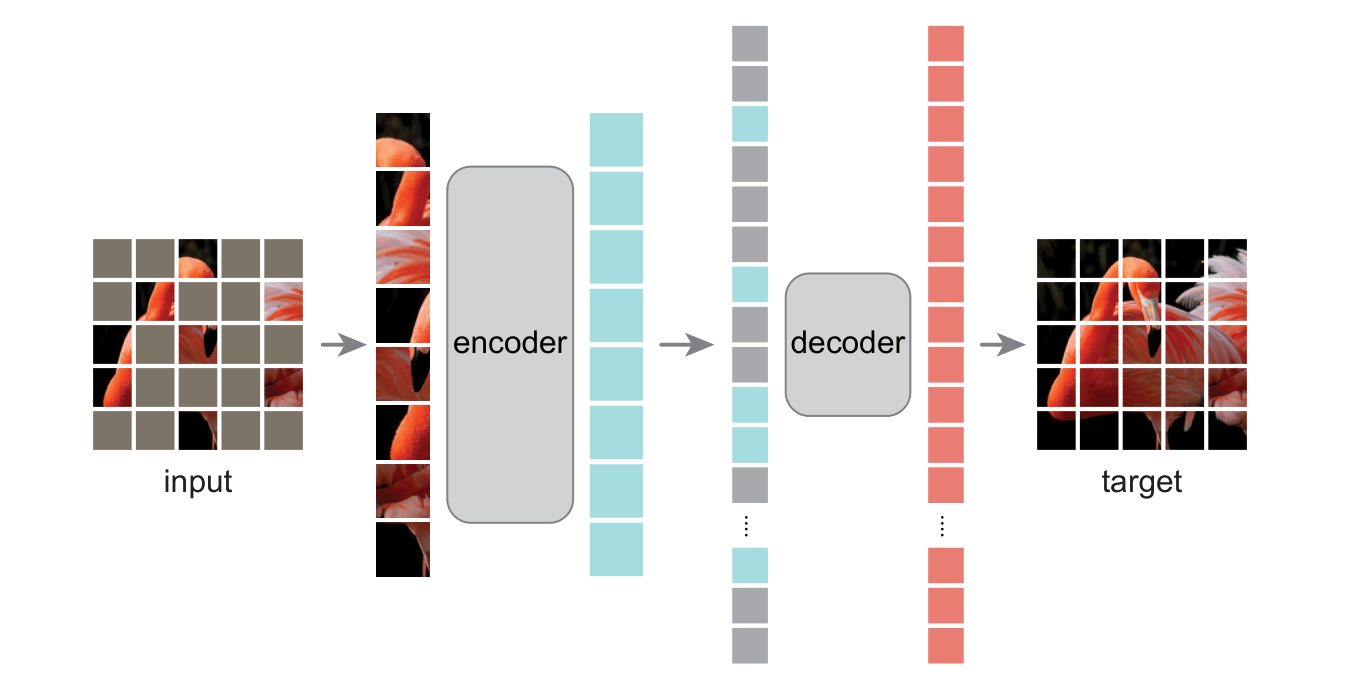
-
Apprentissage contrastif – L’idée est de générer plusieurs versions de la même donnée d’entrée (par exemple, des images), en utilisant des transformations simples :
Par exemple,

La similarité entre les différentes “vues” peut être combinée pour entraîner un extracteur de caractéristiques deep learning, par exemple en utilisant l’algorithme SimCLR (image également empruntée à l’article SimCLR).
Pour aller plus loin
-
Une série de vidéos de conférences par certains de vos enseignants sur les modèles de fondation, de très grands modèles entraînés sur des jeux de données à l’échelle d’internet.
-
Un livre orienté pratique avec des exemples de code et des exercices, couvrant le deep learning dès le début.
-
Un peu daté, mais les 9 premiers chapitres valent toujours la peine d’être lus si vous êtes intéressé par les détails.
-
The Ultimate Guide to Semi-Supervised Learning.
Les modèles d’IA modernes sont entraînés avec l’apprentissage semi-supervisé lorsque beaucoup de données non étiquetées sont disponibles.