Graph traversal
Reading time25 minEn bref
Résumé de l’article
Dans cet article, vous apprendrez comment naviguer dans un graphe, en utilisant des algorithmes appelés parcours.
Principaux points à retenir
-
Un parcours de graphe explore un graphe sommet après sommet, pour construire un arbre couvrant du graphe.
-
La recherche en profondeur (DFS) va aussi loin que possible puis revient en arrière lorsqu’elle est bloquée.
-
La recherche en largeur (BFS) explore les sommets par ordre croissant de distance depuis le départ.
-
BFS trouve le chemin le plus court dans un graphe non pondéré.
-
La terminaison, la correction et la complexité sont des notions importantes pour évaluer un algorithme.
-
BFS et DFS ont une complexité de $O(n)$.
Contenu de l’article
1 — Vidéo
Veuillez consulter la vidéo ci-dessous. Vous pouvez également lire la transcription si vous préférez.
Bonjour ! Et bienvenue dans cette leçon sur le parcours de graphe.

Dans de nombreux cas, nous nous intéressons à l’accessibilité. L’accessibilité consiste à trouver comment atteindre un sommet cible depuis un sommet initial, en suivant un chemin dans le graphe. Pour obtenir les chemins du sommet initial à tous les sommets accessibles, je vais vous montrer comment construire un arbre, obtenu à partir du graphe initial, qui transmettra juste assez d’informations pour nous guider vers n’importe quel sommet accessible depuis le sommet initial.
Voisins et arbres couvrants
Rappelons qu’un graphe est un couple $G$ composé d’un ensemble de sommets $V$ et d’un ensemble d’arêtes $E$. Nous devons maintenant définir quelques notions supplémentaires.
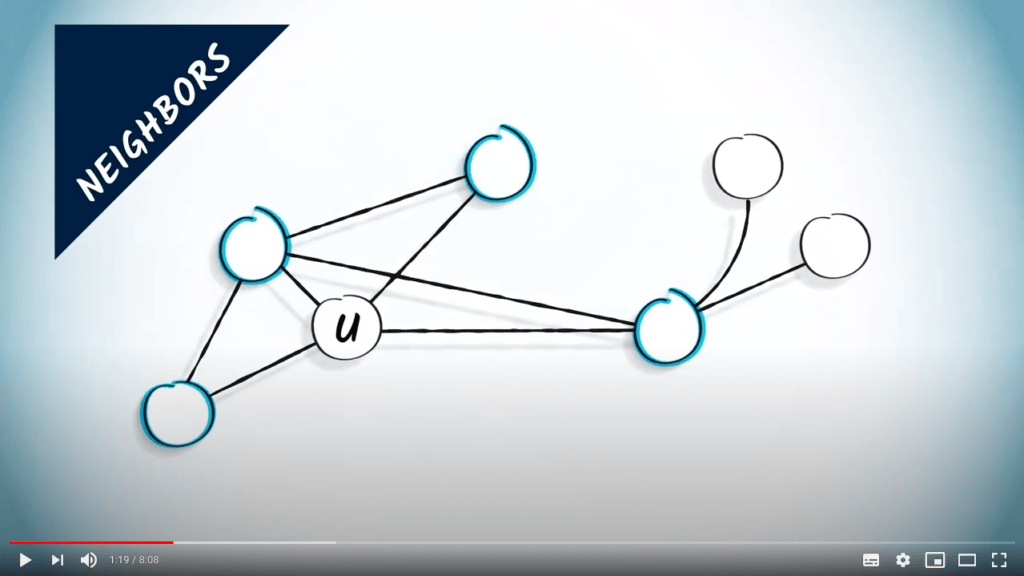
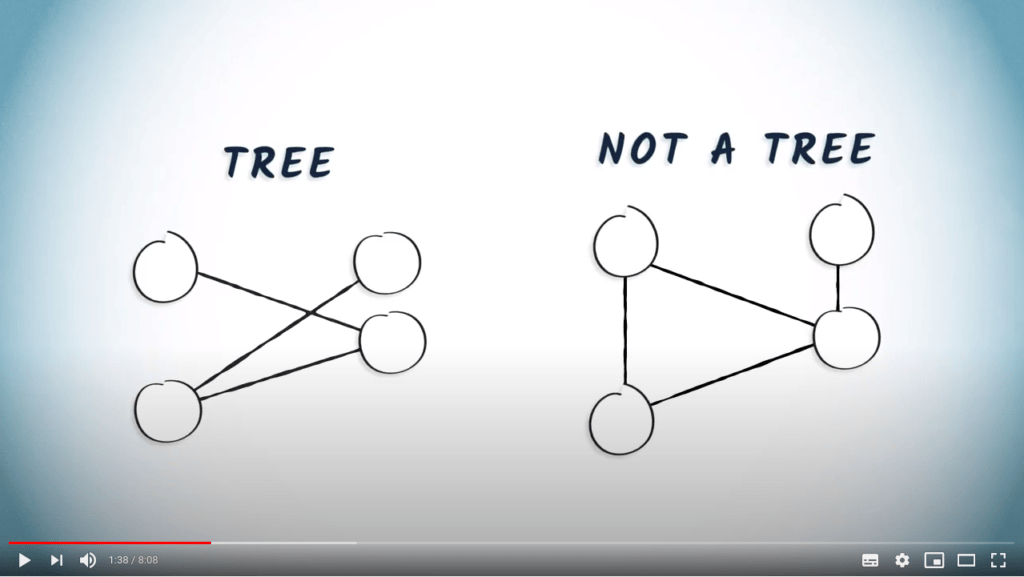
Comme nous l’avons vu dans la leçon précédente, un arbre est un graphe connexe sans cycles.
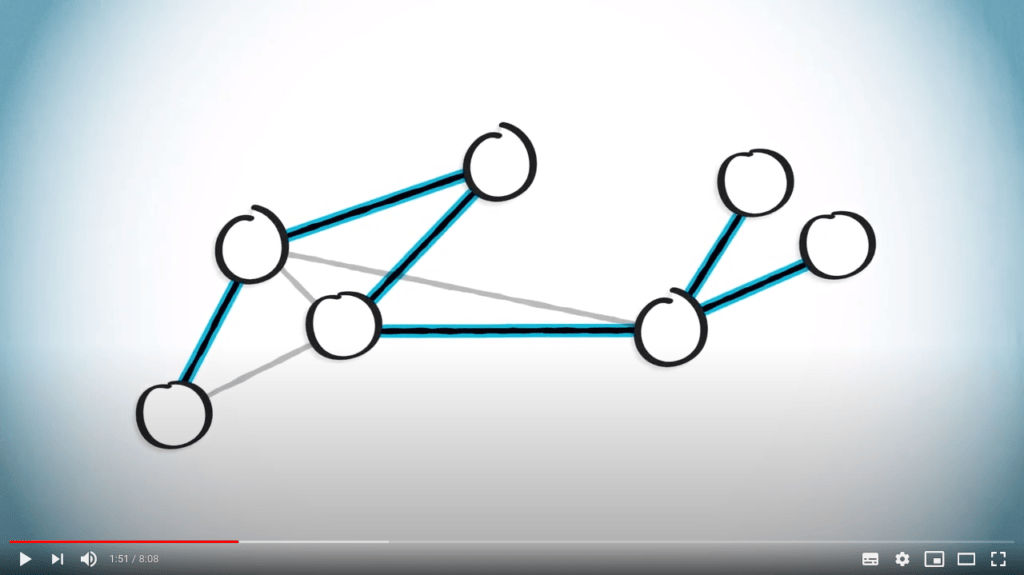
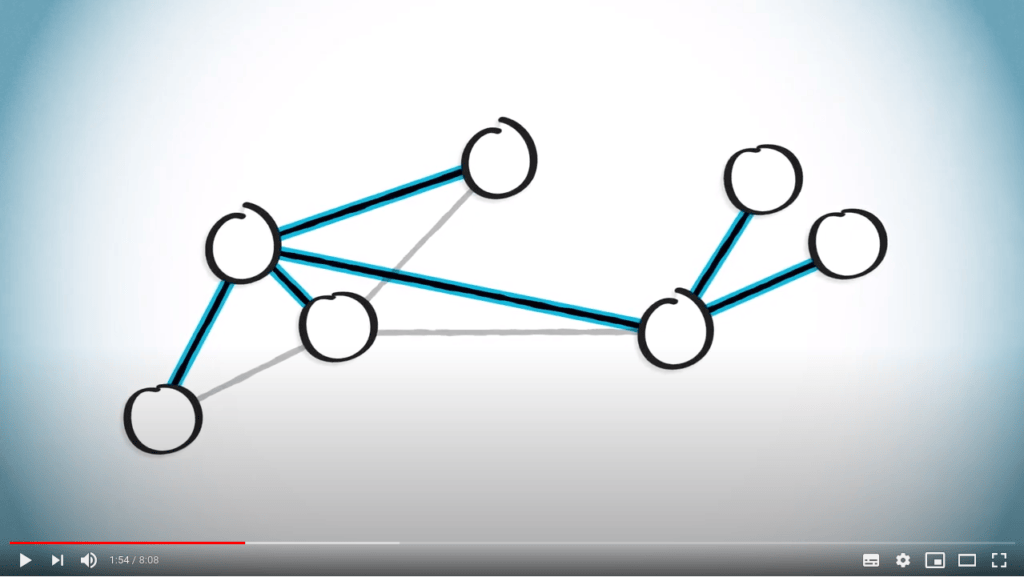
Dans cette leçon, nous allons voir comment trouver un chemin entre deux sommets d’un graphe connexe, afin de pouvoir naviguer entre n’importe quels deux points.
Par définition, un arbre couvrant inclura exactement un chemin entre ces deux points.
Nous comparerons deux approches : la recherche en profondeur et la recherche en largeur.
Recherche en profondeur
L’idée principale d’une recherche en profondeur est de continuer à explorer le graphe, en sautant d’un sommet donné à l’un de ses voisins non explorés. Parfois, tous les voisins du sommet où nous sommes ont déjà été explorés, auquel cas nous revenons en arrière, suivant la trace dans la direction opposée jusqu’à trouver un sommet non exploré vers lequel sauter.
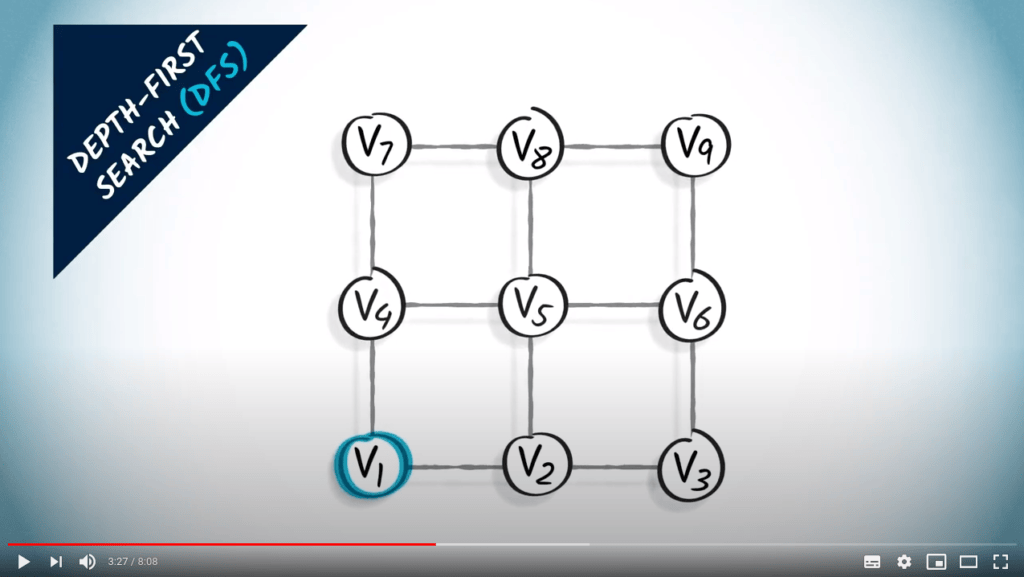
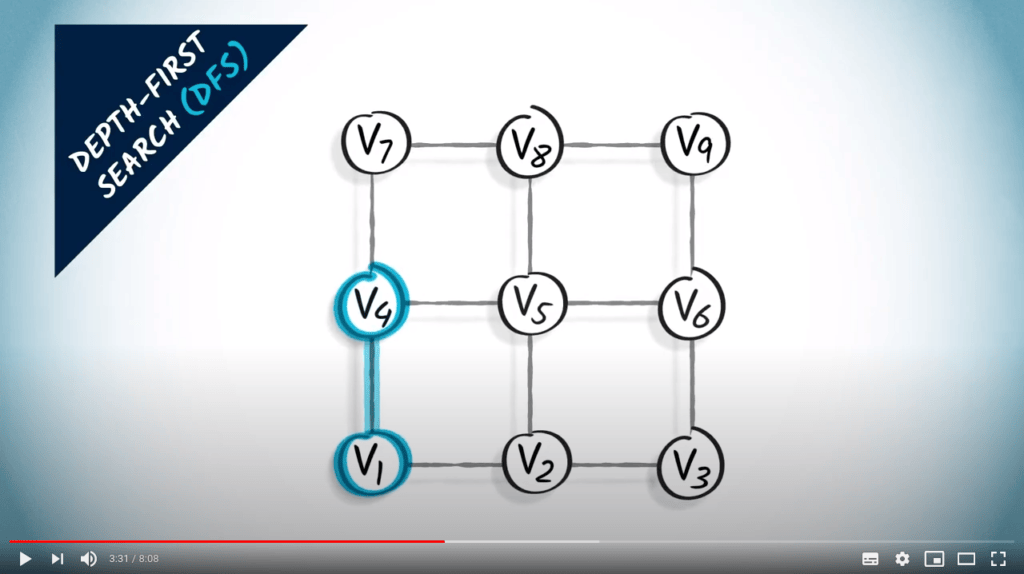
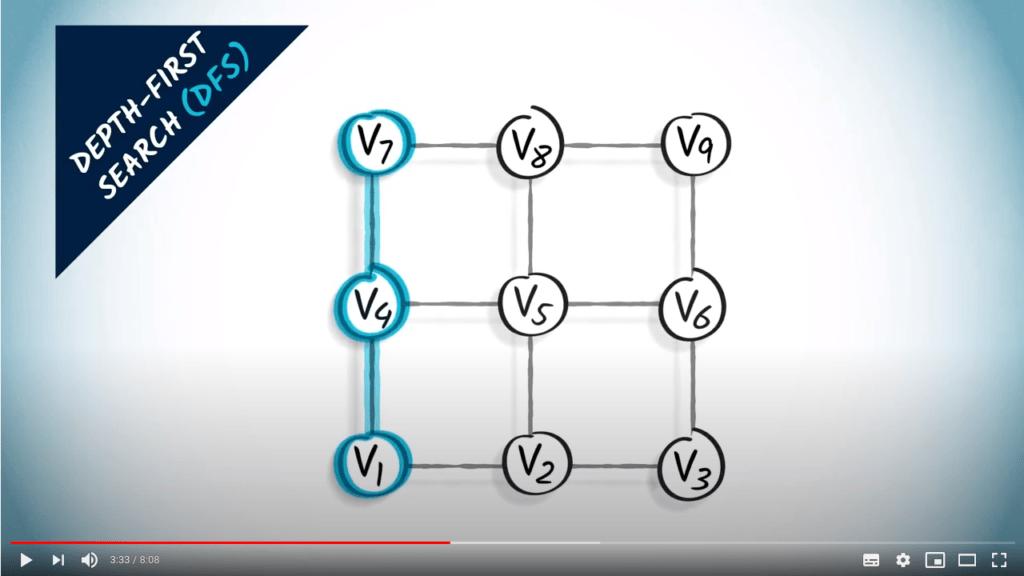
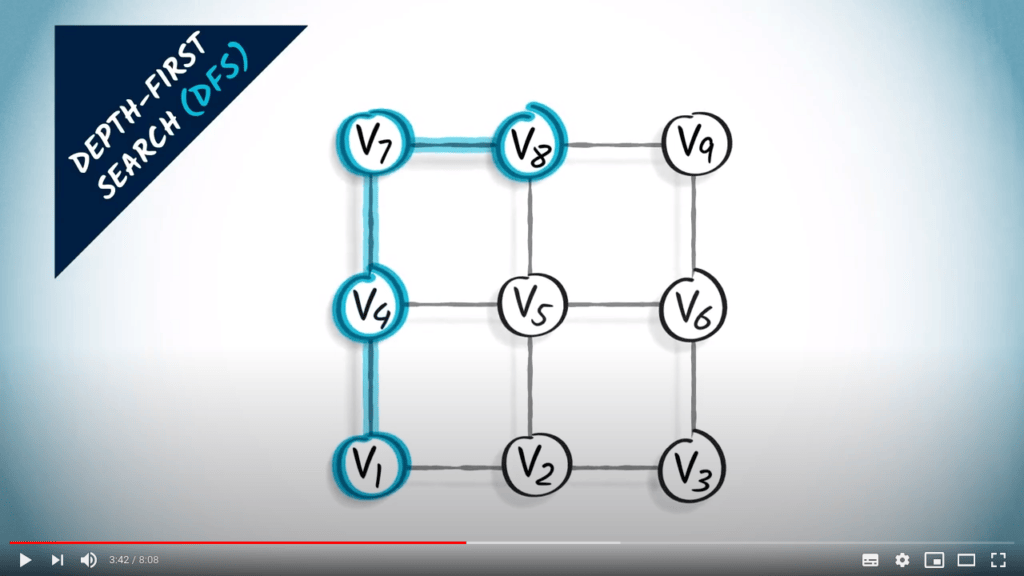
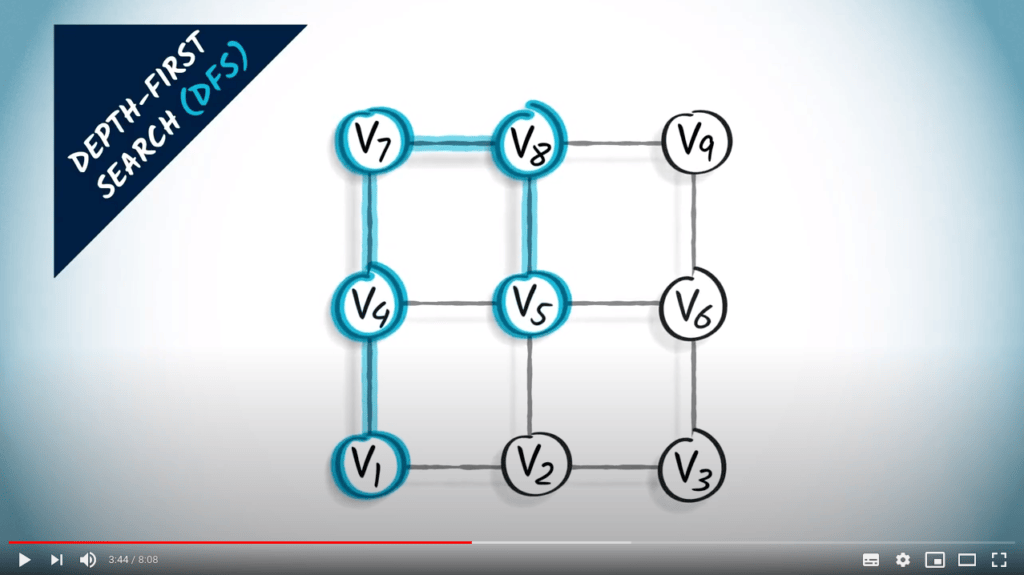
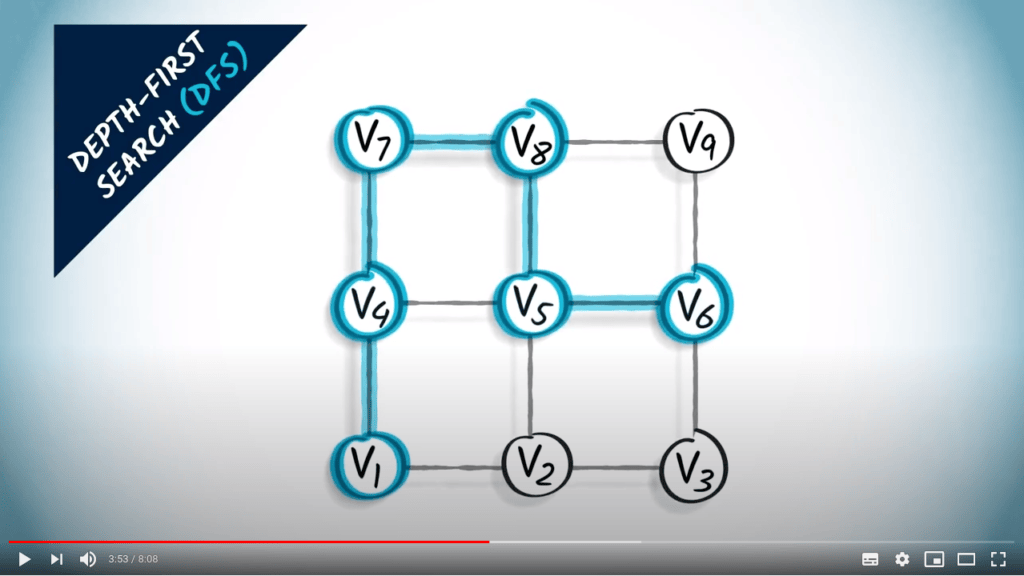
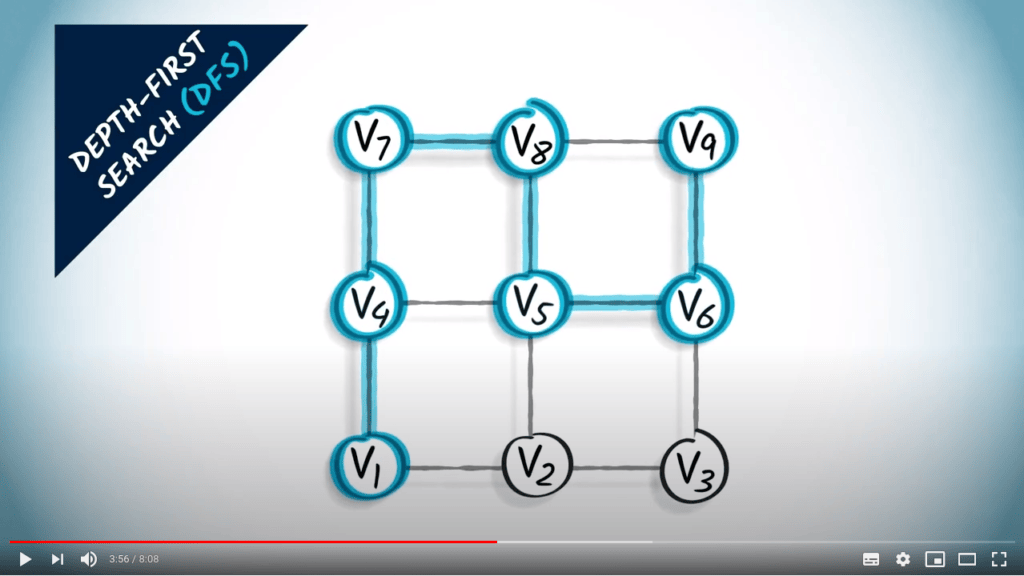
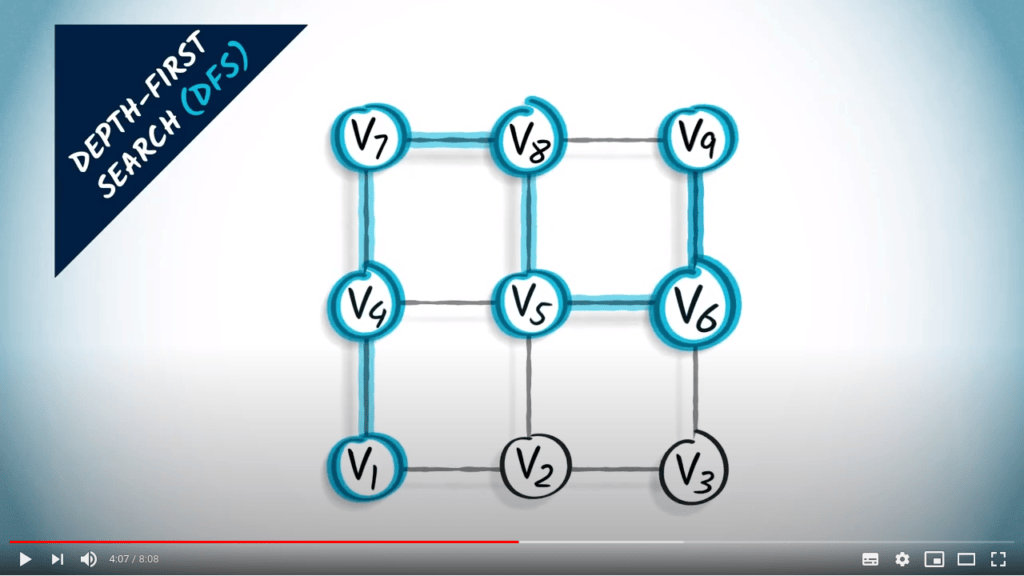
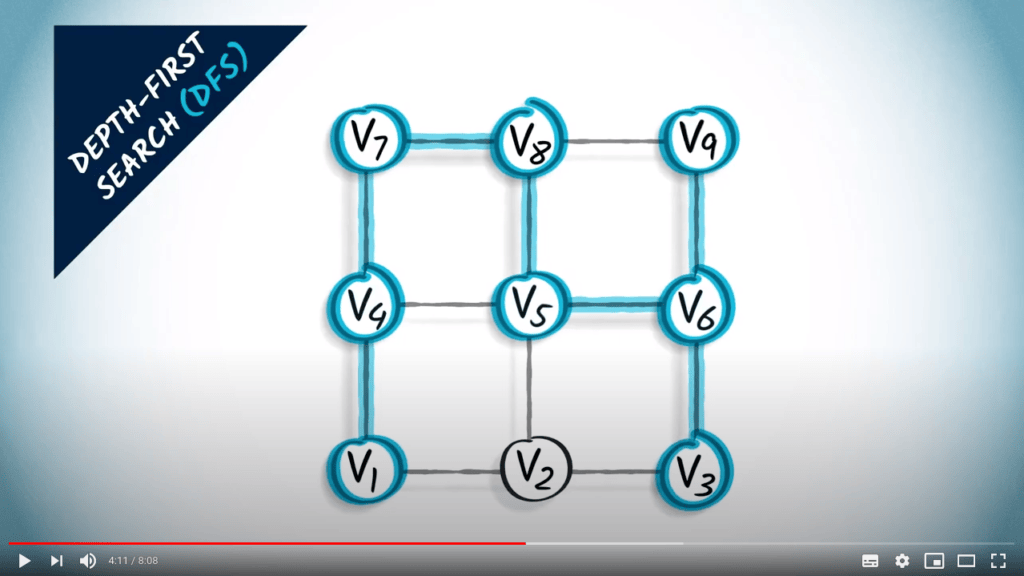
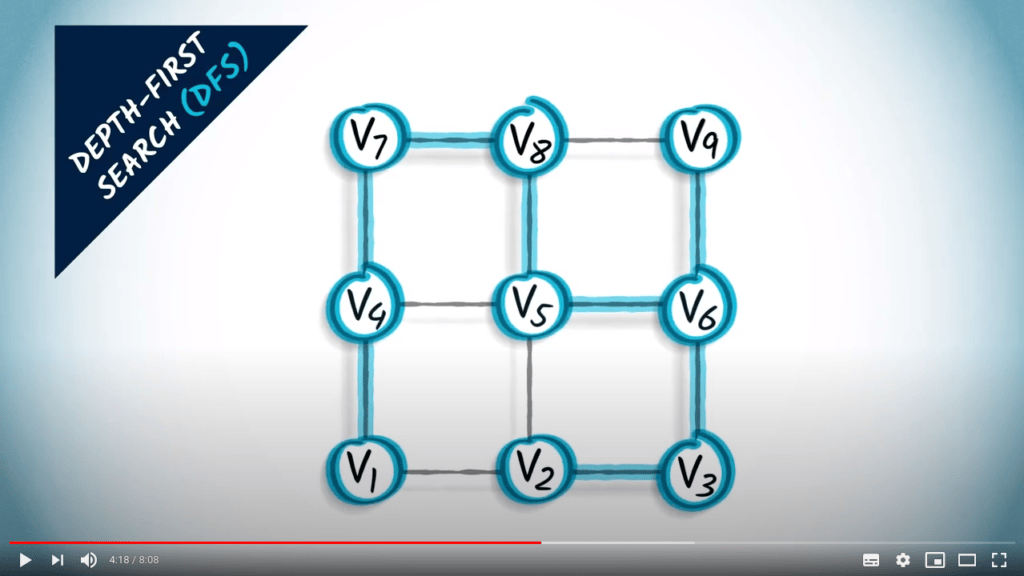
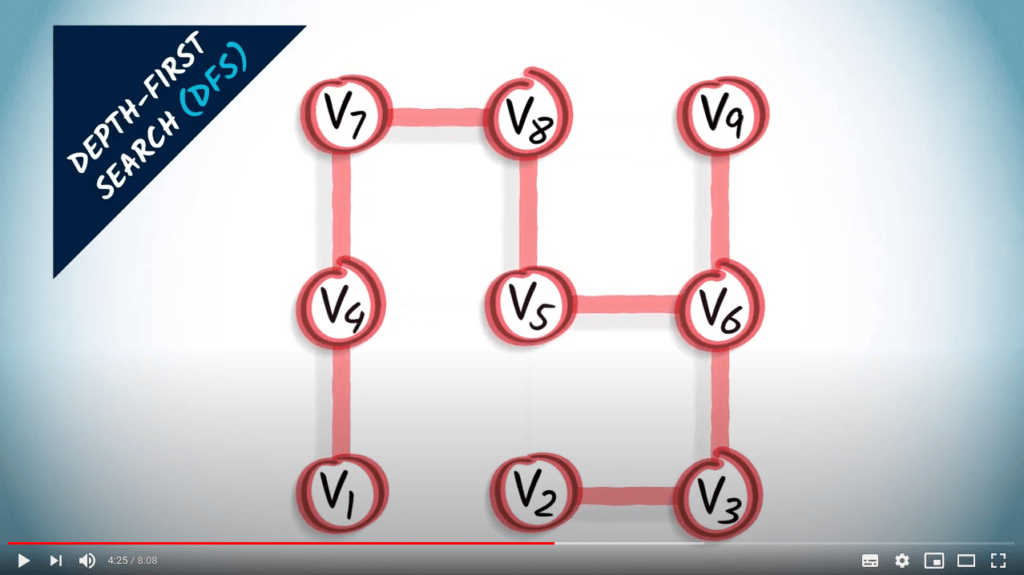
DFS est une stratégie simple mais efficace pour s’assurer que tous les sommets accessibles sont explorés.
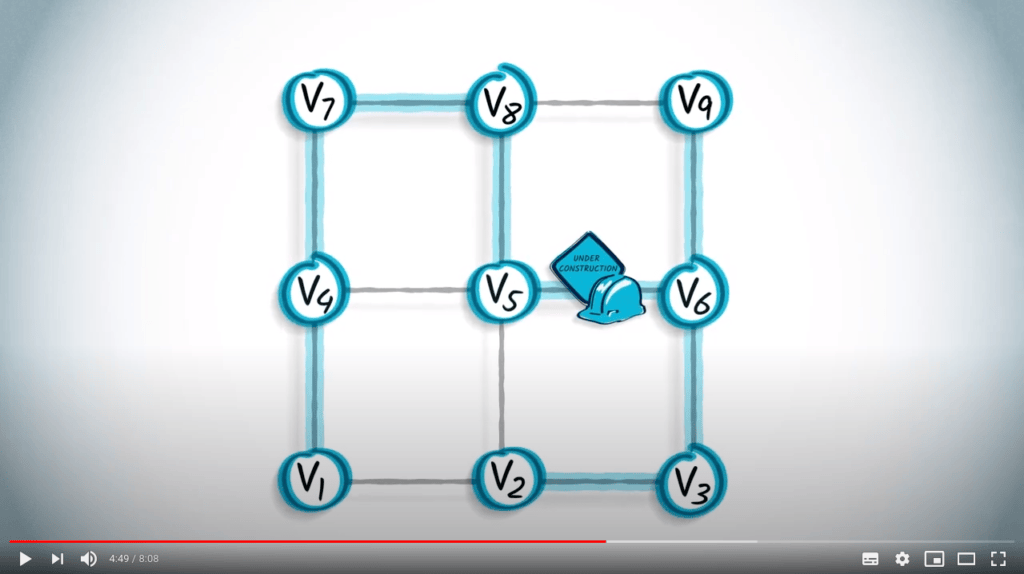
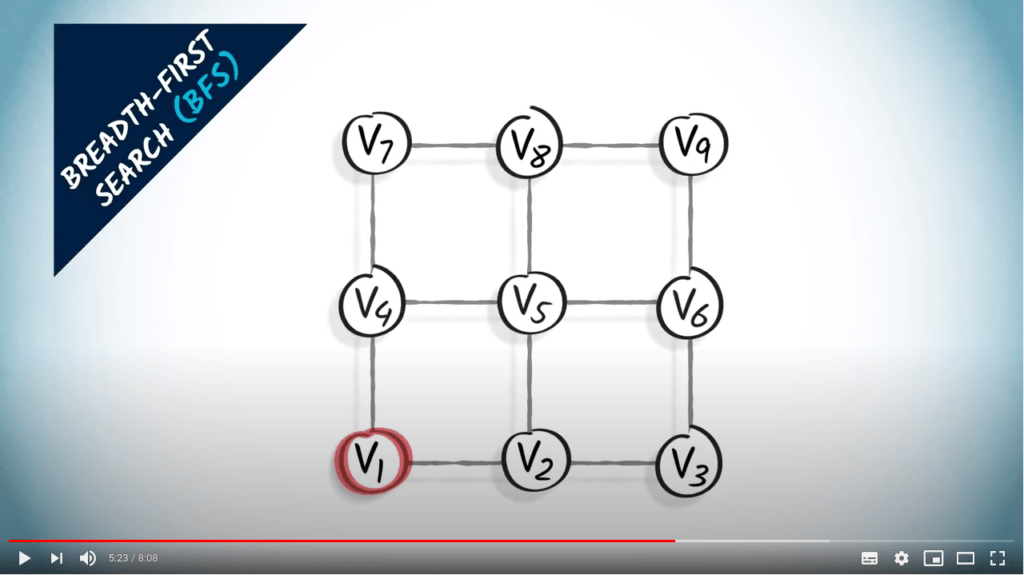
Recherche en largeur
L’autre approche que je vais décrire ici est la recherche en largeur. Lorsqu’on utilise une recherche en largeur, ou BFS, on explore le graphe en augmentant progressivement le nombre de sauts depuis le sommet initial.
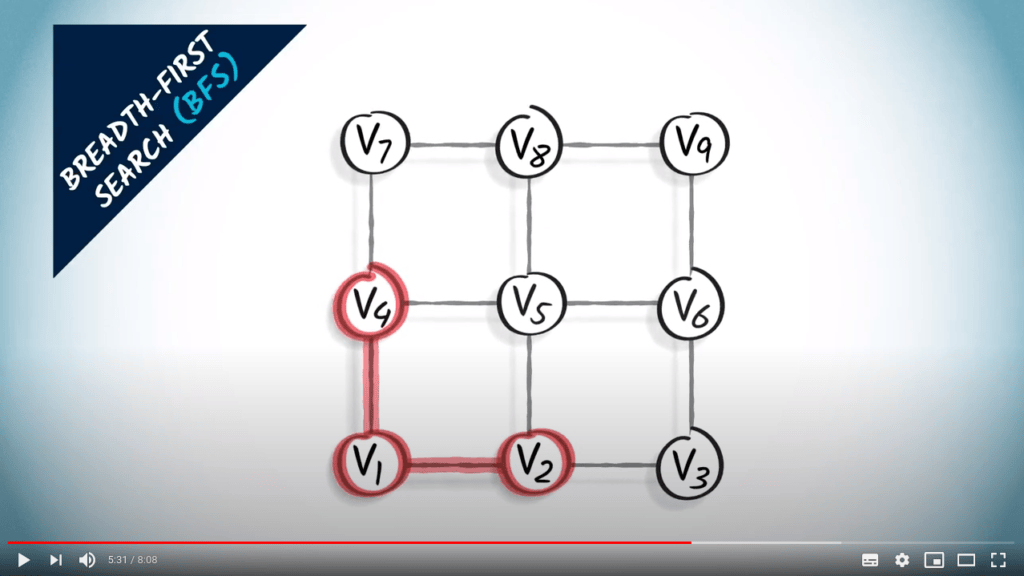
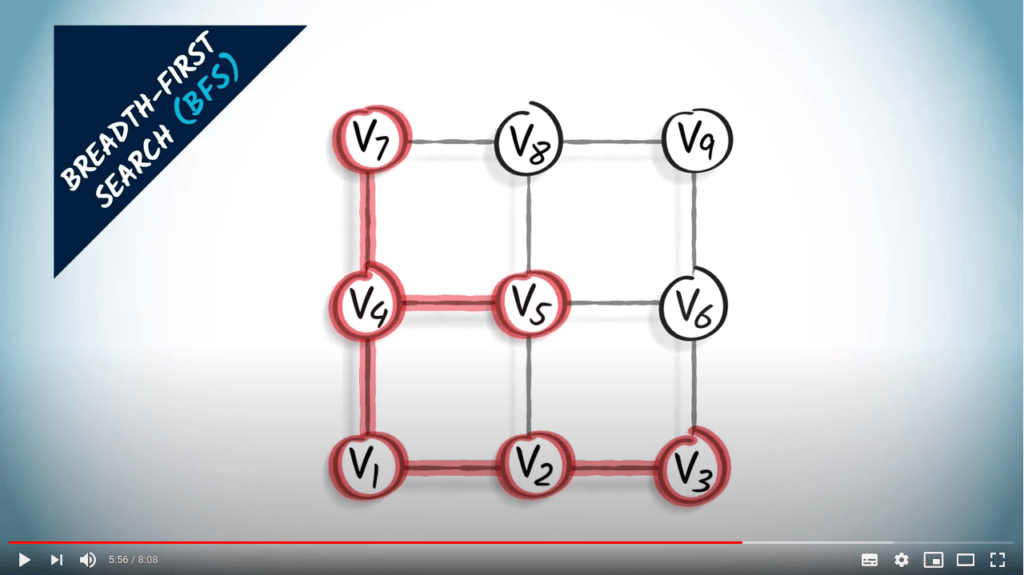
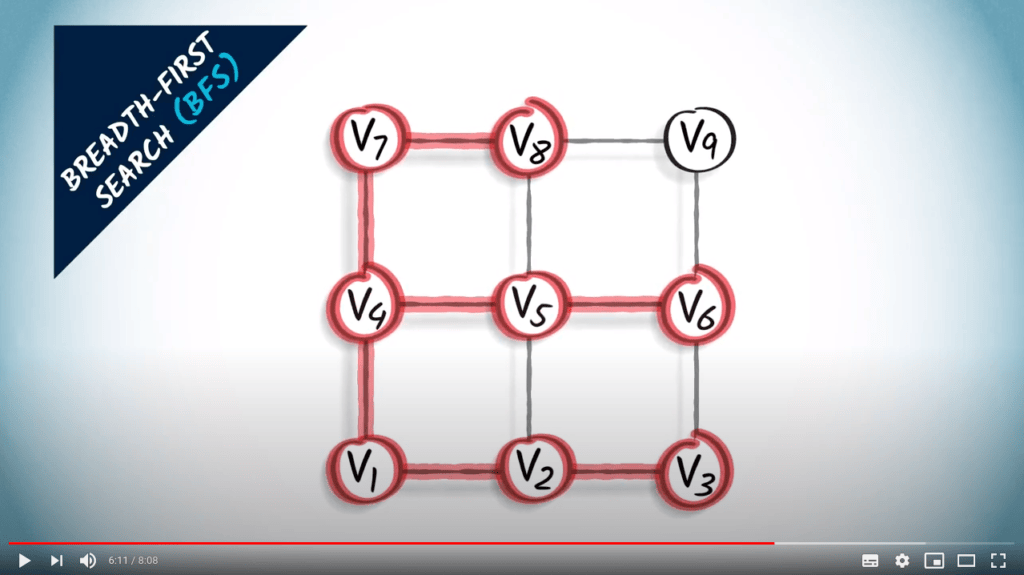
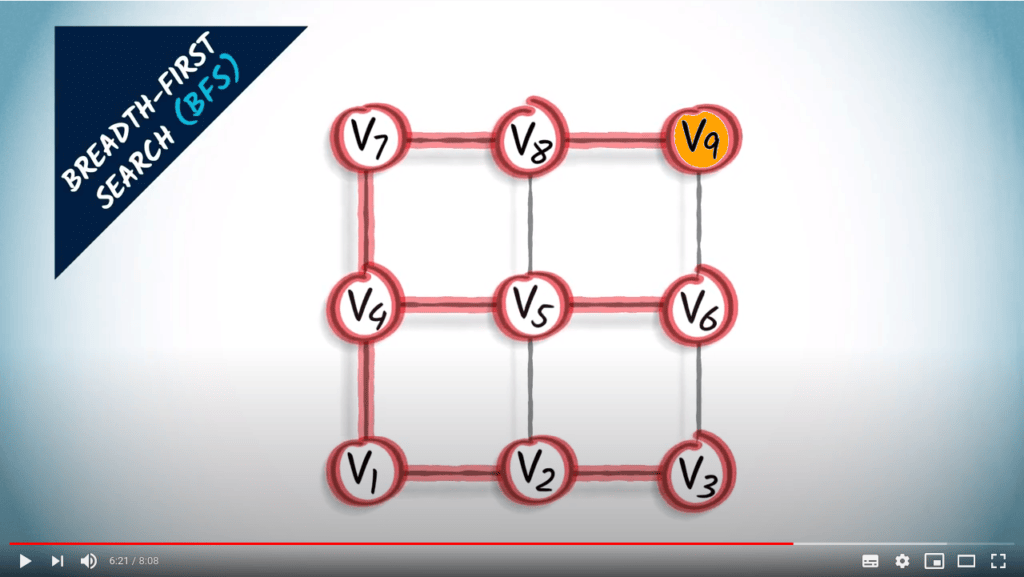
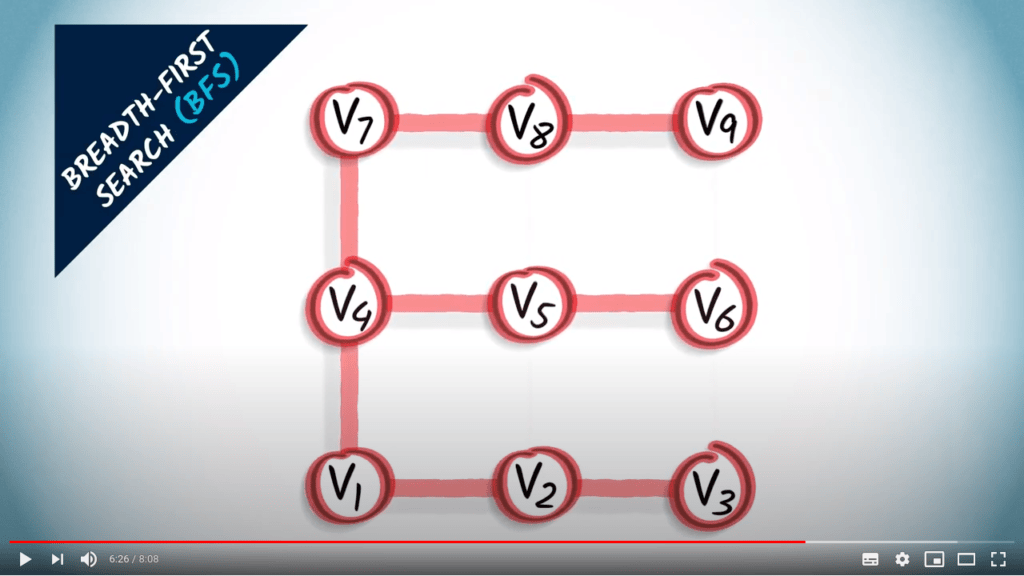
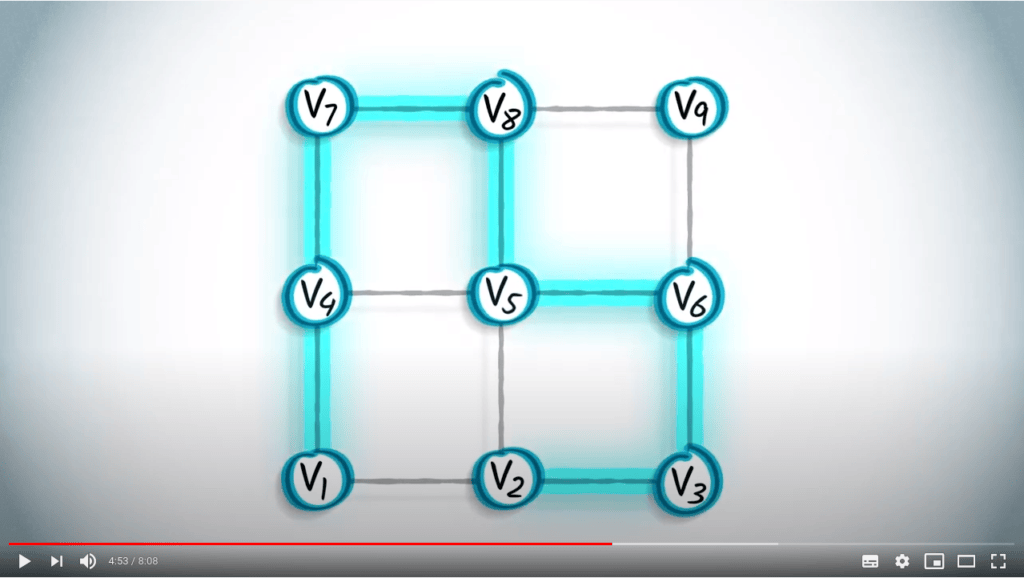
Un BFS est une stratégie prudente dans laquelle on essaie de garder les distances au sommet initial aussi petites que possible pendant l’exploration.
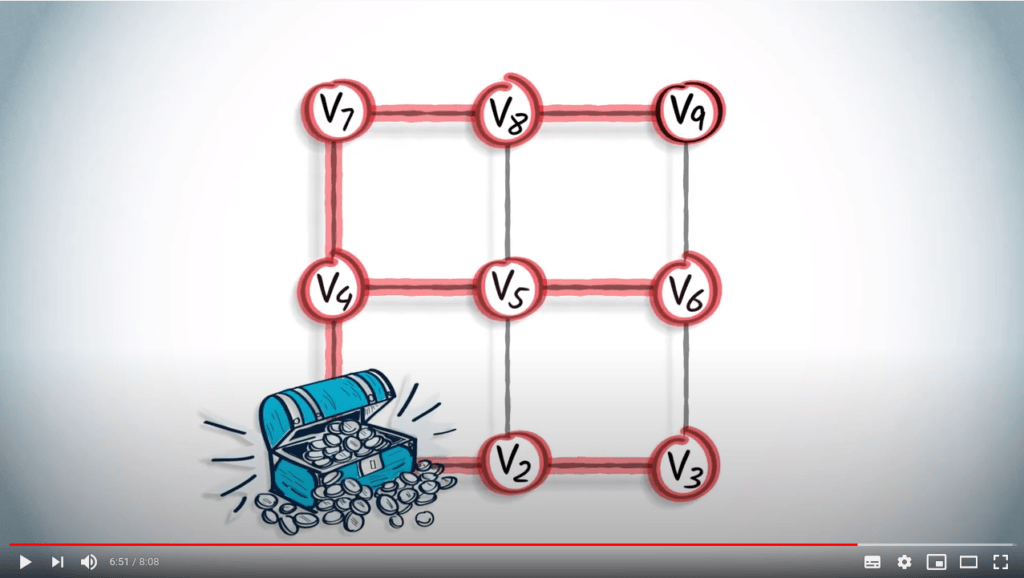
Comparaison entre BFS et DFS
Dans l’exemple précédent, les arbres couvrants obtenus par un BFS et un DFS sont très différents.
Voici un autre exemple utilisant le graphe que nous avons considéré plus tôt dans cette leçon.
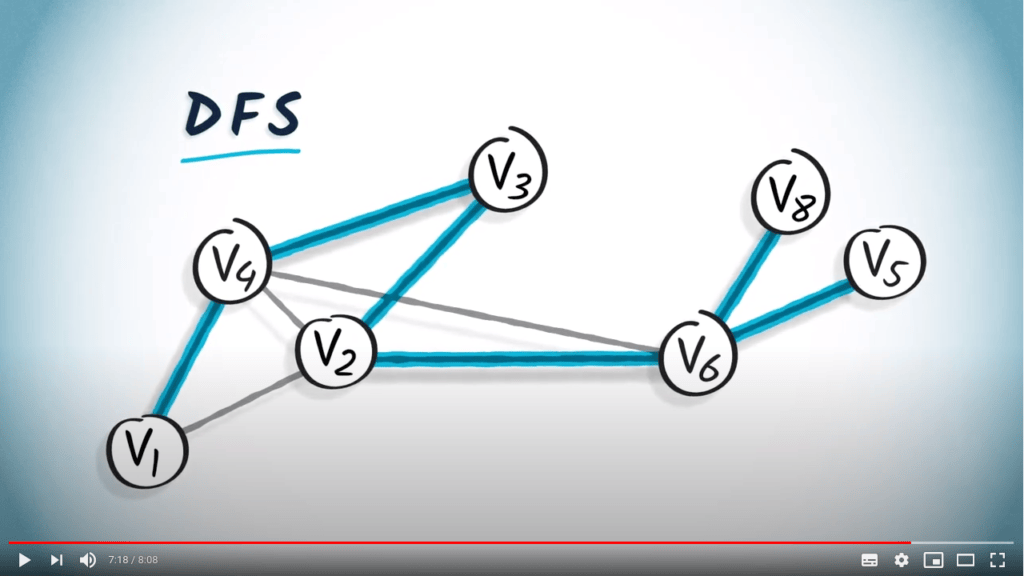
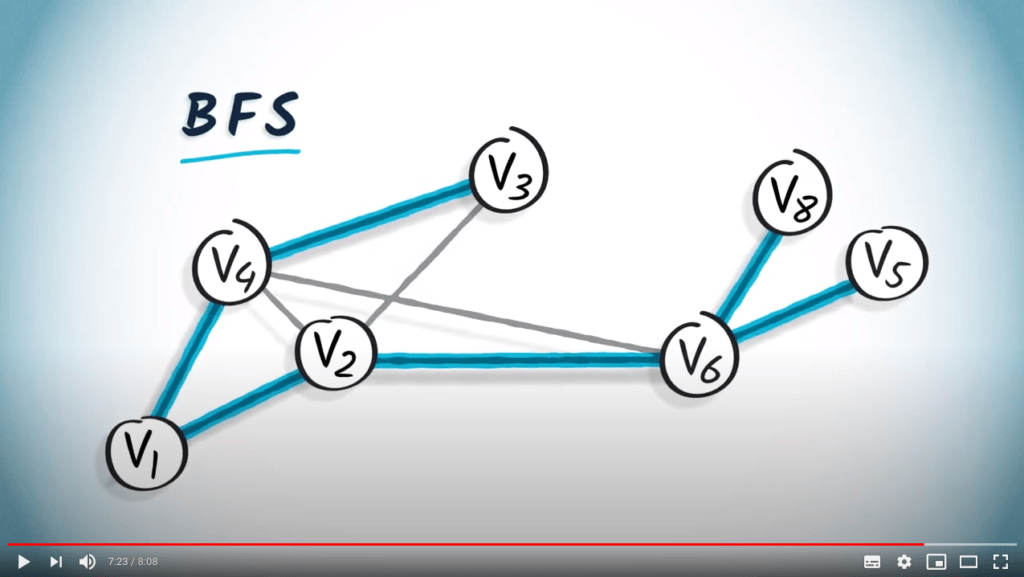
Parce qu’un BFS est réalisé en augmentant progressivement les sauts depuis $v_1$, un arbre couvrant obtenu par BFS fournira toujours le chemin le plus court de $v_1$ à n’importe quel autre sommet du graphe, à condition que le graphe soit non pondéré. Cela est clairement visible dans cet exemple.
Mots de conclusion
Dans la prochaine leçon, nous verrons comment la différence entre un BFS et un DFS est directement liée au type de structure mémoire qui peut être utilisée pour implémenter ces deux algorithmes.
Pour aller plus loin
Lors de la conception d’un algorithme, il est très important de vérifier plusieurs aspects :
- Terminaison – Le programme se termine-t-il ? En d’autres termes, existe-t-il des scénarios dans lesquels il boucle indéfiniment ?
- Correction – L’algorithme fait-il ce qu’il est censé faire ?
- Complexité – Peut-on estimer le temps nécessaire à l’algorithme pour s’exécuter, en fonction de la taille de ses entrées ?
La complexité est une notion difficile à appréhender, vous en apprendrez davantage dans une session de programmation dédiée et plus tard dans le projet. Pour l’instant, considérez simplement qu’un algorithme de complexité $O(n)$ nécessite un nombre d’opérations de l’ordre de $n$.
Il existe également d’autres propriétés qui peuvent être évaluées. Par exemple, la complexité spatiale mesure l’espace mémoire nécessaire au programme, en fonction de ses entrées. Les trois propriétés listées ci-dessus sont les plus courantes. Dans les points suivants, nous allons les évaluer pour les algorithmes BFS et DFS.
2 — Propriétés du BFS
2.1 — Terminaison
L’algorithme BFS sur un graphe fini termine.
2.2 — Correction
L’algorithme BFS retourne un chemin le plus court d’un sommet $u$ à tous les autres sommets atteignables depuis $u$ par les arêtes du graphe.
2.3 — Complexité
L’algorithme BFS a une complexité de $O(n + m)$, où $m$ est le nombre d’arêtes dans le graphe et $n$ est le nombre de sommets.
3 — Propriétés du DFS
3.1 — Terminaison
L’algorithme DFS sur un graphe fini termine.
3.2 — Correction
L’algorithme DFS est tel qu’il visitera tous les sommets atteignables depuis $u$.
3.3 — Complexité
L’algorithme DFS a une complexité de $O(n + m)$, où $m$ est le nombre d’arêtes dans le graphe et $n$ est le nombre de sommets.
Pour aller plus loin
-
Une variation du BFS pour l’accélérer tout en sacrifiant la garantie de trouver le chemin le plus court.
-
Une approche mixte entre DFS et BFS qui combine le meilleur des deux mondes.