Queuing structures for graph traversals
Reading time20 minEn bref
Résumé de l’article
Dans cet article, vous apprendrez à connaître certaines structures de file d’attente courantes, et comment elles peuvent être utilisées pour façonner le comportement d’un algorithme de parcours. Vous découvrirez les structures LIFO (Last-In First-Out) et FIFO (First-In First-Out), qui définissent respectivement un DFS et un BFS.
Principaux points à retenir
-
Les structures de file d’attente sont des structures de données dans lesquelles les données entrent/sortent dans un ordre spécifique.
-
Certaines structures courantes sont les piles et les files.
-
Elles peuvent être utilisées pour façonner le comportement d’un parcours.
-
DFS et BFS peuvent être vus comme un algorithme unique, paramétré soit avec une pile, soit avec une file.
-
Ces structures de données trouvent des applications dans de nombreuses situations en informatique.
Contenu de l’article
1 — Vidéo
Veuillez regarder la vidéo ci-dessous. Vous pouvez également lire la transcription si vous préférez.
Il y a des “codes” qui apparaissent dans cette vidéo. Veuillez garder à l’esprit que ces “codes” sont ce que nous appelons des pseudo-codes, c’est-à-dire qu’ils ne sont pas écrits dans un vrai langage de programmation. Leur but est simplement de décrire les algorithmes, pas d’être interprétables en soi. Vous devrez donc fournir un peu de travail pour en faire des codes Python pleinement fonctionnels si vous le souhaitez.
Bonjour, et bienvenue dans cette leçon sur les structures de file d’attente.
Dans les leçons précédentes, nous avons étudié les deux principaux algorithmes de parcours de graphe, DFS et BFS, et comment construire et utiliser des tables de routage pour naviguer dans leurs graphes correspondants. Dans cette leçon, nous verrons comment ces algorithmes peuvent être implémentés en pratique, en utilisant des structures de file d’attente.
Une structure de file d’attente est une structure mémoire qui peut être utilisée pour gérer les priorités entre les tâches.

Il n’y a que deux opérations qui peuvent être effectuées lors de l’utilisation d’une structure de file d’attente. À savoir, ajouter (ou pousser) un élément, et retirer (ou dépiler) un élément.
Je vais maintenant présenter deux structures de file d’attente qui peuvent être utilisées pour gérer les priorités de différentes manières.
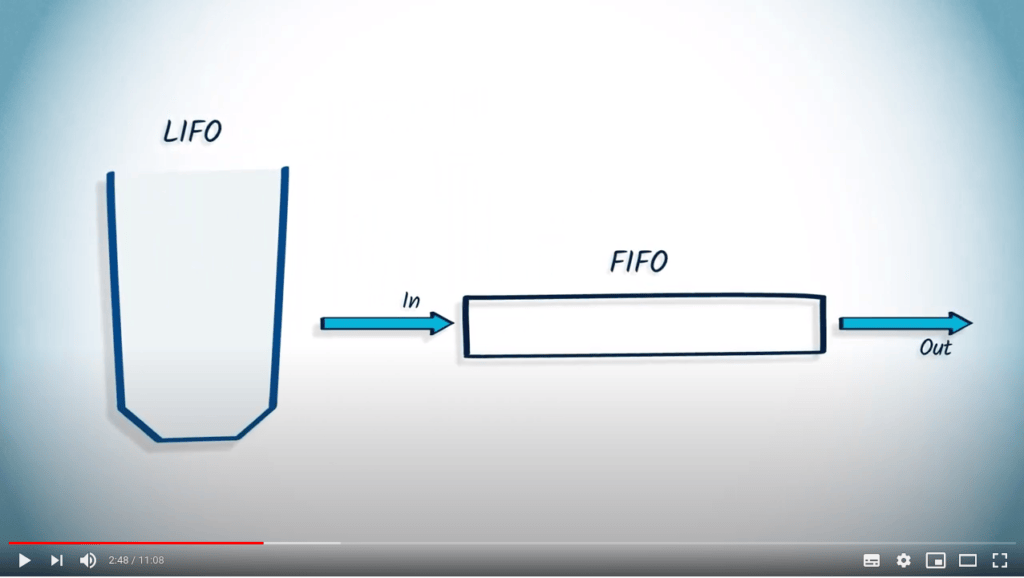
Piles / LIFO / Last-In First-Out
Une pile, connue sous le nom de Last-In First-Out, ou LIFO en abrégé, est une structure mémoire pour laquelle le dernier élément ajouté dans la pile est le premier qui sera retiré.

Files / FIFO / First-In First-Out
Au contraire, une file, connue sous le nom de First-In First-Out, ou FIFO en abrégé, est une structure mémoire pour laquelle le premier élément ajouté sera le premier à être retiré.

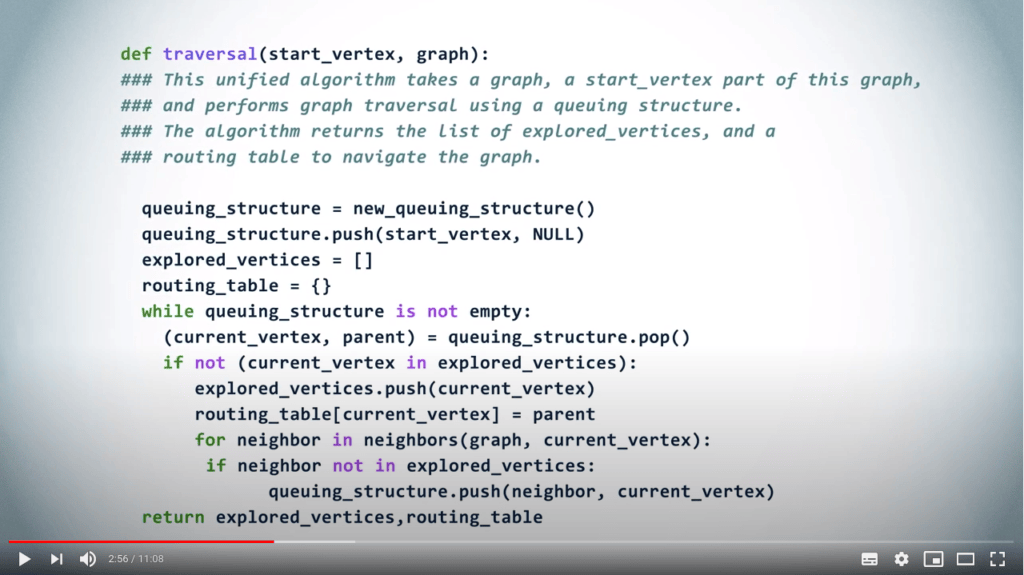
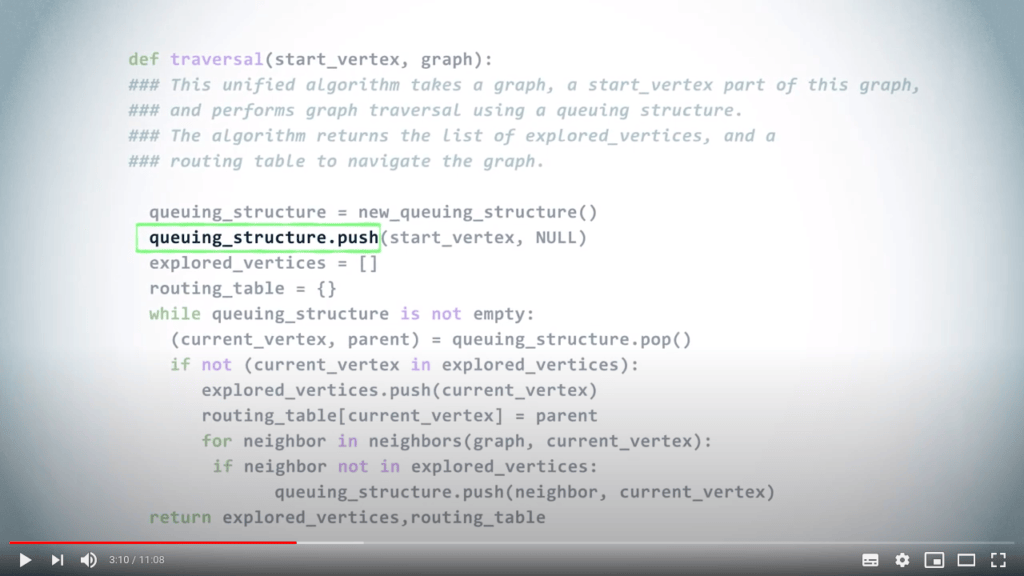
Un algorithme unifié pour le parcours de graphe
Une structure de file d’attente peut être utilisée pour gérer les priorités avec lesquelles nous examinons les sommets dans un graphe lors d’un parcours.
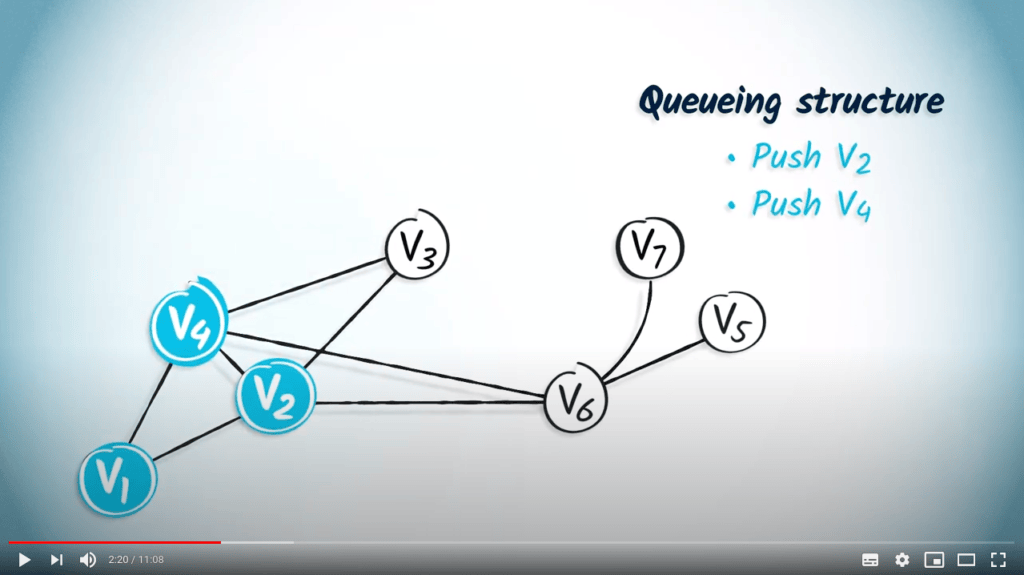
En répétant ce principe jusqu’à ce que la structure de file d’attente soit vide, on obtient un DFS si l’on choisit d’utiliser un LIFO, et un BFS lorsque l’on utilise un FIFO.
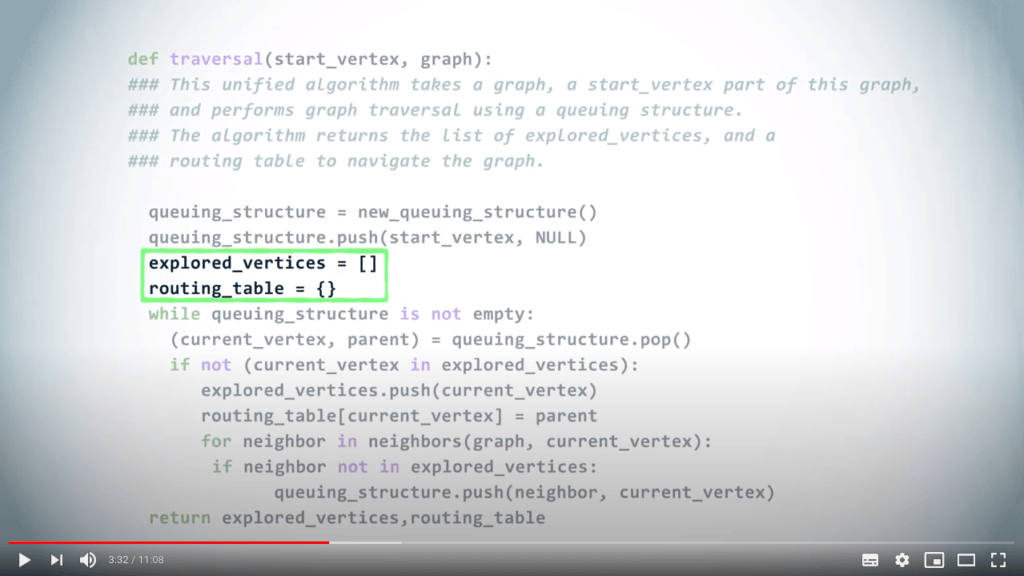
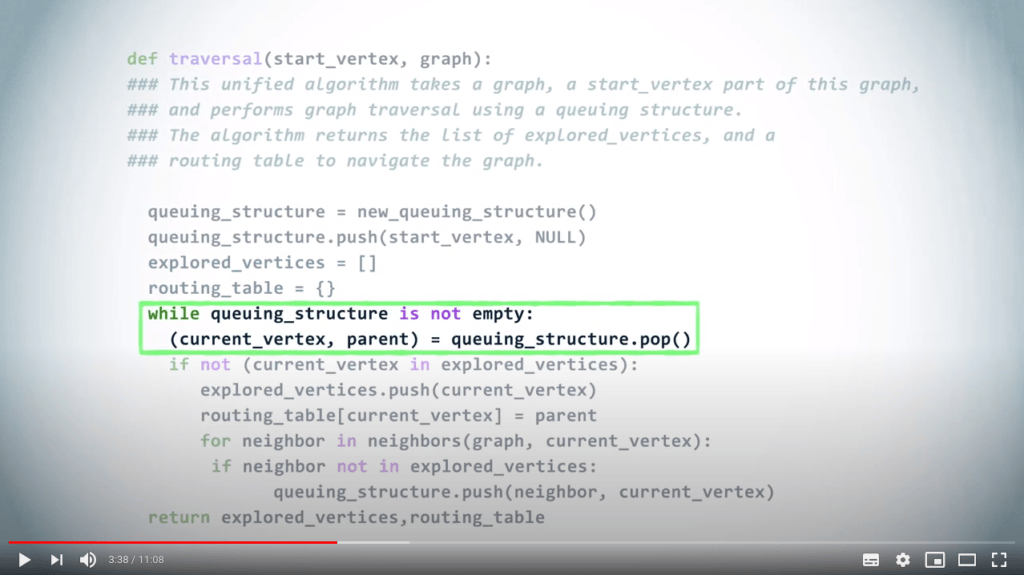
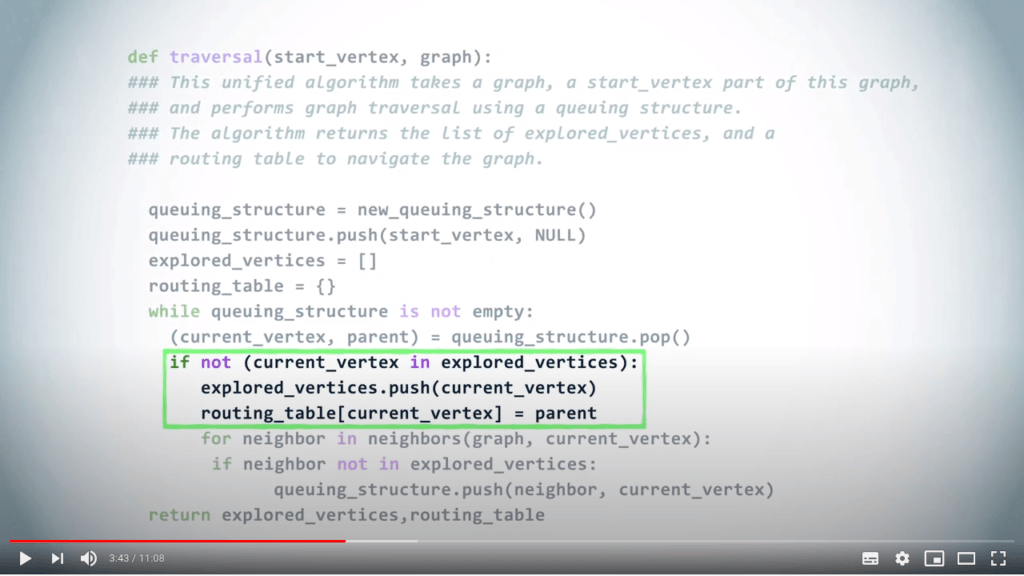
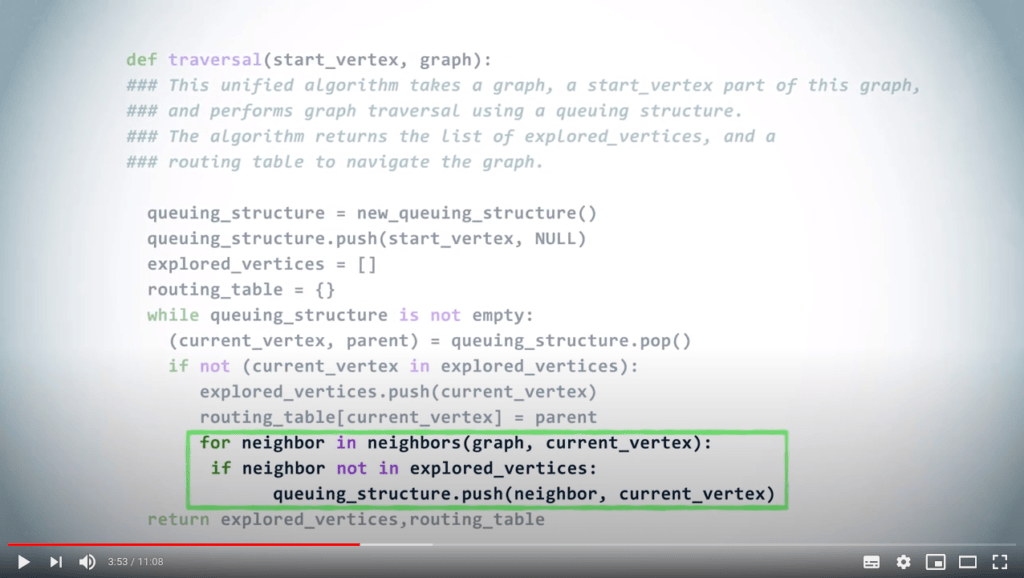
Illustrons cela avec un exemple.
Application avec DFS
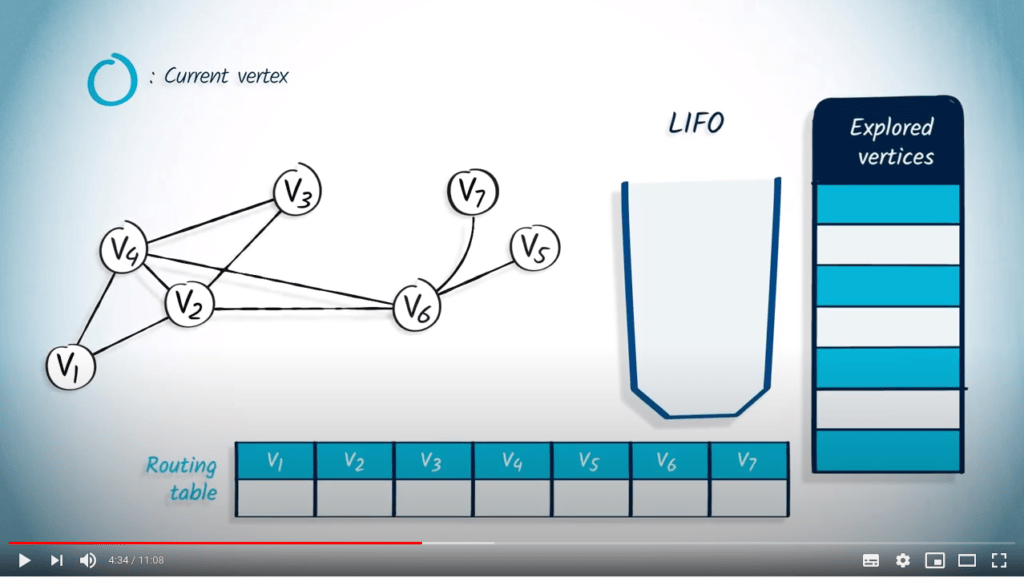
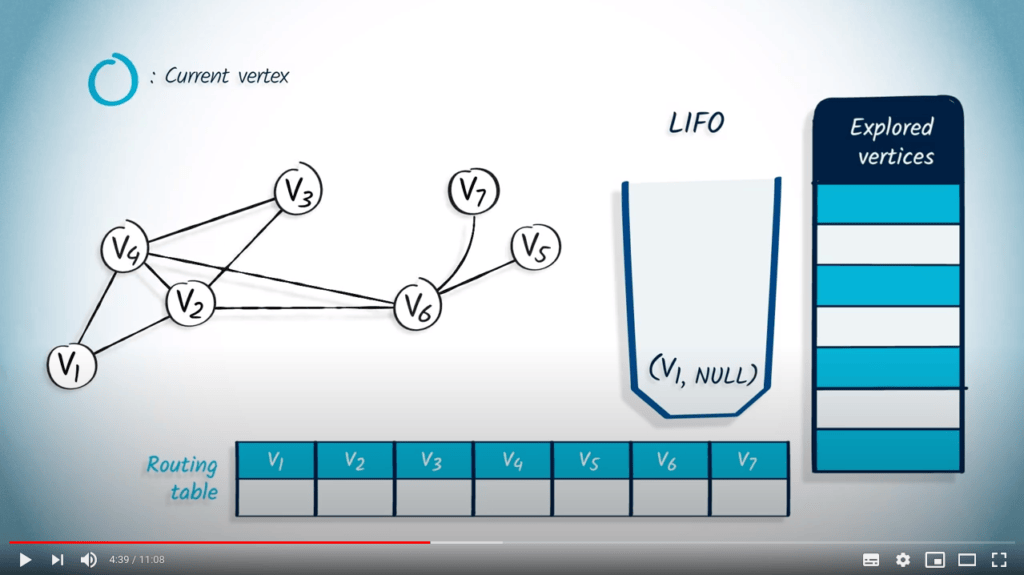
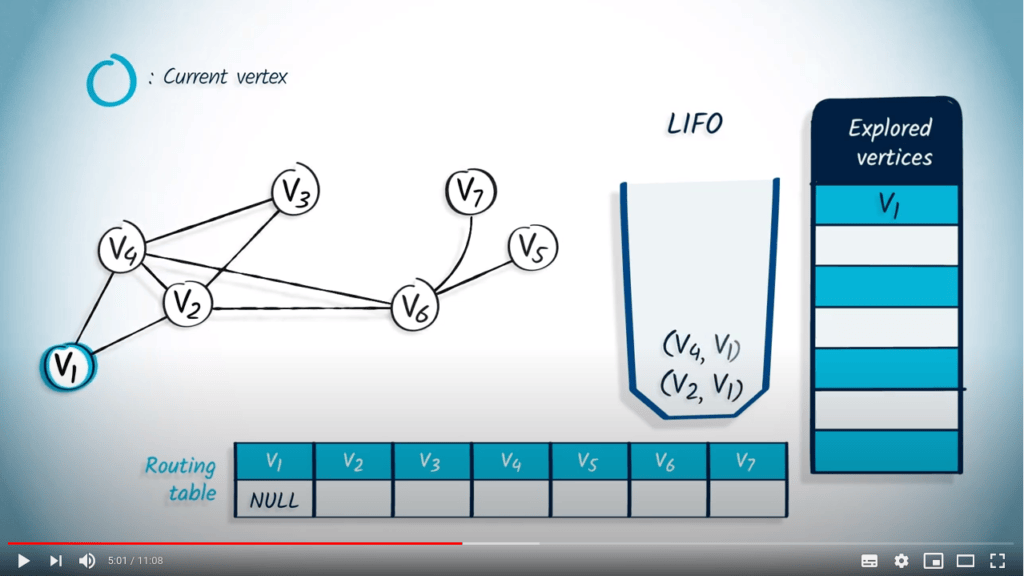
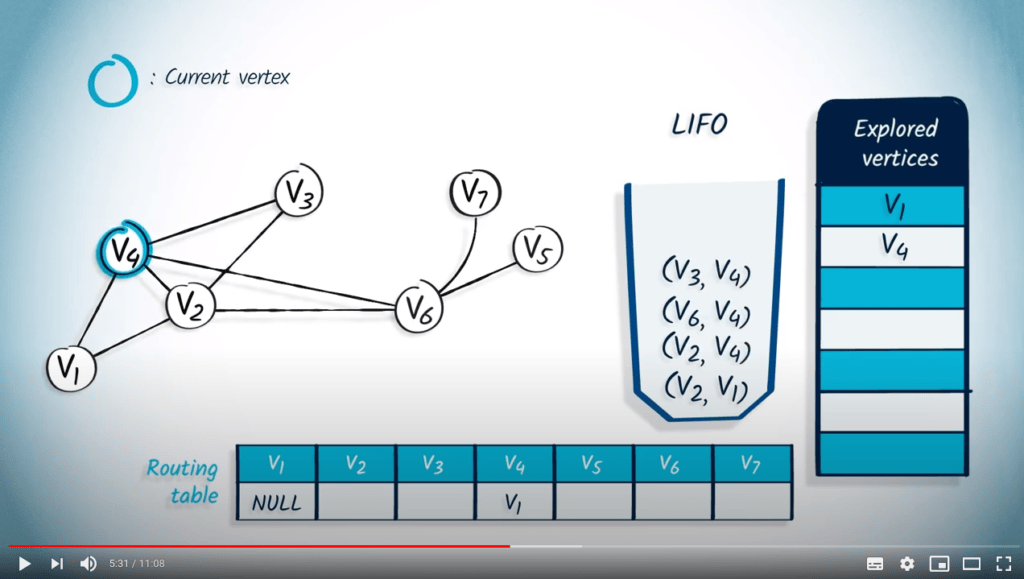
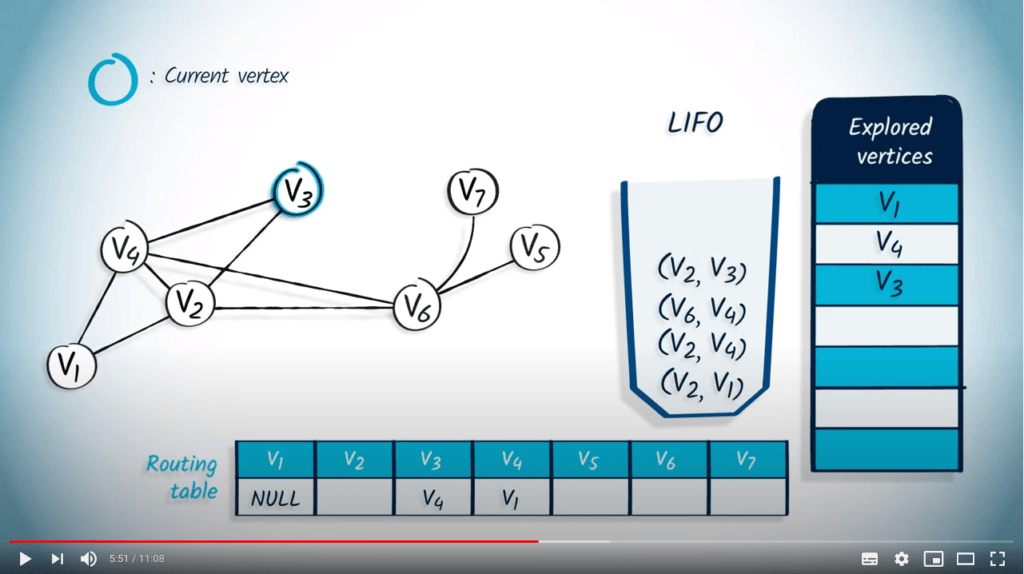
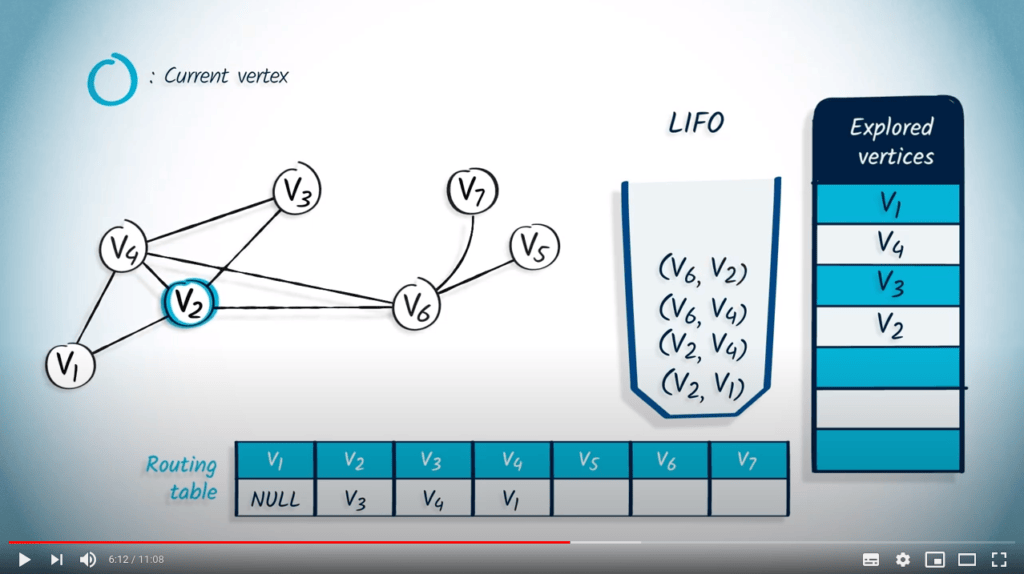
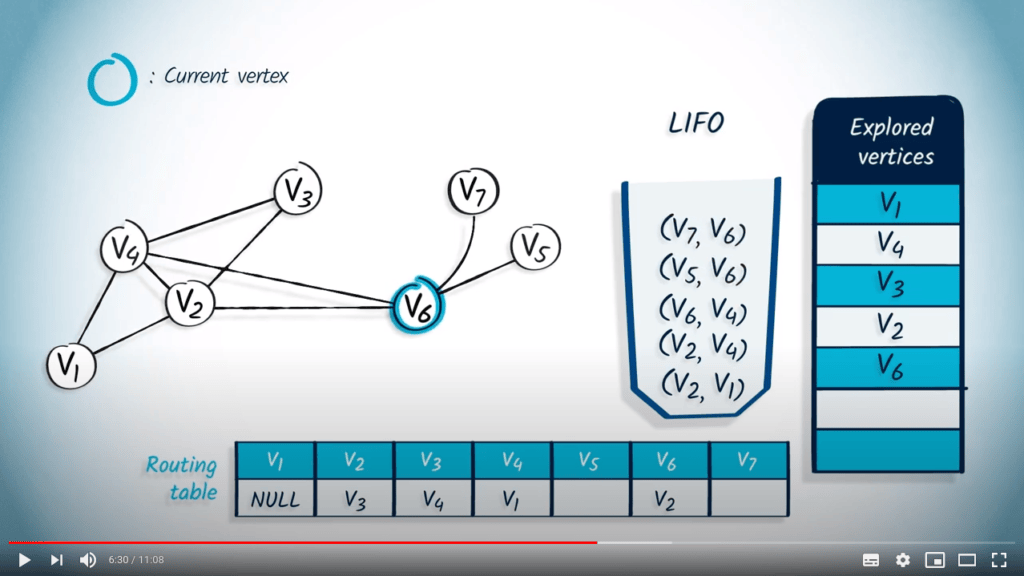
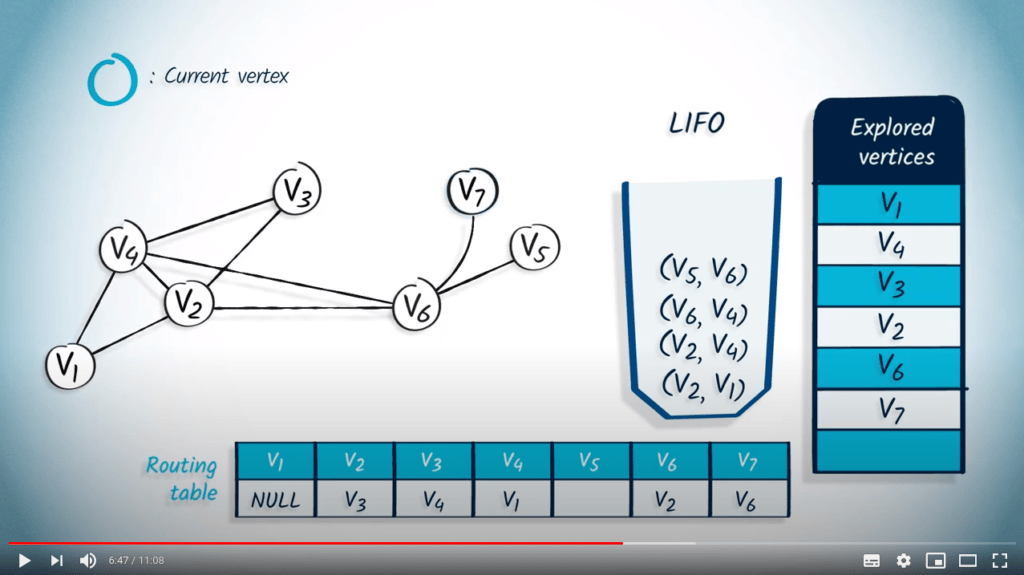
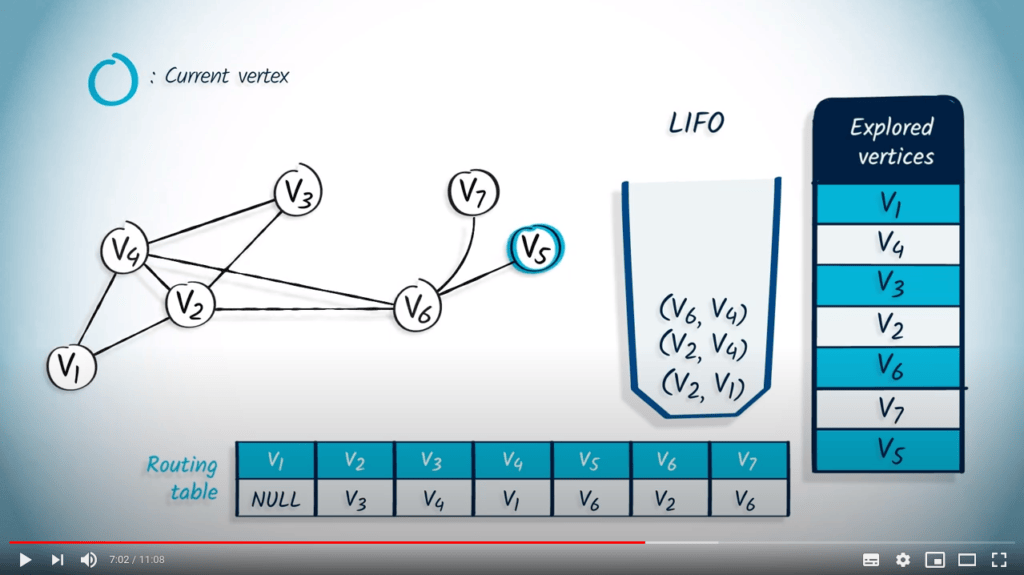
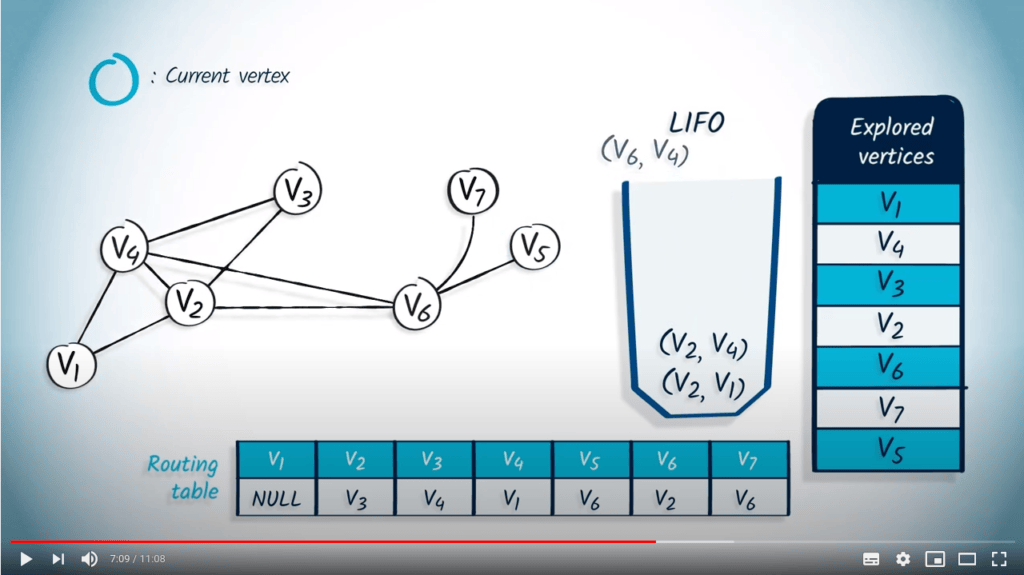
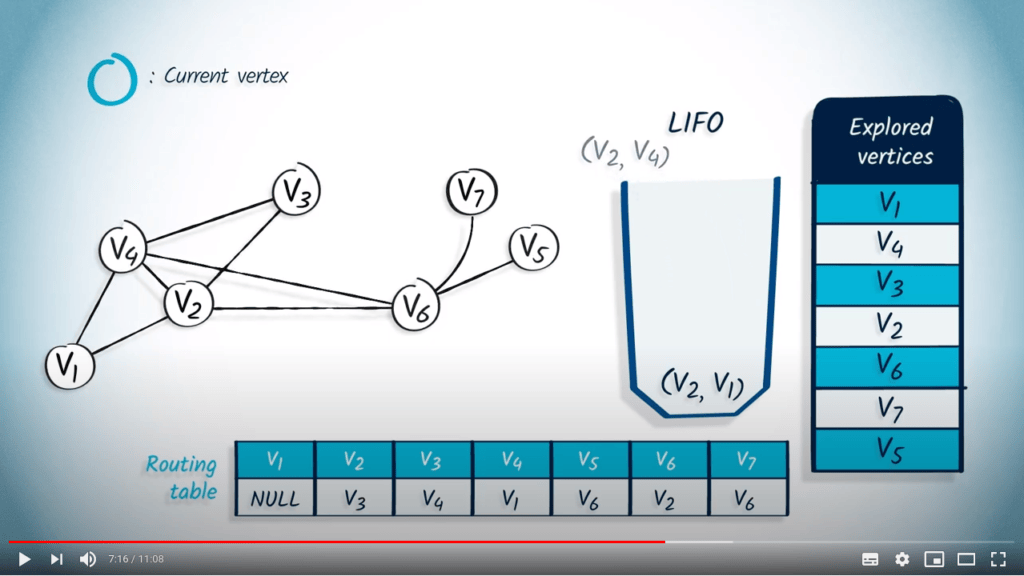
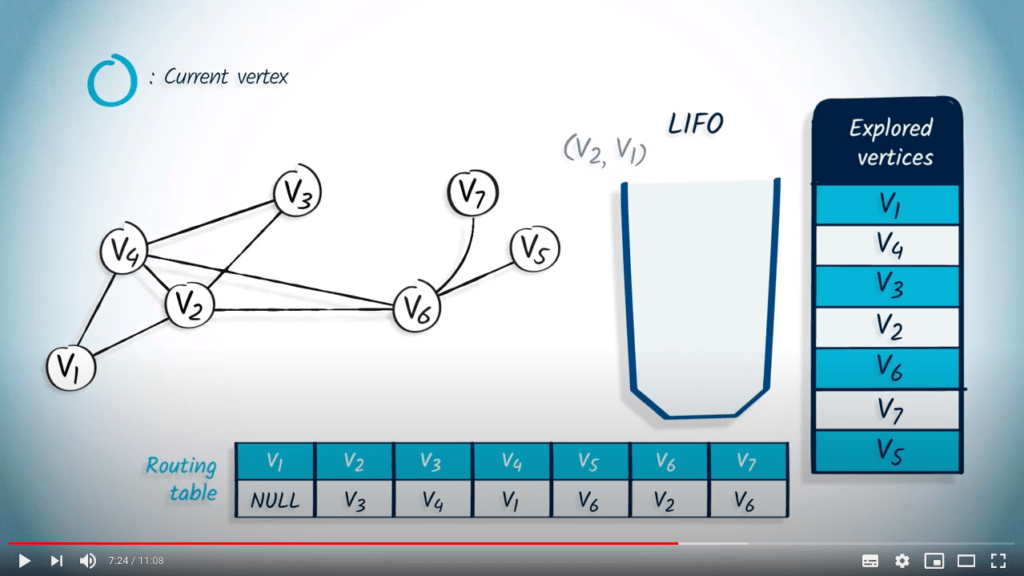
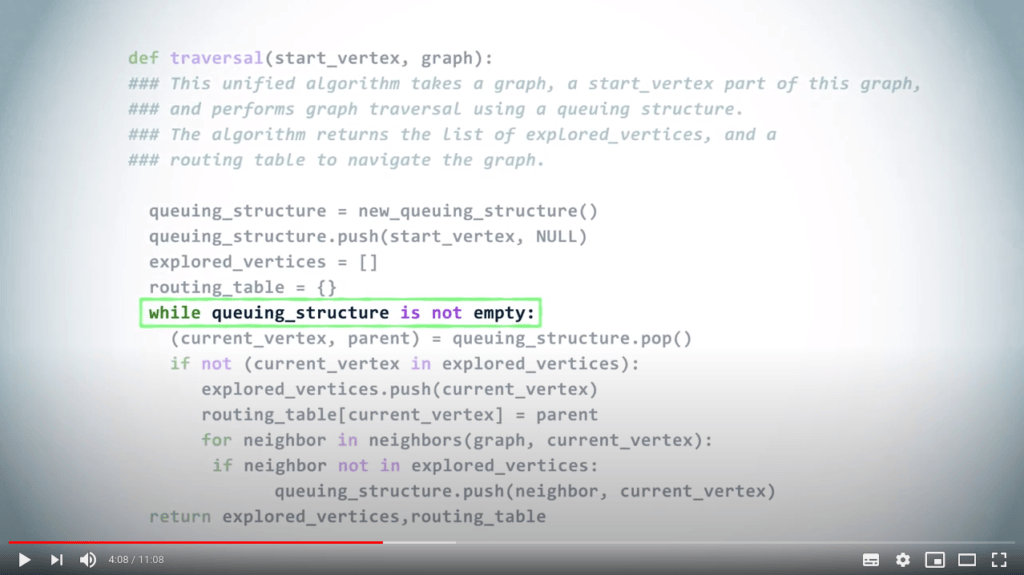
La structure de file d’attente est maintenant vide, donc l’algorithme se termine. Notez que le fait d’utiliser un LIFO correspond directement au fait que nous continuons à explorer le graphe jusqu’à ce que la recherche atteigne un sommet sans voisins non explorés, auquel cas nous revenons aux sommets explorés précédemment.
Application avec BFS
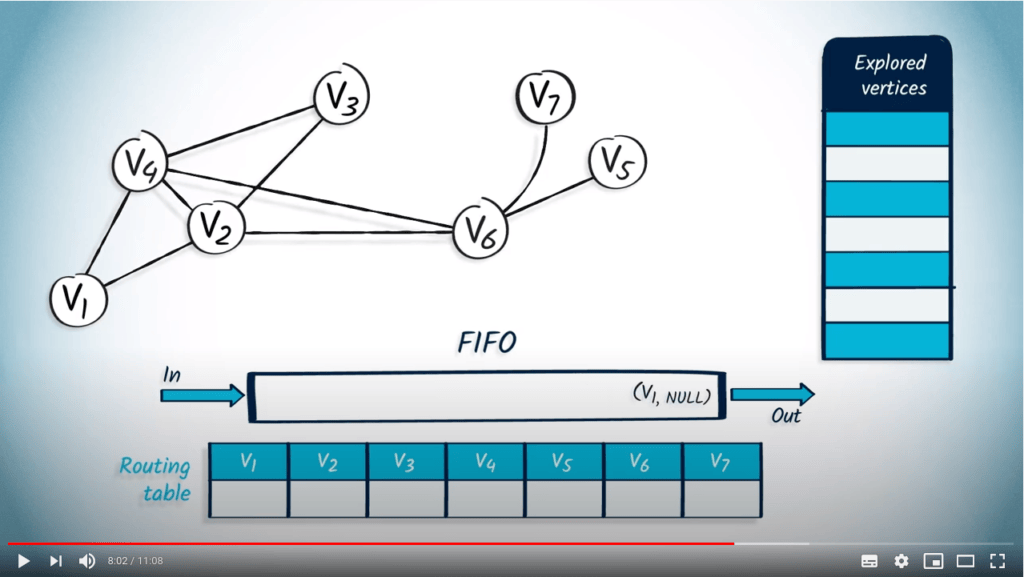
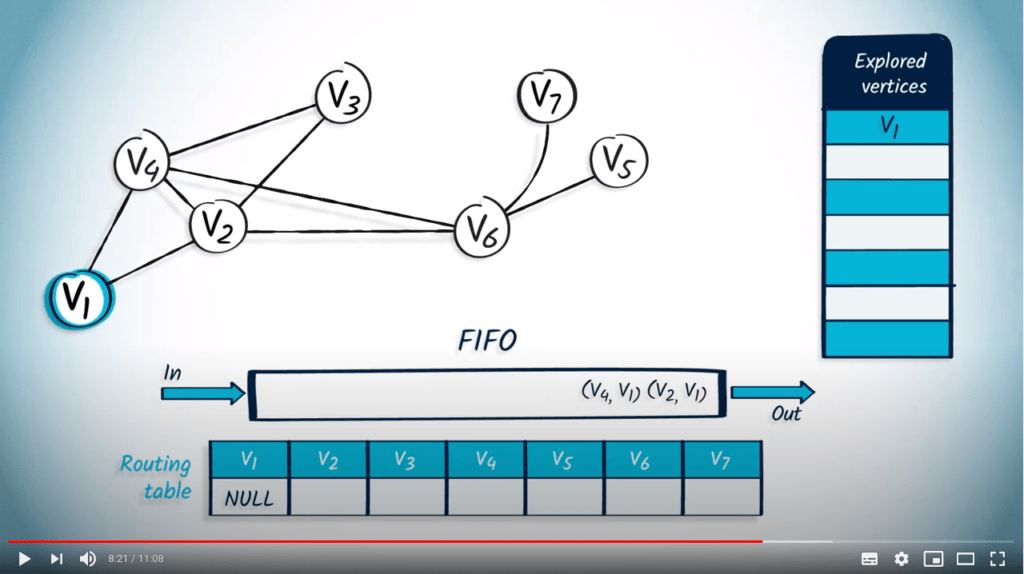
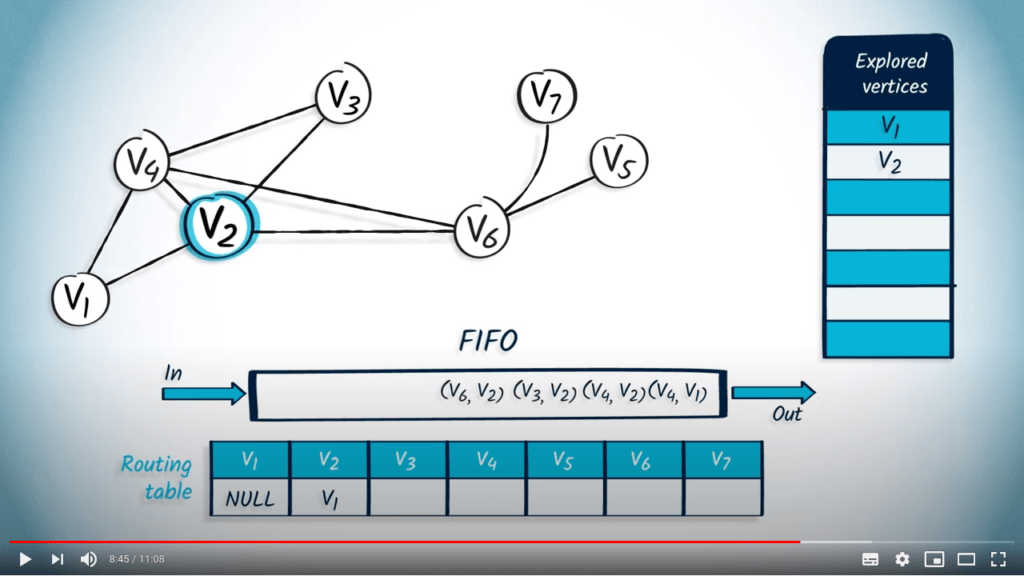
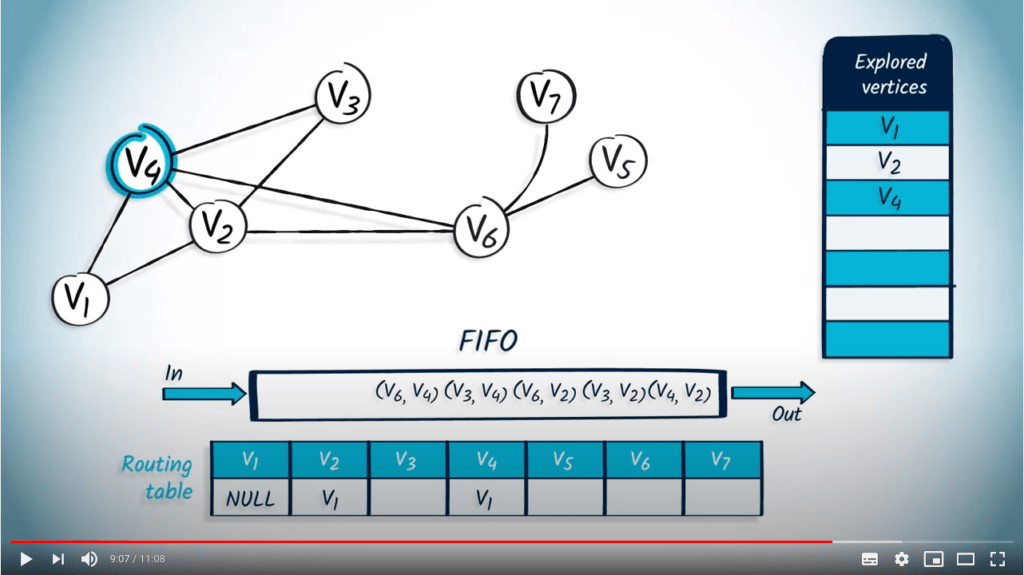
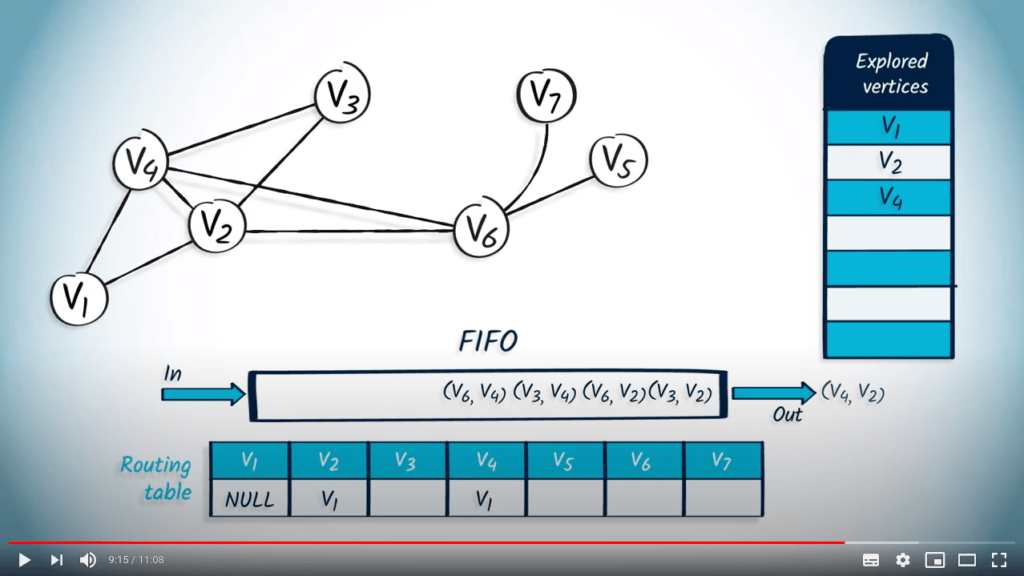
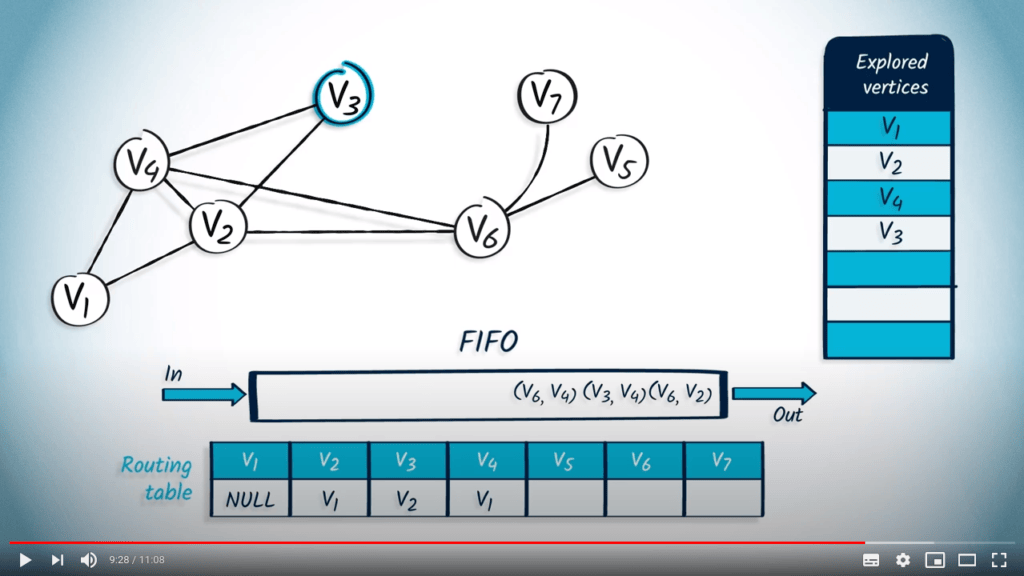
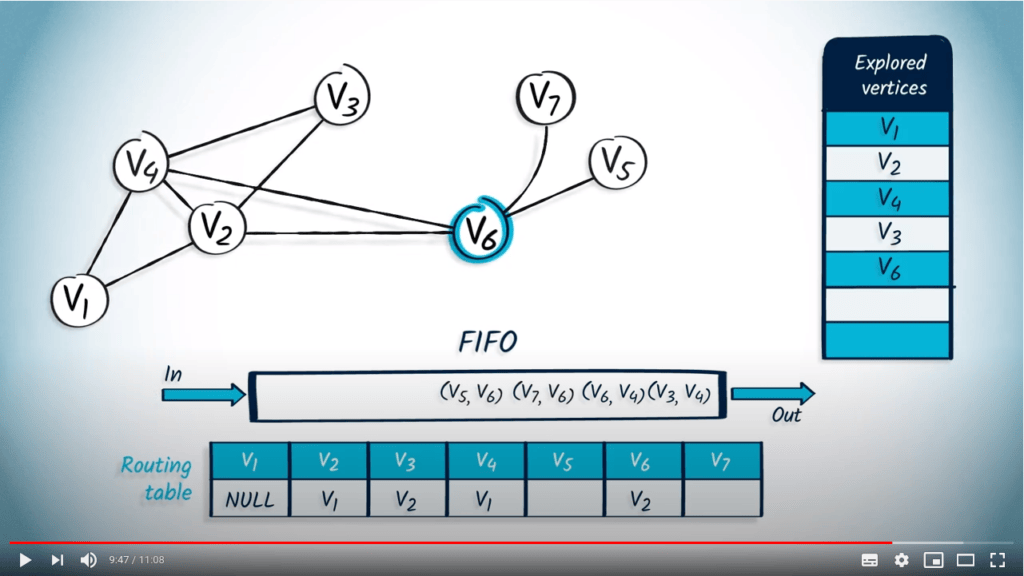
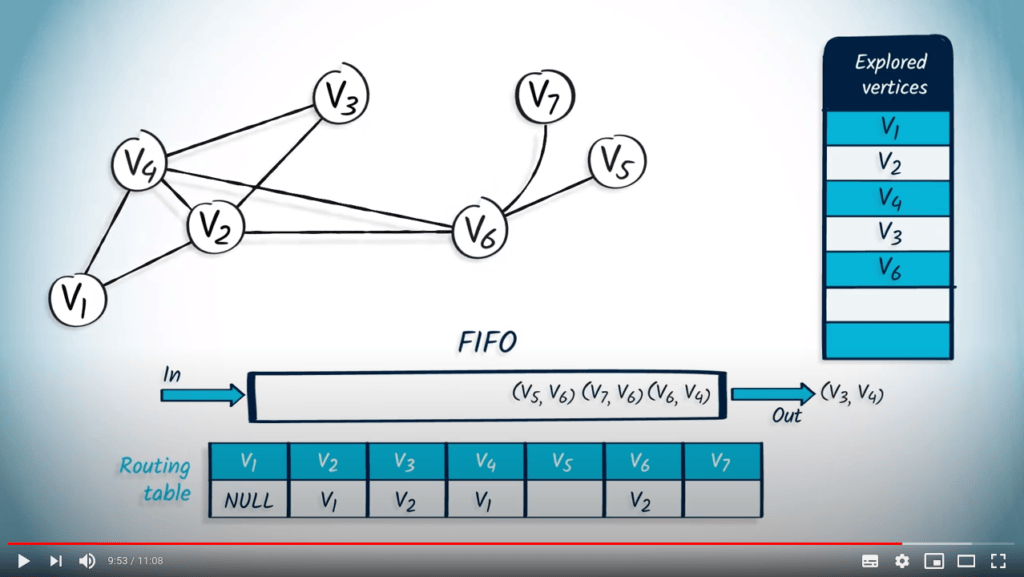
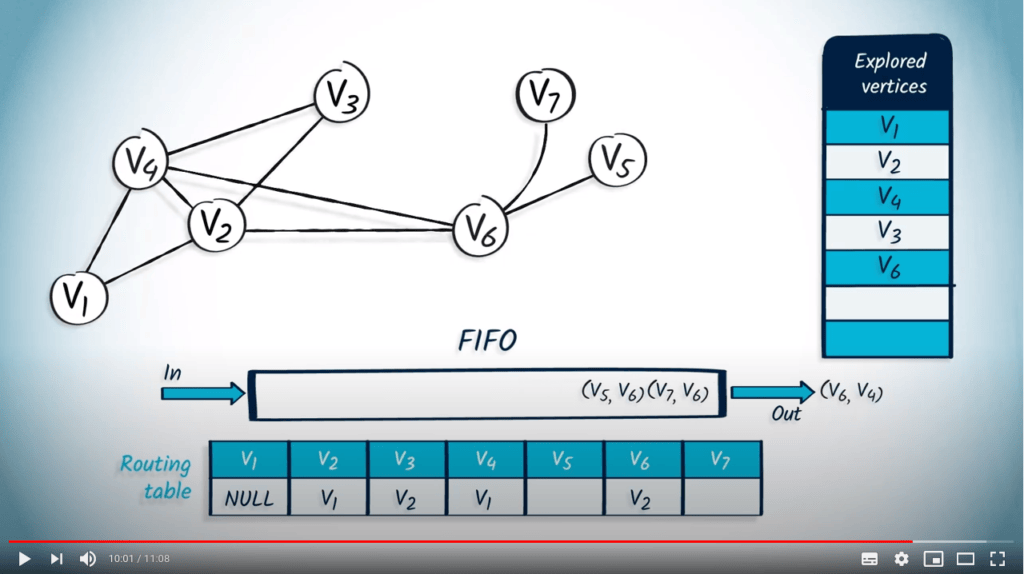
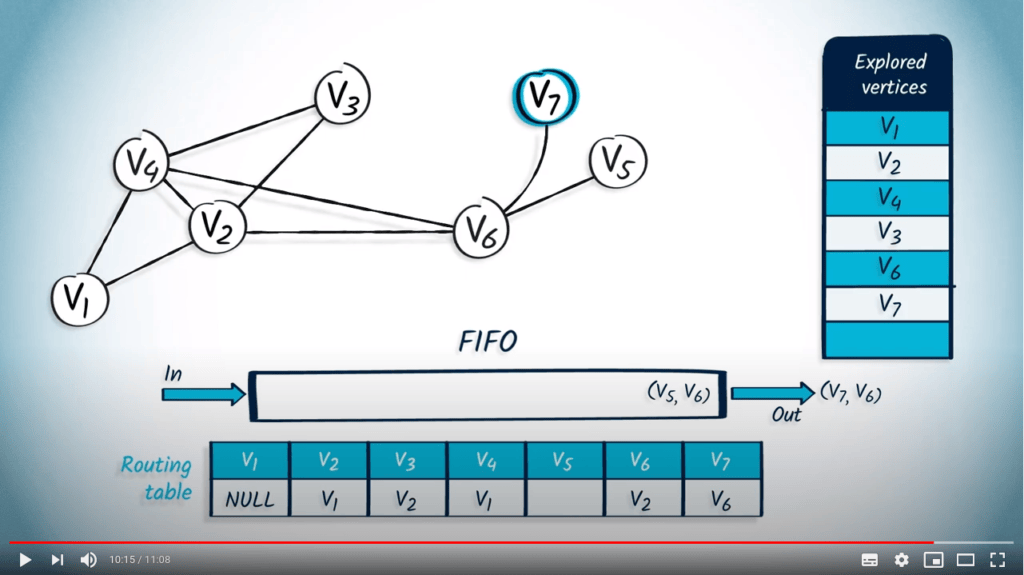
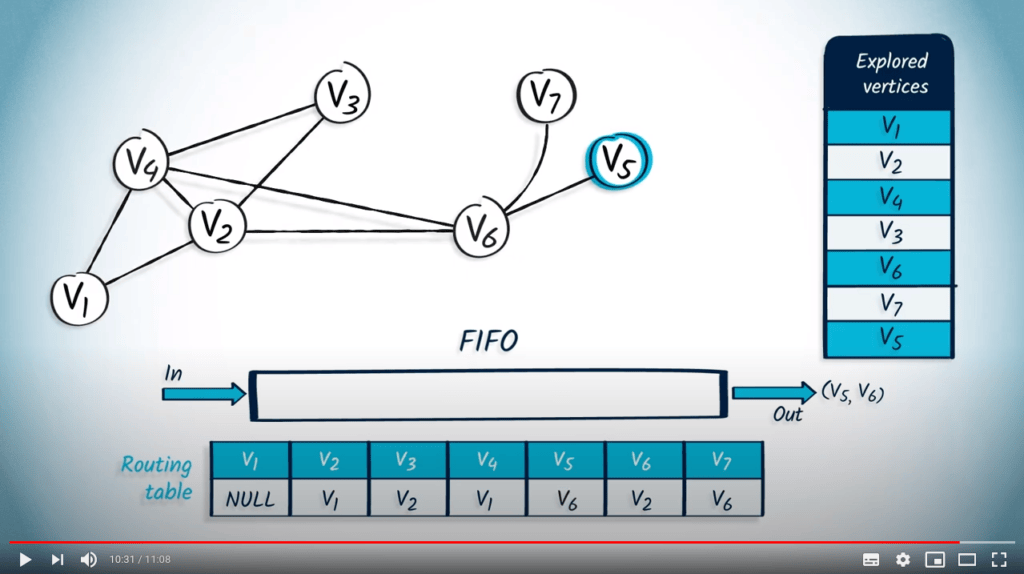
La structure de file d’attente est maintenant vide, donc l’algorithme se termine. Nous avons maintenant parcouru avec succès le graphe en utilisant BFS.
Mots de conclusion
Voilà comment vous pouvez utiliser des structures de file d’attente pour implémenter DFS et BFS.
Merci d’avoir regardé ! J’espère que vous avez apprécié apprendre sur les structures de file d’attente. C’est la fin des leçons de cette semaine. La semaine prochaine, nous verrons comment gérer les graphes pondérés.
Pour aller plus loin
2 — FIFOs et LIFOs en informatique
Pour apprécier l’importance de ces deux structures de données en informatique, nous présentons deux exemples de situations réelles dans lesquelles elles sont utilisées.
2.1 — FIFOs dans les systèmes de communication
Pour que deux personnes communiquent, elles doivent s’envoyer des messages. Et, pour que deux personnes se comprennent, elles doivent s’envoyer des messages dans un ordre logique. Vous trouverez plus facile de comprendre la phrase “A computer lets you make more mistakes faster than any other invention with the possible exceptions of handguns and Tequila” que “Make and tequila you than a faster the possible any exceptions handguns of invention computer lets more with other mistakes”.
Pour les machines, c’est pareil : l’ordre est important, et doit être pris en compte. Certains modèles de communication (d’autres sont beaucoup plus complexes) utilisent des files pour cela. Imaginez un modèle dans lequel nous avons un ordinateur $A$ qui écrit des mots dans une file, et un ordinateur $B$ qui les lit. Si l’ordinateur $A$ envoie les mots dans l’ordre, alors $B$ les lira dans le même ordre (car le premier élément inséré dans une file est aussi le premier à en sortir), et la communication sera possible.
Vous vous demandez peut-être pourquoi passer par un FIFO et ne pas envoyer l’information directement ? L’avantage est que les ordinateurs $A$ et $B$ ne vont pas forcément à la même vitesse (qualité du processeur, carte réseau…). Ainsi, si l’ordinateur $A$ envoie des messages à l’ordinateur $B$ très rapidement (directement), ce dernier en manquera certains. Passer par une file permet de stocker les messages, dans l’ordre, pour éviter ces problèmes de synchronisation.
2.2 — LIFOs dans les langages de programmation
Lorsqu’un système d’exploitation exécute un programme, il lui alloue de la mémoire afin qu’il puisse faire ses calculs correctement. Cette mémoire est généralement divisée en deux zones : le tas qui stocke les données, et la pile qui permet (entre autres) d’appeler des fonctions dans les programmes.
Dans la plupart des langages de programmation, lorsqu’une fonction f(a, b) est appelée à un endroit du code, la séquence suivante (simplifiée) se produit :
- L’adresse de retour est poussée sur la pile.
Cela permettra de revenir juste après l’appel de
fune fois son exécution terminée. - L’argument
aest poussé sur la pile. - L’argument
best poussé sur la pile. - Le processeur est invité à traiter le code de
f. - On dépile un élément de la pile pour obtenir
b. - On dépile un élément de la pile pour obtenir
a. - Le code de
fest exécuté. - Une fois que
fest terminé, on dépile un élément de la pile pour obtenir l’adresse de retour et revenir au moment oùfa été appelé. - Le processeur est invité à sauter à cette adresse.
Mais pourquoi utiliser une pile au lieu de variables pour passer cette information ?
Eh bien, le processeur ne connaît pas les détails de f !
Il est possible que f utilise une autre fonction g par exemple.
Si des variables étaient utilisées, l’adresse de retour de f serait écrasée par l’adresse de retour de g, et lorsque g serait terminé, on ne pourrait jamais revenir au moment de l’appel de f.
Et un FIFO alors ?
Ici encore, le problème se pose si f appelle une fonction g.
Comme l’adresse de retour de f est mise avant celle de g dans la file, lorsqu’il est nécessaire de revenir de l’appel à g, le processeur obtiendra à la place l’adresse de retour de f (la plus ancienne dans la file) !
Nous n’exécuterons donc jamais le code de f situé après l’appel à g.
Pour aller plus loin
- Queuing theory.
Donne plus de résultats sur les files (temps d’attente moyen avant d’être dépilé, etc.) et a de nombreuses applications.