Min-heaps
Reading time15 minEn bref
Résumé de l’article
Dans cet article, vous apprendrez ce qu’est un min-heap, une structure de données possédant des propriétés particulières. Ils seront très utiles pour utiliser l’algorithme de Dijkstra.
Points clés
-
Les min-heaps sont des structures de données dans lesquelles les données sont extraites en utilisant une valeur de référence.
-
Ils peuvent être utilisés pour implémenter facilement l’algorithme de Dijkstra.
-
Il existe plusieurs façons de programmer un min-heap, certaines meilleures que d’autres.
-
En Python,
heapqfournit une bonne implémentation des min-heaps.
Contenu de l’article
1 — Vidéo
Veuillez regarder la vidéo ci-dessous. Vous pouvez également lire les transcriptions si vous préférez.
Il y a des “codes” qui apparaissent dans cette vidéo. Veuillez garder à l’esprit que ces “codes” sont ce que nous appelons des pseudo-codes, c’est-à-dire qu’ils ne sont pas écrits dans un vrai langage de programmation. Leur but est simplement de décrire les algorithmes, pas d’être interprétables en tant que tels. Vous devrez donc fournir un peu d’effort pour les rendre pleinement fonctionnels en Python si vous le souhaitez.
Bienvenue à nouveau ! Ravi de vous revoir !
La semaine dernière, nous avons vu comment implémenter le DFS et le BFS en utilisant des structures de file d’attente. Cette semaine, pour implémenter l’algorithme de Dijkstra, nous allons avoir besoin d’une structure de file d’attente un peu plus élaborée : une qui prendra en compte les poids dans le graphe.
Min-heaps
Regardons une autre structure de file d’attente pour implémenter l’algorithme de Dijkstra. Voici le min-heap.

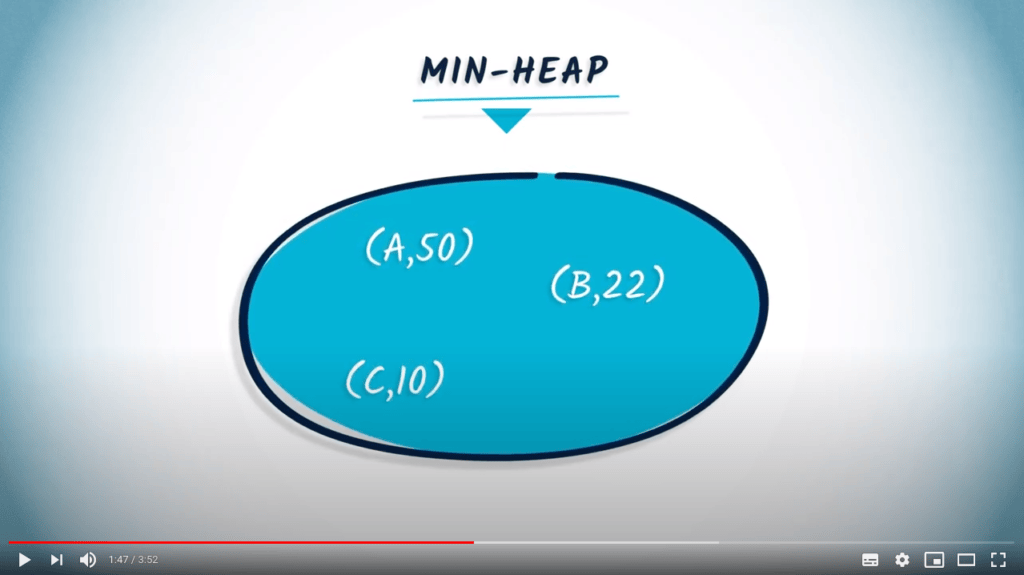
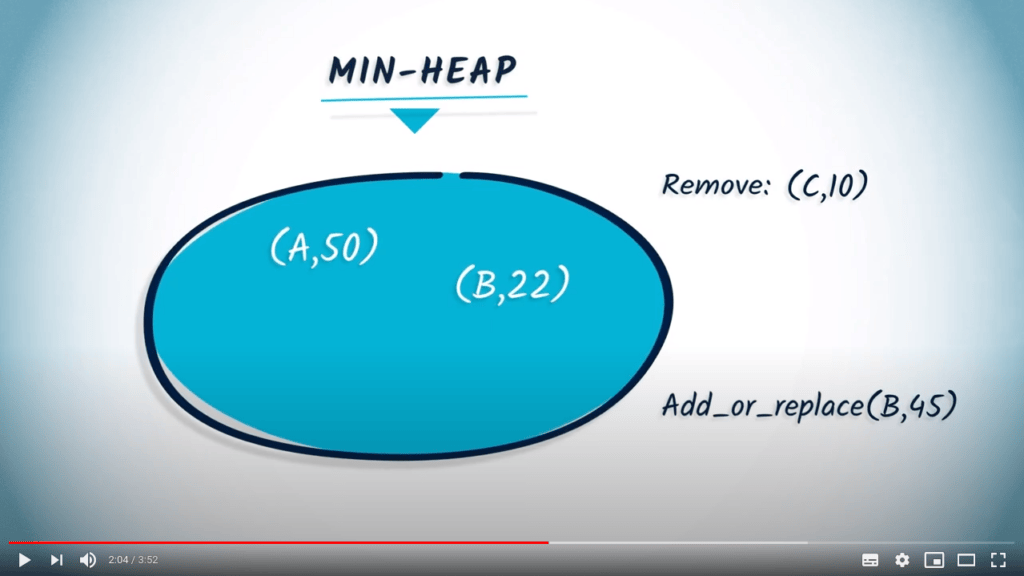
Avec un min-heap, deux opérations élémentaires peuvent être effectuées. La première est add-or-replace. L’opération add-or-replace est utilisée pour ajouter un couple (key, value) au min-heap. Si la clé existe déjà, et que sa valeur associée est plus grande que celle que nous voulons ajouter, alors la valeur est mise à jour avec la nouvelle valeur. Si la valeur est plus petite, alors l’opération est ignorée.
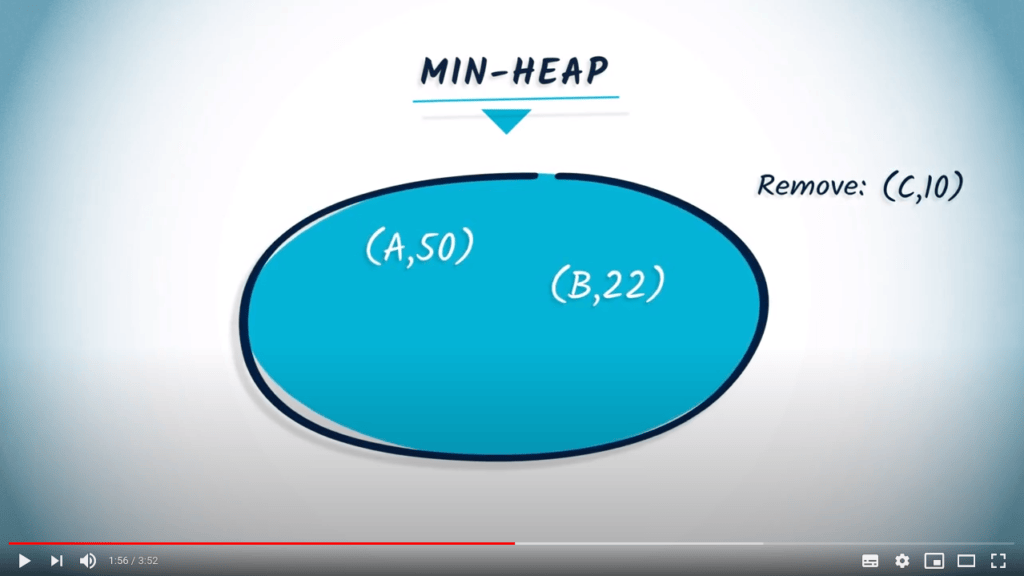
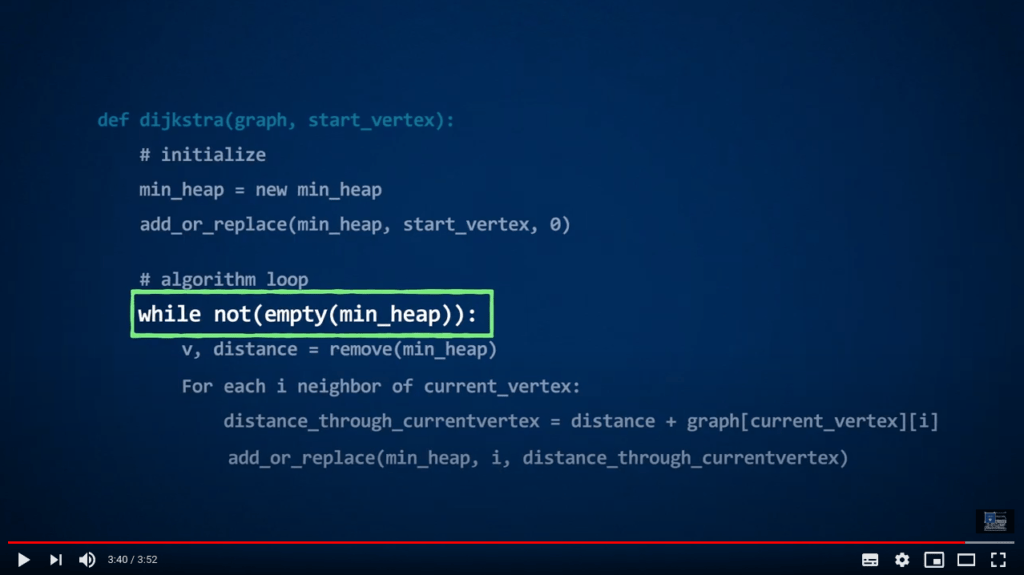
La deuxième opération élémentaire du min-heap est remove, qui retournera le couple (key, value) correspondant à la valeur minimale dans le min-heap.
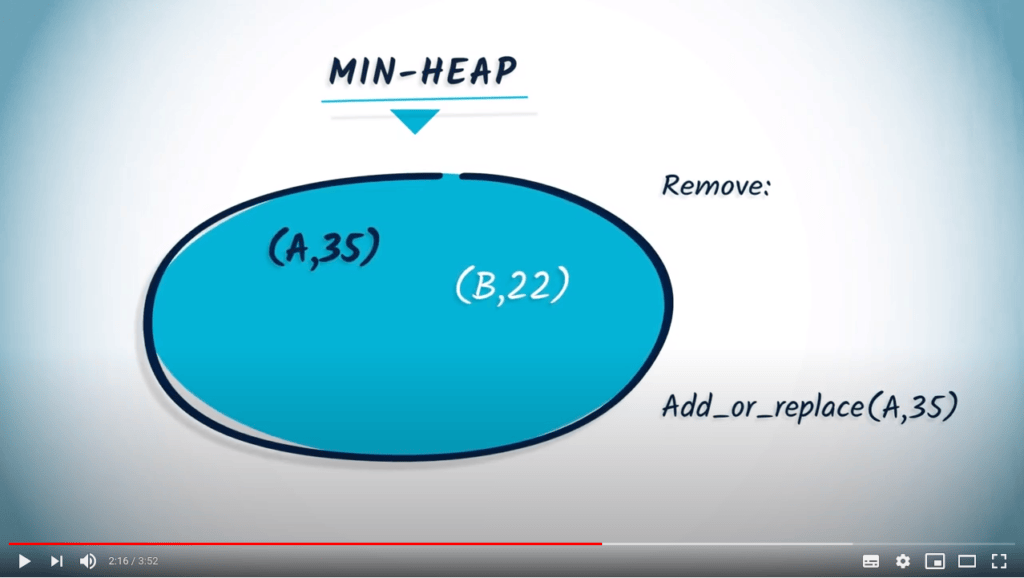
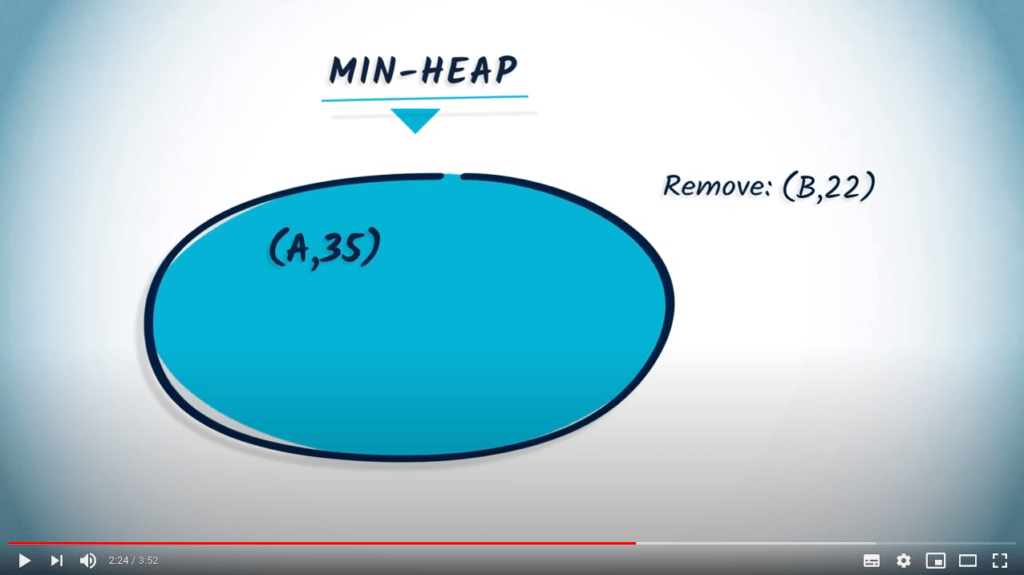
Compris ? Voyons maintenant comment utiliser un min-heap pour implémenter l’algorithme de Dijkstra.
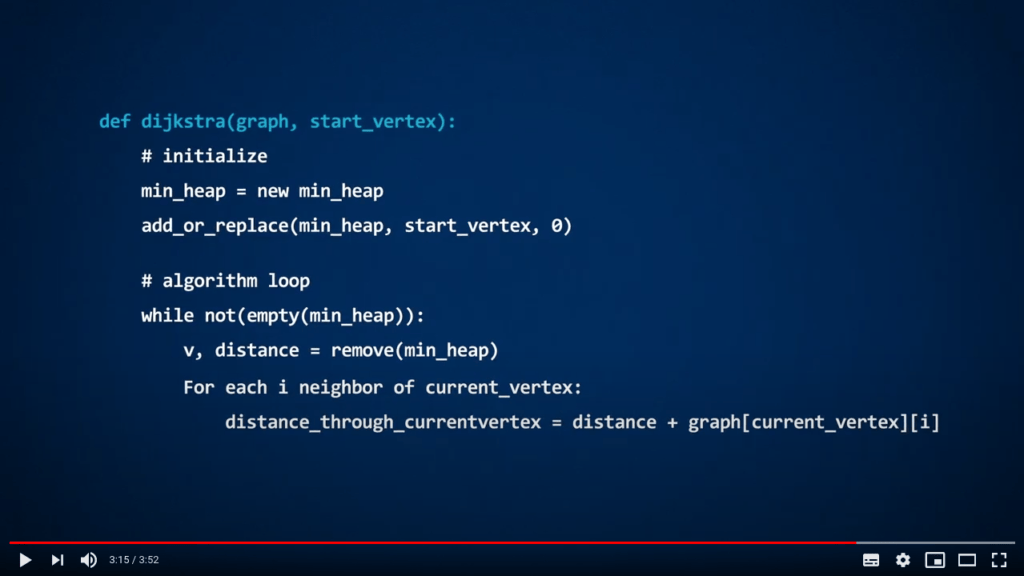
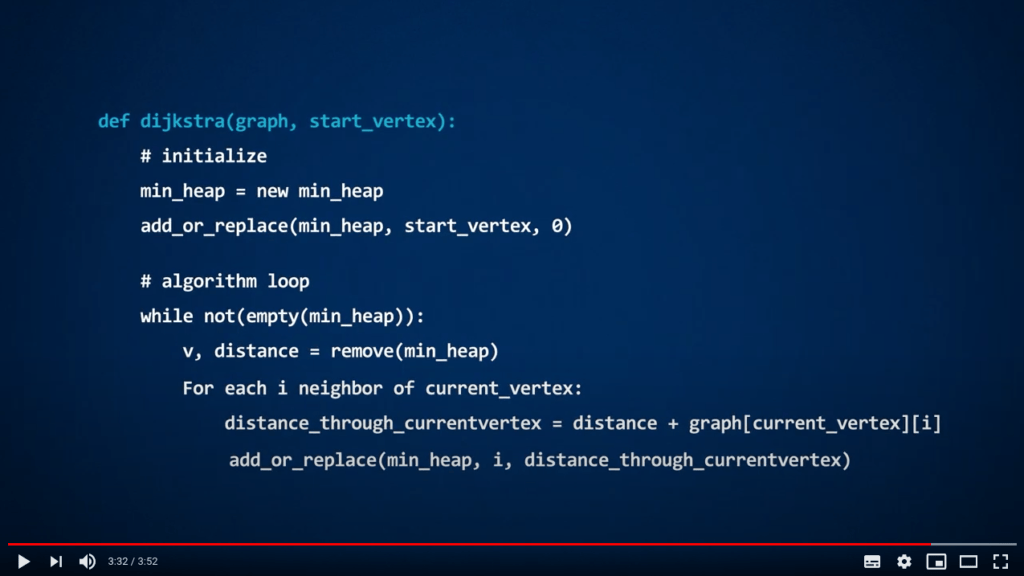
Dijkstra avec un min-heap
Le but de l’algorithme de Dijkstra est de trouver les plus courts chemins entre une position de départ et tous les autres sommets dans un graphe pondéré. Pour implémenter cet algorithme en utilisant un min-heap, il suffit d’ajouter les sommets comme clés, et les distances à la position de départ comme valeurs associées.
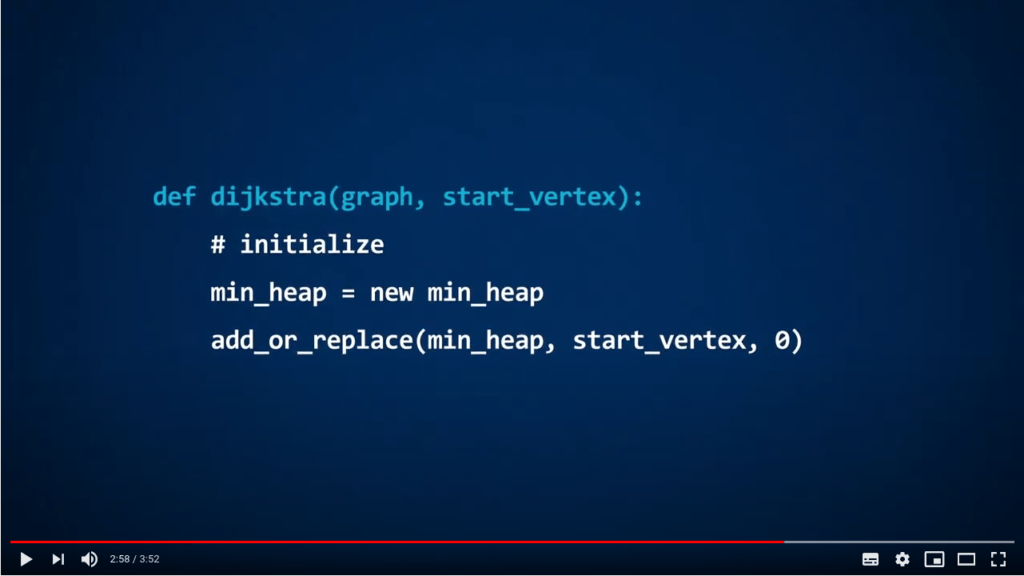
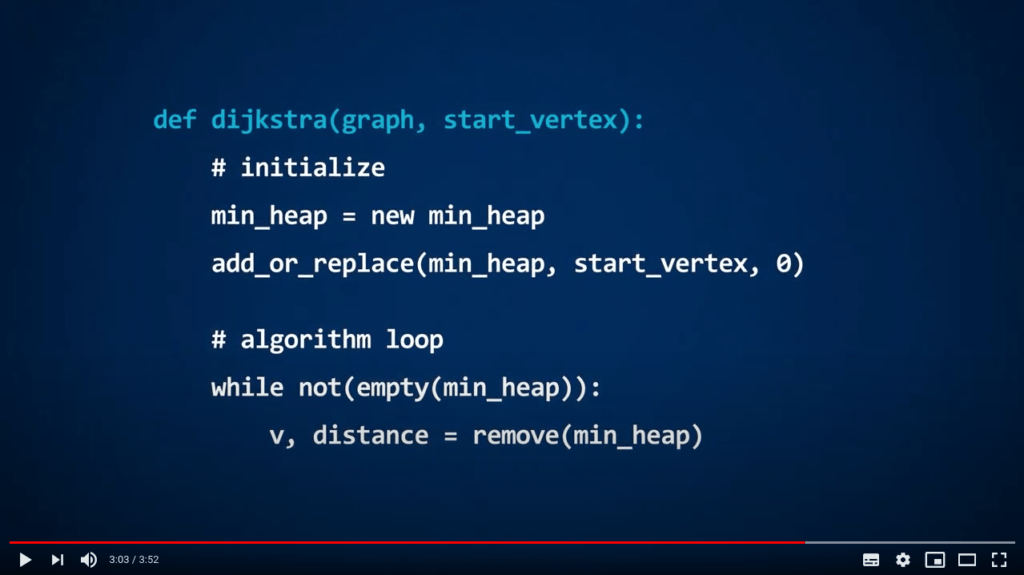
Mots de conclusion
Voilà, c’est tout pour aujourd’hui, à la prochaine vidéo !
Voici quelques remarques importantes sur cette vidéo :
-
Dans cette vidéo, nous avons utilisé les termes “key” (la chose que nous voulons stocker) et “value” (son importance dans le tas). D’autres terminologies existent ! Le seul aspect important est que
removedoit retourner l’élément minimum du tas. Attention à la façon dont ce minimum est calculé ! -
Dans la vidéo, une possible implémentation de l’algorithme de Dijkstra est présentée, qui utilise une fonction appelée
add_or_replace. Ici, nous vous expliquons simplement ce que fait cette fonction mais ne fournissons pas son code. En implémentant l’algorithme en Python, vous devrez créer une telle fonction, ou penser autrement…
Pour aller plus loin
2 — Une implémentation naïve d’un min-heap utilisant une liste
Une façon simple (mais assez inefficace) d’implémenter un min-heap est d’utiliser une liste. Cette liste stocke des paires (key, value). Ici, nous montrons comment créer un min-heap en utilisant une liste.
Créons une classe pour notre min-heap naïf. Cela permettra de créer un nouveau min-heap, et d’effectuer des opérations dessus :
class ListBasedMinHeap ():Dans le constructeur de notre classe, nous créons un attribut pour stocker les éléments. Dans cette implémentation, nous créons simplement une liste vide :
def __init__ (self):
# We create an attribute to store the elements
self.elements = []Maintenant, nous devons définir les deux méthodes présentées dans la vidéo : add_or_replace et remove.
Commençons par la première.
Nous allons procéder comme suit :
- D’abord, nous vérifions si la liste contient la clé que nous voulons ajouter.
- Si c’est le cas, et que la valeur associée est plus grande que la valeur que nous voulons ajouter, nous la supprimons.
- Enfin, nous ajoutons la paire (key, value) que nous voulons stocker si nécessaire.
Cela correspond au code suivant :
def add_or_replace (self, key, value):
# We check if the key is already in the heap
index = None
for i in range(len(self.elements)):
if self.elements[i][0] == key:
index = i
break
# If the key is already in the heap, we remove the previous element if the new value is lower
add_new_element = True
if index is not None:
if value < self.elements[index][1]:
del self.elements[index]
else:
add_new_element = False
# We add the new element
if add_new_element:
self.elements.append((key, value))En termes de complexité, cette implémentation doit parcourir toute la liste des éléments. Comme cette liste peut contenir jusqu’à $n$ éléments, où $n$ est le nombre de sommets dans le graphe, sa complexité est $O(n)$.
Maintenant, pour retirer un élément, comparons simplement les valeurs de tous les éléments dans la liste, et retournons celui avec la plus petite valeur :
def remove (self):
# We find the element with the smallest value
min_index = 0
for i in range(1, len(self.elements)):
if self.elements[i][1] < self.elements[min_index][1]:
min_index = i
# We remove the element with the smallest value
key, value = self.elements[min_index]
del self.elements[min_index]
# We return the key and value of the element removed
return key, valueEn termes de complexité, cette implémentation est de complexité $O(n)$ pour les mêmes raisons que ci-dessus.
Testons notre min-heap avec le même exemple que dans la vidéo :
# Create a min-heap
heap = ListBasedMinHeap()
# Add elements to the heap
heap.add_or_replace("A", 50)
heap.add_or_replace("B", 22)
heap.add_or_replace("C", 10)
# Show the elements of the heap
print("Heap initial state:", heap.elements)
# Remove the element with the smallest value
key, value = heap.remove()
print("Removed:", key, value)
print("Heap after remove():", heap.elements)
# Add a new element to the heap
heap.add_or_replace("B", 45)
print("Heap after add_or_replace(B, 45):", heap.elements)
# Add a new element to the heap
heap.add_or_replace("A", 35)
print("Heap after add_or_replace(A, 35):", heap.elements)
# Remove the element with the smallest value
key, value = heap.remove()
print("Removed:", key, value)
print("Heap after remove():", heap.elements)Voici la sortie produite :
Heap initial state: [('A', 50), ('B', 22), ('C', 10)]
Removed: C 10
Heap after remove(): [('A', 50), ('B', 22)]
Heap after add_or_replace(B, 45): [('A', 50), ('B', 22)]
Heap after add_or_replace(A, 35): [('B', 22), ('A', 35)]
Removed: B 22
Heap after remove(): [('A', 35)]Vous voulez essayer vous-même ? Voici une implémentation de cette classe.
3 — Une meilleure implémentation
Eh bien, $n$ opérations pour ajouter un élément, et $n$ opérations pour en retirer un, ce n’est pas très efficace.
Ainsi, la complexité de l’implémentation naïve de add_or_replace impacte la performance du code et la consommation d’énergie.
Il est assez évident que l’on peut faire mieux, par exemple en gardant la liste triée, de sorte que remove doive toujours retourner le premier élément.
Avec une telle adaptation, remove aurait une complexité de $O(1)$, au prix d’un surcoût computationnel dans add_or_replace.
En pratique, il existe des solutions encore meilleures, basées sur des structures de données plus complexes.
En Python, on peut utiliser une bibliothèque appelée heapq.
Cette bibliothèque vous fournit deux méthodes :
heappush, qui ajoute un élément au min-heap.heappop, qui retire l’élément minimum du min-heap.
Voyons ce qui se passe avec le même exemple que dans la vidéo :
# Import heapq
import heapq
# Create a min-heap
heap = []
# Add elements to the heap
heapq.heappush(heap, ("A", 50))
heapq.heappush(heap, ("B", 22))
heapq.heappush(heap, ("C", 10))
# Show the elements of the heap
print("Heap initial state:", heap)
# Remove the element with the smallest value
key, value = heapq.heappop(heap)
print("Removed:", key, value)
print("Heap after heappop():", heap)
# Add a new element to the heap
heapq.heappush(heap, ("B", 45))
print("Heap after heappush(B, 45):", heap)
# Add a new element to the heap
heapq.heappush(heap, ("A", 35))
print("Heap after heappush(A, 35):", heap)
# Remove the element with the smallest value
key, value = heapq.heappop(heap)
print("Removed:", key, value)
print("Heap after heappop():", heap)Cela semble assez similaire à ce que nous avions avant, non ? Voyons la sortie :
Heap initial state: [('A', 50), ('B', 22), ('C', 10)]
Removed: A 50
Heap after heappop(): [('B', 22), ('C', 10)]
Heap after heappush(B, 45): [('B', 22), ('C', 10), ('B', 45)]
Heap after heappush(A, 35): [('A', 35), ('B', 22), ('B', 45), ('C', 10)]
Removed: A 35
Heap after heappop(): [('B', 22), ('C', 10), ('B', 45)]Cela ne semble pas tout à fait correct finalement.
En fait, ce que fait cette bibliothèque, c’est qu’elle retourne l’élément minimum parmi ceux qui ont été ajoutés.
Ici, les éléments sont des paires, donc heapq va déterminer quelle paire est la minimum en vérifiant leur contenu dans l’ordre lexicographique, c’est-à-dire le premier élément de la paire, puis le second.
Dans l’exemple ci-dessus, les comparaisons sont faites sur "A", "B" et "C" plutôt que sur les valeurs numériques, qui ne sont utilisées que lorsqu’il y a égalité sur la première entrée.
Corrigeons cela en inversant les clés et les valeurs :
# Import heapq
import heapq
# Create a min-heap
heap = []
# Add elements to the heap
heapq.heappush(heap, (50, "A"))
heapq.heappush(heap, (22, "B"))
heapq.heappush(heap, (10, "C"))
# Show the elements of the heap
print("Heap initial state:", heap)
# Remove the element with the smallest value
value, key = heapq.heappop(heap)
print("Removed:", key, value)
print("Heap after heappop():", heap)
# Add a new element to the heap
heapq.heappush(heap, (45, "B"))
print("Heap after heappush(45, B):", heap)
# Add a new element to the heap
heapq.heappush(heap, (35, "A"))
print("Heap after heappush(35, A):", heap)
# Remove the element with the smallest value
value, key = heapq.heappop(heap)
print("Removed:", key, value)
print("Heap after heappop():", heap)Voyons la sortie :
Heap initial state: [(10, 'C'), (50, 'A'), (22, 'B')]
Removed: C 10
Heap after heappop(): [(22, 'B'), (50, 'A')]
Heap after heappush(45, B): [(22, 'B'), (50, 'A'), (45, 'B')]
Heap after heappush(35, A): [(22, 'B'), (35, 'A'), (45, 'B'), (50, 'A')]
Removed: B 22
Heap after heappop(): [(35, 'A'), (50, 'A'), (45, 'B')]C’est déjà mieux, mais il semble que heappop ne réalise pas d’opération de remplacement lorsque la clé existe déjà.
En effet, il se contente d’ajouter des éléments à une structure, et n’a pas de réelle notion de “clés” ou “valeurs”.
Il a juste la propriété de retourner l’élément minimum lorsqu’on le lui demande.
Alors, comment pouvons-nous utiliser cela pour implémenter l’algorithme de Dijkstra ? En fait, il est possible d’adapter simplement l’algorithme que vous avez vu dans le cours. En effet, lorsqu’un sommet est extrait du min-heap, vous savez que vous avez trouvé le plus court chemin vers ce sommet. Ainsi, si vous extrayez plus tard le même sommet, vous savez que c’est un chemin plus long vers lui, vous pouvez donc simplement l’ignorer !
Cela ne nous dit pas si cette solution est meilleure que la solution naïve.
En fait, heapq est un tas binaire, et heappush et heappop ont une complexité de $O(log_2(n))$, ce qui est inférieur à $O(n)$.
Voir plus de détails ci-dessous si vous le souhaitez.
4 — Implémentation utilisant un arbre binaire équilibré
4.1 — Définitions
Commençons par quelques définitions. Vous devriez déjà savoir ce qu’est un arbre, et ce que nous appelons sa racine. Un sommet dans un arbre est un “nœud” s’il a des voisins plus éloignés de la racine de l’arbre (que nous appelons enfants). Sinon, c’est une “feuille”.
La “profondeur” d’un arbre est la longueur du plus long plus court chemin partant de la racine. Un arbre est “équilibré” si tous ses plus courts chemins partant de la racine ont la même longueur, $\pm 1$.
4.2 — Le modèle d’arbre
Au lieu d’utiliser une liste, il est proposé d’utiliser un arbre binaire équilibré avec les propriétés suivantes :
- Chaque nœud de l’arbre est associé à un couple (key, value). Cette propriété permet de lier l’arbre aux éléments à stocker/extraire.
- Chaque nœud parent a deux enfants, sauf si le nombre total d’éléments dans la file de priorité est pair, auquel cas un seul nœud a un enfant unique et tous les autres en ont deux.
- L’arbre est équilibré. Cette propriété garantit que l’arbre n’a pas une forme similaire à une longue chaîne, formant une sorte de liste, perdant ainsi tout l’intérêt d’utiliser des arbres.
- La valeur d’un parent est toujours plus petite que celle de ses enfants. Cette propriété essentielle garantit que le nœud de valeur minimale est toujours à la racine.
Des arbres ternaires/quaternaires/etc. auraient aussi pu être envisagés (cela change le nombre d’enfants). À mesure que le nombre d’enfants augmente, la complexité de l’opération d’insertion diminue, mais la complexité de l’extraction augmente.
4.3 — Création
Pour initialiser une telle file de priorité, il suffit de retourner un arbre vide.
4.4 — Insertion
Pour insérer un couple (key, value) dans l’arbre, procédez comme suit :
- Le couple (key, value) est ajouté à la fin de l’arbre, c’est-à-dire :
- Si tous les nœuds parents ont deux enfants, une feuille de profondeur minimale est transformée en parent de ce nœud.
- Si un nœud parent n’a qu’un enfant, il est ajouté comme second enfant de ce nœud.
-
Si la valeur de ce nouveau nœud est plus petite que celle de son parent, les couples (key, value) du nœud et de son parent sont échangés.
-
On continue en remontant l’arbre autant que nécessaire.
Puisque nous ne faisons que remplacer des éléments dans l’arbre par d’autres de valeurs plus petites, l’arbre résultant conserve les propriétés énoncées si l’arbre d’origine les avait.
4.5 — Extraction
Pour récupérer un élément, procédez comme suit :
- Le couple (key, value) associé à la racine de l’arbre est retourné.
- On le remplace par une feuille de profondeur maximale de l’arbre.
- Si la nouvelle racine a une valeur plus grande que l’un de ses enfants, le couple (key, value) est échangé avec l’enfant de plus petite valeur.
- On recommence en descendant autant que nécessaire.
Là encore, il est facile de vérifier que l’arbre résultant respecte les propriétés énoncées si l’arbre de départ les respectait aussi.
4.6 — Complexité
La complexité des opérations d’insertion et d’extraction nécessite de parcourir de la racine à une feuille de profondeur maximale dans le pire des cas. L’arbre étant binaire, cela représente $log_2(n)$ opérations, où $n$ est le nombre d’éléments dans la file. Nous sommes donc bien moins complexes qu’avec une implémentation naïve utilisant une liste (où le nombre d’opérations était au moins linéaire en $n$).
Pour aller plus loin
-
Une liste plus complète de structures de priorité.
Le min-heap n’est qu’un exemple de structures de données particulières qui donnent une importance particulière à certains éléments.
-
Les structures de priorité aident à développer des heuristiques pour visiter les voisins.
L’algorithme A* est quelque chose que vous pourriez vouloir essayer dans le projet.