Modèle relationnel et introduction à SQL
Durée1h15Présentation & objectifs
Dans cette activité, vous approfondirez votre compréhension du modèle relationnel et découvrirez les bases du SQL (Structured Query Language). À la fin de cette session, vous serez capable de :
- Comprendre et appliquer les concepts de clés primaires et étrangères dans un contexte pratique
- Créer des tables SQL simples avec des contraintes d’intégrité
- Écrire des requêtes SQL basiques pour interroger et manipuler des données
- Analyser l’impact des contraintes d’intégrité sur les opérations de la base de données
Accès à la base de données
Pour accéder à la base de données vous allez vous connecter à l’espace JupyterHub qui contient déjà toutes les données nécessaires et les notebooks.
Accéder à la base de donnéesSi vous vous êtes connecté sur l’espace JupyterHub de l’UE avant le mail vous indiquant de créer votre espace, utilisez la procédure suivante.
- Pour réinitialiser la base de données : à la base de vos dossier JupyterHub créez un nouveau fichier nommé
resetdb - Pour réinitialiser votre espace de travail : à la base de vos dossier JupyterHub créez un nouveau fichier nommé
resetworkspace. Attention tout sera effacé ! Sauvegardez ce que vous désirez conserver. - Ensuite il faut redémarrer le serveur :
Menu File>Hub Control PanelStop my serverpuisStart My Server
Ne téléchargez les fichiers suivants que si vous désirez les consulter hors de JupyterHub.
{kind=link}
Contexte
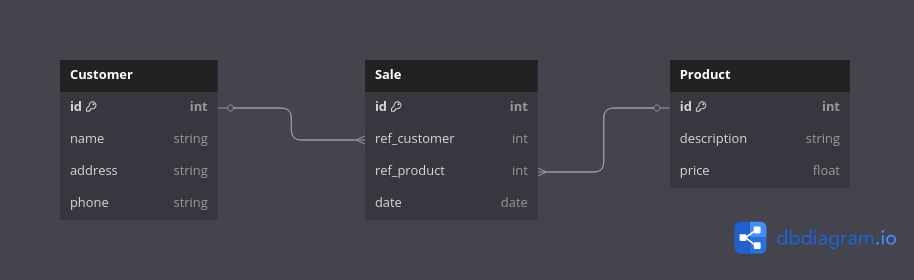
Cette activité s’appuie sur le modèle de données que vous avez exploré dans l’activité précédente, concernant les clients, les produits et les ventes d’une entreprise de vente en ligne. Votre tâche est d’utiliser SQL pour interagir avec cette base de données, en vous concentrant sur l’intégrité des données et les relations entre les tables.
La base de données SALES contient les tables Customer, Product et Sale. Vous utiliserez ces tables pour effectuer diverses opérations SQL, en assurant l’intégrité des données tout au long du processus.
Customer (id, name, address, phone)
Product (id, description, price)
Sale (id, ref_customer, ref_product, date) où ref_customer référence Customer(id) et ref_product référence Product(id)
Table Customer {
id int [pk]
name varchar(100)
address text
phone varchar(20)
}
Table Product {
id int [pk]
description text
price decimal(10,2)
}
Table Sale {
id int [pk]
ref_customer int [ref: > Customer.id]
ref_product int [ref: > Product.id]
date date
}DBML (Database Markup Language) est un langage simple et lisible pour définir des schémas de base de données. Il est utilisé pour créer des diagrammes visuels de base de données et pour générer du SQL. Vous pouvez utiliser des outils comme dbdiagram.io pour travailler avec DBML.
Création des tables
La syntaxe générale pour créer une table en SQL est la suivante :
CREATE TABLE table_name (
column1_name data_type constraints,
column2_name data_type constraints,
...
CONSTRAINT constraint_name PRIMARY KEY (column1),
CONSTRAINT constraint_name FOREIGN KEY (column) REFERENCES other_table(column)
);Exemple : Création d’une table Supplier
CREATE TABLE Supplier (
id INT PRIMARY KEY,
name VARCHAR(100) NOT NULL,
contact_person VARCHAR(100),
email VARCHAR(100) UNIQUE
);Dans cet exemple :
idest défini comme clé primairenamene peut pas ne être définie (contrainteNOT NULL)emaildoit être unique pour chaque fournisseur
Exercice 1 : Créez une nouvelle table nommée Category avec les colonnes suivantes :
id(entier, clé primaire)name(chaîne de caractères devant être définie)description(chaîne de caractères)
Assurez-vous d’utiliser les types de données appropriés et d’ajouter les contraintes nécessaires.
Exercice 2 : Après avoir créé la table Category, représentez le schéma complet de la base de données en utilisant le DBML. Écrivez le code DBML pour toutes les tables de la base de données, incluant Customer, Product, Sale, Supplier et la nouvelle table Category.
SELECT et WHERE : Les bases de la sélection
La syntaxe générale pour interroger une table en SQL est la suivante :
SELECT columns
FROM table
[WHERE condition]
[GROUP BY columns [HAVING condition]]
[ORDER BY columns [ASC|DESC]];SELECT nous permet de choisir les colonnes que nous voulons voir, tandis que WHERE filtre les lignes selon certaines conditions.
Recherche de motifs avec LIKE
L’opérateur LIKE est utilisé pour la recherche de motifs dans les chaînes. Il utilise deux caractères spéciaux :
%représente zéro, un ou plusieurs caractères_représente un seul caractère
Exemple :
SELECT name, phone
FROM Customer
WHERE address LIKE '%Paris%';Cette requête trouve tous les clients dont l’adresse contient Paris.
Exercice 3 : Écrivez une requête pour trouver tous les produits dont la description contient le mot Ordinateur portable.
Utilisation des opérateurs de comparaison
Les opérateurs de comparaison (<, >, <=, >=, =, <>) peuvent être utilisés pour filtrer les résultats basés sur des valeurs numériques ou des dates.
Exemple : Tous les produits dont le prix est supérieur à 100.
SELECT *
FROM Product
WHERE price > 100;Afin d’exprimer une contrainte sur les dates vous devez exprimer la date avec la syntaxe suivante : to_date('31/12/2030', 'dd/mm/yyyy') pour le 31 décembre 2030, par exemple.
Exercice 4 : Écrivez une requête pour trouver toutes les ventes effectuées avant le 1er janvier 2024.
Les jointures
Les jointures permettent de combiner des données de plusieurs tables. Il existe plusieurs types de jointures, mais la plus courante est la jointure interne.
Exemple : Jointure entre les tables Sale, Customer et Product.
SELECT c.name, p.description, s.date
FROM Sale s
JOIN Customer c ON s.ref_customer = c.id
JOIN Product p ON s.ref_product = p.id;Exercice 5 : Écrivez une requête pour afficher le nom du client, le prix du produit et la date pour toutes les ventes où le prix du produit est supérieur à 500.
Modification de la structure des tables
La commande ALTER TABLE permet de modifier la structure d’une table existante. Voici quelques opérations courantes :
-
Ajouter une nouvelle colonne :
ALTER TABLE table_name ADD COLUMN column_name data_type constraints; -
Modifier une colonne existante :
ALTER TABLE table_name ALTER COLUMN column_name SET constraints; -
Ajouter une contrainte :
ALTER TABLE table_name ADD CONSTRAINT constraint_name constraint_definition;
Plusieurs types de contraintes peuvent être ajoutés à une table. Remplacez constraints par :
PRIMARY KEY: Identifie de manière unique chaque enregistrementFOREIGN KEY: Établit une relation avec une autre table (voir exemple ci-dessous)UNIQUE: Assure que toutes les valeurs d’une colonne sont différentesNOT NULL: Empêche l’insertion de valeurs NULLCHECK (condition): Vérifie qu’une condition est respectée pour toutes les lignes
Exemple d’ajout d’un nouveau champ qui est aussi une clé étrangère :
ALTER TABLE Product
ADD COLUMN ref_category INT,
ADD CONSTRAINT fk_category
FOREIGN KEY (ref_category)
REFERENCES Category(id);Exemple d’une contrainte pour vérifier une condition sur un attribut :
ALTER TABLE Employee
ADD CONSTRAINT chk_salary_positive
CHECK (salary > 0);Exercice 6 : Modifiez la table Customer pour ajouter une contrainte assurant que le numéro de téléphone est défini et n’est pas une chaîne de caractère vide.
Intégrité des données
L’intégrité des données est maintenue grâce aux contraintes de clés primaires et étrangères. Voici comment insérer des données dans une table :
INSERT INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...);Exercice 7 : Essayez d’insérer un nouveau produit avec un ref_category qui n’existe pas dans la table Category. Que se passe-t-il ?
Exercice 8 : Maintenant, essayez d’insérer un produit sans spécifier de ref_category. Que se passe-t-il ? Expliquez le résultat.
Négation
La négation en SQL permet de trouver les enregistrements qui ne correspondent pas à certains critères.
Exemple : Tous les clients qui n’ont jamais fait d’achat.
SELECT c.name
FROM Customer c
WHERE c.id NOT IN (SELECT DISTINCT ref_customer FROM Sale);Exercice 9 : Écrivez une requête pour trouver tous les produits qui n’ont jamais été vendus.
Comptages et agrégations
Les fonctions d’agrégation comme COUNT(), SUM(), AVG(), MAX(), MIN() permettent d’effectuer des calculs sur un ensemble de valeurs. Ces fonctions sont souvent utilisées avec la clause GROUP BY qui permet de regrouper les résultats par une ou plusieurs colonnes.
La clause GROUP BY
La clause GROUP BY permet de regrouper les lignes ayant les mêmes valeurs dans les colonnes spécifiées et de calculer des statistiques pour chaque groupe.
Syntaxe:
SELECT colonne1, colonne2, ..., fonction_agrégation(colonneX)
FROM table
GROUP BY colonne1, colonne2, ...;Points importants:
- Toute colonne dans le
SELECTqui n’est pas dans une fonction d’agrégation doit apparaître dans leGROUP BY - L’ordre des colonnes dans
GROUP BYn’affecte pas le résultat - Peut être utilisé avec plusieurs colonnes pour créer des sous-groupes plus précis
Exemple :
Supposons que nous ayons les données suivantes dans la table Sale :
| id | ref_customer | ref_product | date |
|---|---|---|---|
| 1 | 101 | 201 | 2024-01-15 |
| 2 | 102 | 202 | 2024-01-20 |
| 3 | 101 | 203 | 2024-02-05 |
| 4 | 103 | 201 | 2024-02-10 |
| 5 | 102 | 201 | 2024-02-15 |
| 6 | 101 | 202 | 2024-03-01 |
Et dans la table Product :
| id | description | price |
|---|---|---|
| 201 | Ordinateur portable | 1200.00 |
| 202 | Smartphone | 800.00 |
| 203 | Tablette | 500.00 |
Si nous voulons compter le nombre de ventes par client, nous pouvons utiliser la requête suivante :
SELECT ref_customer, COUNT(*) as nb_achats
FROM Sale
GROUP BY ref_customer;Voici comment fonctionne l’agrégation :
- Les lignes sont d’abord regroupées par
ref_customer:
| Groupe : ref_customer = 101 | |||
|---|---|---|---|
| id | ref_customer | ref_product | date |
| 1 | 101 | 201 | 2024-01-15 |
| 3 | 101 | 203 | 2024-02-05 |
| 6 | 101 | 202 | 2024-03-01 |
| Groupe : ref_customer = 102 | |||
|---|---|---|---|
| id | ref_customer | ref_product | date |
| 2 | 102 | 202 | 2024-01-20 |
| 5 | 102 | 201 | 2024-02-15 |
| Groupe : ref_customer = 103 | |||
|---|---|---|---|
| id | ref_customer | ref_product | date |
| 4 | 103 | 201 | 2024-02-10 |
- Puis la fonction d’agrégation
COUNT(*)est appliquée à chaque groupe :
| ref_customer | nb_achats |
|---|---|
| 101 | 3 |
| 102 | 2 |
| 103 | 1 |
Pour combiner les données de plusieurs tables, on peut utiliser des jointures avec GROUP BY :
SELECT c.name, COUNT(*) as nb_achats, SUM(p.price) as total_depense
FROM Sale s
JOIN Customer c ON s.ref_customer = c.id
JOIN Product p ON s.ref_product = p.id
GROUP BY c.name;Cette requête regroupe les ventes par nom de client et calcule le nombre d’achats et le montant total dépensé par chaque client.
Nous pouvons aussi filtrer les résultats après l’agrégation avec la clause HAVING :
SELECT ref_customer, COUNT(*) as nb_achats
FROM Sale
GROUP BY ref_customer
HAVING COUNT(*) > 2;Cela nous donnera uniquement les clients ayant effectué plus de 2 achats :
| ref_customer | nb_achats |
|---|---|
| 101 | 3 |
Exercice 10 : Écrivez une requête pour trouver le montant moyen des ventes par produit. Utilisez la fonction AVG() et groupez par ref_product.