Phase 1 : La piste du hacker
Durée60 minutesVous devez impérativement faire au minimum un resetdb avant de commencer cette activité.
- Pour réinitialiser la base de données : à la base de vos dossier JupyterHub créez un nouveau fichier nommé
resetdb - Ensuite il faut redémarrer le serveur :
Menu File>Hub Control PanelStop my serverpuisStart My Server
Mission
Une série d’alertes de sécurité a été déclenchée sur la plateforme de commerce en ligne BreizhDiscount. Les logs système indiquent une potentielle attaque coordonnée impliquant des tentatives de force brute sur les connexions, une création suspecte de comptes et des transactions frauduleuses.
En tant qu’expert sécurité, vous devez analyser les logs système pour identifier le point d’entrée de l’attaquant, comprendre sa méthode d’exploitation et évaluer l’étendue de la compromission.
Énigme 1 : Les tentatives de connexion
Objectif 1 : Identification des attaques par force brute
Situation : Le système de monitoring a déclenché une alerte suite à deux pics inhabituels d’échecs de connexion le 15 mars 2024. Ces pics contrastent fortement avec le pattern habituel d’échecs de connexion observé les jours précédents.
Mission : Pour confirmer cette hypothèse, vous devez analyser les logs de connexion à partir du 15 mars 2024 et identifier les adresses IP ayant effectué plus de 4 tentatives de connexion échouées, signature typique d’une attaque par force brute.
Dans le monde réel, les attaques par force brute sont une menace courante pour les e-commerces. Les attaquants utilisent des outils automatisés qui tentent des milliers de combinaisons de mots de passe en quelques minutes. La détection rapide de ces tentatives est cruciale pour protéger les comptes clients et prévenir les fraudes.
Pour valider cet objectif, notez le plus grand nombre de tentatives de connexion échouées pour une même adresse IP depuis le 15 mars.
Objectif 2 : Analyse de la distribution temporelle
Situation : Les premières analyses suggèrent que l’attaquant utilise un script automatisé avec un timing précis pour éviter la détection. Cette régularité dans les tentatives peut nous aider à différencier le trafic malveillant du trafic légitime.
Mission : Analysez la distribution temporelle des tentatives de connexion échouées pour identifier les patterns suspects. Vous devez identifier les pics d’activité minute par minute et visualiser la distribution pour repérer les séquences trop régulières pour être humaines.
Les outils d’attaque automatisés laissent souvent des signatures temporelles distinctives. Alors que les utilisateurs légitimes ont des intervalles irréguliers entre leurs tentatives, les bots maintiennent souvent un rythme constant. Cette différence est un indicateur clé utilisé par les systèmes de détection d’intrusion modernes.
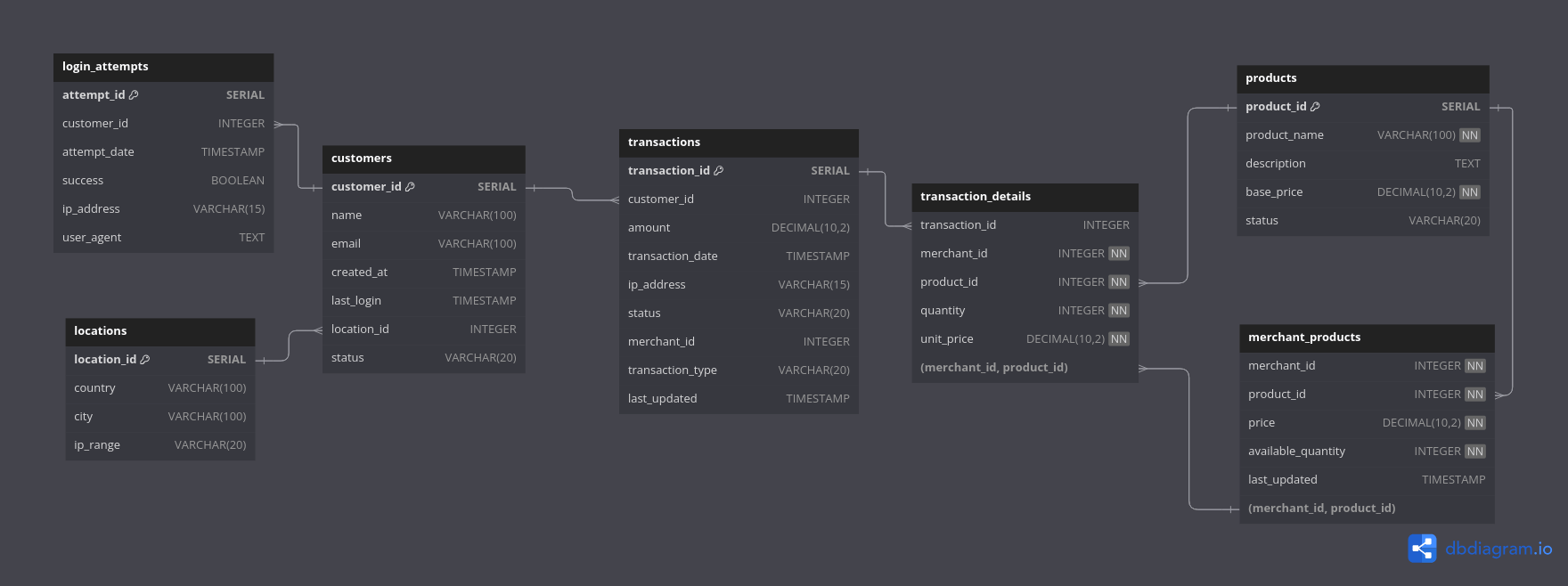
Commençons par analyser cette requête qui compte le nombre de tentatives de connexion par heure pour chaque adresse IP. Cette requête servira de base pour notre analyse mais elle manque des éléments importants pour détecter les comportements suspects :
SELECT
ip_address,
attempt_date::timestamp::date as date,
EXTRACT(HOUR FROM attempt_date) as heure,
COUNT(*) as nb_tentatives
FROM login_attempts
GROUP BY
ip_address,
attempt_date::timestamp::date,
EXTRACT(HOUR FROM attempt_date)
ORDER BY nb_tentatives DESC;Vous avez à votre disposition un script permettant de visualiser le nombre de connexions au cours du temps. Celui-ci nécessite cependant uniquement les champs suivants : date, heure, minute, nb_tentatives.
Modifiez cette requête pour produire les données nécessaire au script. Pour cela :
- Supprimez les champs inutiles
- Ajoutez le comptage par minute
- Gardez uniquement les échecs de connexion entre le 14 et le 16 mars
Dans votre notebook Jupyter, commencez par exécuter votre requête dans une première cellule en utilisant la syntaxe %%sql et observez le résultat.
Pour vous aider à visualiser le résultat, nous vous proposons dans le notebook (ou ci-dessous) un script python pour traiter le dataframe produit par votre requête. Pour cela remplacez juste avant votre requête le code %%sql par %%sql result1 << afin de charger le résultat dans la variable result1.
Adaptez votre requête pour visualiser plus clairement la période de quelques heures avant et après l’attaque.
Pour valider cet objectif, notez le nombre de périodes de 30 minutes durant lesquelles les attaques ont eu lieu (nombre de tentatives de connexions échouées supérieur à 10).
Validez vos réponses
Énigme 2 : Analyse des comptes corrompus
Objectif 1 : Détection des connexions simultanées
Situation : Suite à l’attaque par force brute, plusieurs comptes semblent avoir été compromis. Ces comptes montrent des connexions réussies depuis différentes localisations géographiques dans des intervalles de temps très courts.
Mission : Identifiez tous les comptes présentant des connexions réussies depuis des adresses IP différentes dans un intervalle de 30 minutes. Ce pattern indique généralement que plusieurs attaquants utilisent simultanément le même compte compromis.
Les connexions simultanées depuis des locations géographiques distinctes sont un indicateur majeur de compromission de compte. Les cybercriminels partagent souvent les identifiants volés sur des forums, conduisant à des utilisations simultanées par différents acteurs malveillants.
Pour valider cet objectif, filtrez les connexions à partir 15 mars minuit '2024-03-15 00:00:00' et triez par attempt_date la plus ancienne et customer_idcroissant.
Notez les 3 chiffres du premier customer_id qui apparait.
Objectif 2 : Identification des comptes suspects
Situation : L’analyse des logs révèle que les attaquants créent des variantes de comptes légitimes en insérant des points supplémentaires dans les adresses email (ex: “j.ohn.smith@email.com” pour “john.smith@email.com”). Ces comptes sont ensuite utilisés pour des transactions frauduleuses.
Mission : Identifiez toutes les transactions dépassant 1000€ effectuées par des comptes dont l’email présente ce pattern suspect de points multiples, afin d’évaluer l’ampleur de la fraude.
La technique du “dot fraud”, qui fonctionne avec certains fournisseurs de messagerie, est privilégiée par les fraudeurs car elle leur permet de gérer facilement de nombreux comptes frauduleux depuis une seule boîte mail, plutôt que de devoir surveiller des dizaines de boîtes différentes.
Pour valider cet objectif, notez le numéro de la transaction frauduleuse (transaction_id) ayant le plus haut montant.
Validez vos réponses
Énigme 3 : Les transactions suspectes
Objectif 1 : Détection des micro-transactions nocturnes
Situation : Après avoir compromis des comptes, les attaquants effectuent généralement des petites transactions test pour vérifier si les moyens de paiement associés sont toujours valides avant de procéder à des transactions plus importantes.
Mission : Identifiez les comptes dont toutes les transactions effectuées entre 1h et 5h du matin le 15 mars 2024 (période où l’activité légitime est minimale) ont un montant est strictement inférieur à 50€.
Les micro-transactions nocturnes sont une technique classique utilisée par les fraudeurs pour tester des cartes volées. En limitant les montants, ils évitent de déclencher les alertes basées sur les montants, tandis que le timing nocturne réduit les chances de détection immédiate par les propriétaires légitimes des cartes.
Pour valider cet objectif, notez le plus grand customer_id retourné par votre requête.
Objectif 2 : Distribution géographique des transactions suspectes
Situation : Les transactions frauduleuses présentent souvent des anomalies dans leur distribution géographique. Les attaquants utilisent un réseau d’adresses IP pour masquer leur activité, mais certains patterns géographiques peuvent les trahir.
Mission : Analysez la distribution géographique des transactions du 15 mars 2024 pour identifier les zones présentant des activités anormales de montant moyen, du volume de transaction par compte et de diversité d’adresses IP.
L’analyse géographique des transactions est un outil puissant dans la détection des fraudes. Des transactions importantes depuis des localisations inhabituelles ou des schémas de déplacement impossibles (comme des transactions simultanées dans des villes éloignées) sont des indicateurs fiables d’activité frauduleuse.
Pour démarrer cette analyse, vous disposez d’une requête qui calcule des statistiques clés par ville. Cette requête s’organise en deux temps : elle commence par agréger les données de transactions pour chaque ville (montants moyens, nombre de transactions par compte, nombre d’IPs par compte), puis elle classifie ces villes selon leur niveau de risque en se basant sur différents seuils d’alerte que vous allez devoir définir
WITH stats_par_ville AS (
-- Cette première partie calcule toutes les statistiques par ville
SELECT
l.city as ville,
l.country as pays,
COUNT(*) as nb_transactions,
COUNT(DISTINCT t.customer_id) as nb_comptes,
ROUND(AVG(t.amount)::numeric, 2) as montant_moyen,
COUNT(DISTINCT t.ip_address) as nb_ips,
-- Ratio : nombre de transactions par compte
ROUND(COUNT(*)::numeric / NULLIF(COUNT(DISTINCT t.customer_id), 0), 1) as ratio_tx_compte,
-- Ratio : nombre d'IPs différentes par compte
ROUND(COUNT(DISTINCT t.ip_address)::numeric / NULLIF(COUNT(DISTINCT t.customer_id), 0), 1) as ratio_ip_compte
FROM transactions t
JOIN locations l ON t.ip_address LIKE l.ip_range || '%'
WHERE t.transaction_date >= '2024-03-15'
GROUP BY l.city, l.country
HAVING COUNT(*) > 0
)
SELECT
ville,
pays,
nb_transactions as "nombre de transactions",
nb_comptes as "nombre de comptes",
montant_moyen as "montant moyen",
nb_ips as "nombre d'IPs",
ratio_tx_compte as "transactions par compte",
ratio_ip_compte as "ip par compte",
-- À vous d'implémenter le calcul du score de risque ici !
-- Il doit combiner trois CASE pour les différents critères
[votre code ici] as score_risque
FROM stats_par_ville
ORDER BY score_risque DESC;Cette requête doit être complétée pour calculer le score de risque et aider à détecter les activités frauduleuses.
Modifier cette rêquete pour que le score de risque soit la somme de ces trois composantes :
- Score basé sur le montant moyen (max 40 points)
- 40 points si montant_moyen > 2000€
- 20 points si montant_moyen > 1000€
- 0 points sinon
- Score basé sur le ratio transactions/compte (max 30 points)
- 30 points si ratio_tx_compte > 8 transactions/compte
- 15 points si ratio_tx_compte > 3 transactions/compte
- 0 points sinon
- Score basé sur le ratio IPs/compte (max 30 points)
- 30 points si ratio_ip_compte > 3 IPs/compte
- 15 points si ratio_ip_compte > 1 IP/compte
- 0 points sinon Score maximum possible : 100 points
Dans votre notebook Jupyter, commencez par exécuter votre requête dans une première cellule en utilisant la syntaxe %%sql et observez le résultat.
Pour vous aider à visualiser le résultat sur une carte, nous vous proposons dans le notebook (ou ci-dessous) un script python pour traiter le dataframe produit par votre requête. Pour cela remplacez juste avant votre requête le code %%sql par %%sql result2 << afin de charger le résultat dans la variable result2.
Sur cette carte interactive la taille des cercles représente le montant moyen des transactions et la couleur le niveau de risque.
Pour valider cet objectif, notez le nombre de zones avec un score de risque Élevé (supérieur à 70). Pensez à déplacer la carte ;)
Validez vos réponses
Votre prochain défi sera d’analyser et de maintenir la cohérence et l’intégrité des données du système après l’attaque.