A broad introduction to Deep Learning
Reading time10 minIn brief
Article summary
In this page, we give a very broad overview of Deep Learning (DL), a particularly succesfuly type of machine learning methods. DL is trained using automatic differentation of a large number of simple components called “layers”, directly from raw data.
Main takeaways
-
DL is a family of machine learning methods.
-
DL is based on compositions of simple functions called layers.
-
DL is learnt end-to-end from raw data, from no to little preprocessing. Feature extraction is done by the DL approach.
-
DL approaches are trained using automatic differentation.
Article contents
1 — Generalities on deep learning
Deep Learning is a set of techniques that are a particular case of ML, and are particularly successful in dealing with several types of data, such as images, language, audio, as well as more scientific fields such as biology or physics (see more specific examples in the page on applications). As a consequence, deep Learning has enabled a rapid progress of ML and AI as a whole, and as of today (2024) is the dominant paradigm in most AI tasks.
Deep Learning is based on three ingredients:
-
Compositionality – The function $f$ is estimated as a assembly of simple functions with few parameters (usually, a linear combination of all input dimensions, followed by non-linear functions), that are usually called layers.
-
End-to-end learning – Feature extraction is performed by the learned functions (as opposed to “expert defined” features).
-
Automatic differentiation – All functions are trained simultaneously by computing gradients of all layers’ outputs using (stochastic) gradient descent, by an algorithm called “back-propagation of gradients”.
2 — Modern architectures for deep learning
We will present here the most useful architectures in today’s DL practices. If you are interested in a historical perspective, there have been many developments and proposed architectures that you will find in the to go beyond below.
The types of functions that can be combined (or “layers”) are quite diverse. In this section, we present only the most common ones.
In every layer, the linear combinations are often followed by a bias term to scale the value around, before applying a non-linear function, such as the sigmoid function, or the “rectified linear unit” (ReLU). The ReLu is the maximum between 0 and the input value.
2.1 — Fully-connected layers
Fully connected layers consider a cascade of layers for which each layer is computed with a linear combination of all dimensions of the previous layer. For example, here is an example consisting in $L$ layers.
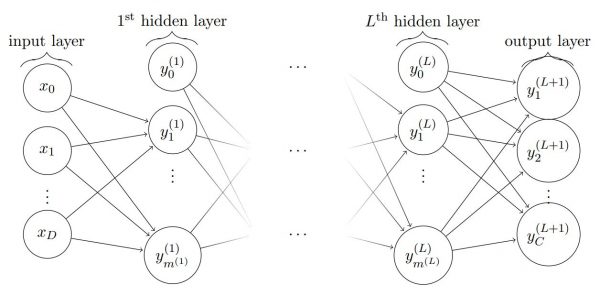
Models that only include such layers are generally called multi-layer perceptrons (MLP). However, these layers often appear in other types of models.
2.2 — Convolutional neural networks (CNN)
CNN consider that weights can be shared between several input dimensions. This is particularly relevant with data that exhibit regularities in their structure, such as images or audio. CNN are based on classical signal processing that use a small set of values, defined as a kernel, to process a large input.
In the 2D case, a 3x3 convolutional layer (composed of several 3x3 kernels) can be depicted as:
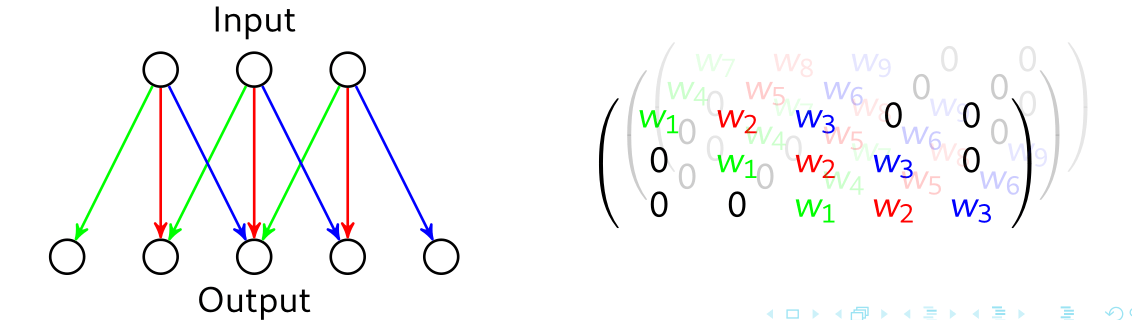
With a image that inputs, this will correspond to the following structure (source):
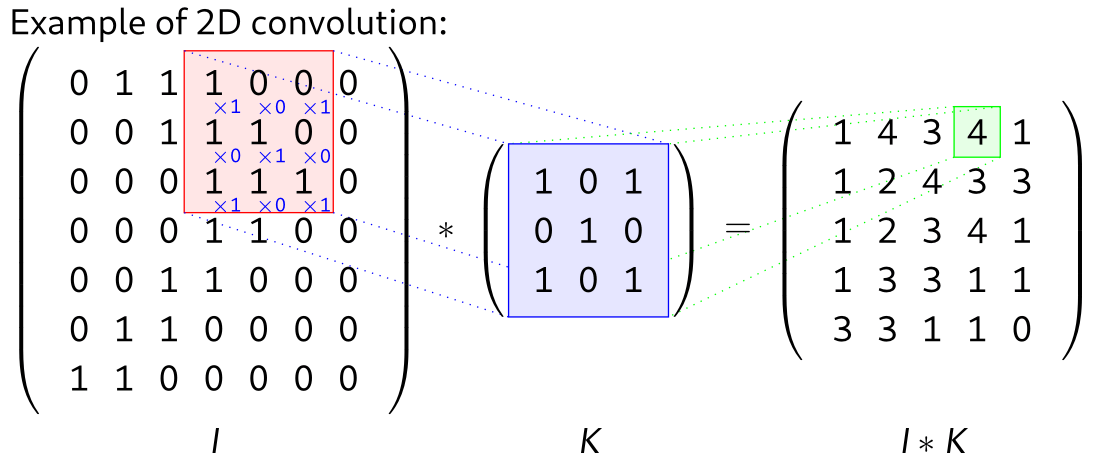
A convolutional layer in a CNN is typically composed of several (up to a few hundreds) of kernels, that are recombined to produce one output. CNN have been the state of the art in computer vision for many years, and are still used in 2024, sometimes combined with other types of layers such as Transformers.
To go further
3 — Transformers
Transformers are the last major innovation in the deep learning field, and have enabled a very rapid progress in language applications. Transformers are the basis of most large language models (LLM) (they are the T in GPT: “Generative Pretrained Transformer”).
A overview of how transformers work can be found here.
4 — Self-supervised learning
It is possible to train large deep learning models by exploiting simple manipulations on input data, without needing labels. This is called Self-supervised learning.
There are two main paradgims:
-
Masking / self-prediction – The idea is to mask certain parts of the input and predict the remaining parts.
E.g., for text:
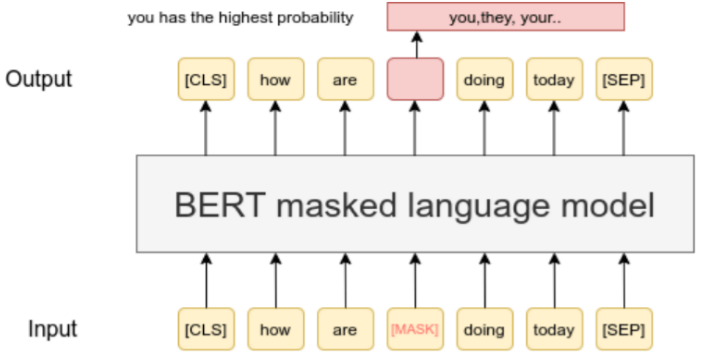 E.g., for images:
E.g., for images:
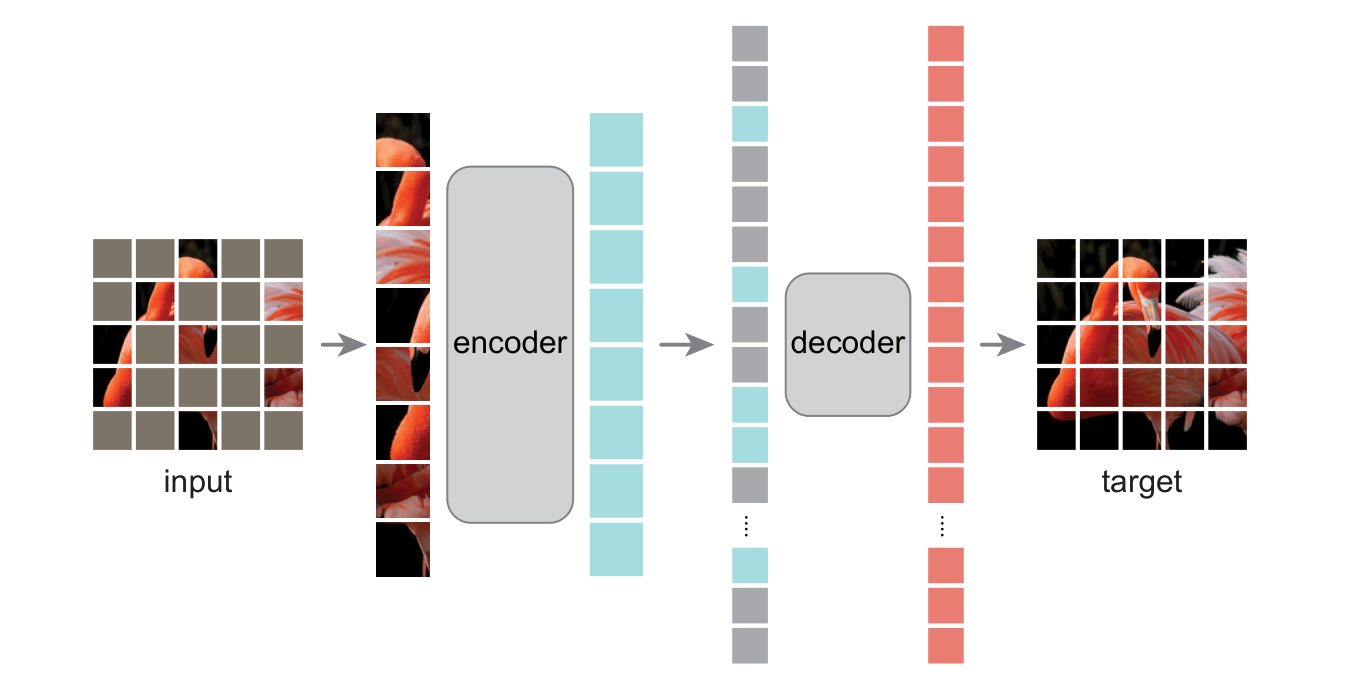
-
Contrastive learning – The idea is to generate many versions of the same input data (for example, images), using simple transformations:
E.g.,

The similarity between the different “views” can be combined to train a deep learning feature extractor, for example using the SimCLR algorithm (image also borrowed from the SimCLR paper).
To go beyond
-
A series of videos of conferences by some of your teachers about foundation models, huge models trained on internet-scale datasets.
-
A practical oriented book with examples of code and exercices, covering deep learning from the start.
-
A little outdated, but the first 9 chapters are still worth reading if you are interested in the details.
-
The Ultimate Guide to Semi-Supervised Learning.
Modern AI models are trained with semi-supervised learning when a lot of unlabeled data are available.