What is artificial intelligence?
Reading time15 minIn brief
Article summary
The goal of this article is to introduce generalities about artificial intelligence (AI) and important related topics. There are different ways to define AI, but in modern research and applications, AI will frequently refer to algorithms that learn from data.
In this article, we propose a brief definition of AI and important related topics: machine learning (ML) and deep learning (DL).
Main takeaways
-
Artificial intelligence (AI) is a very broad family of techniques that aim at extracting knowledge from data to solve automation tasks.
-
Data is usually multidimensional, hence we consider data matrices, with samples in rows and features in columns.
-
Machine learning (ML) is a subset of AI algorithms that use data to implicitely learn solutions.
-
Deep Learning (DL) is a type of ML approach that has proved to be very efficiently at solving very complex tasks such as natural language understanding or image understanding.
Article contents
1 — What is AI?
1.1 — A simplistic definition
A simple definition of AI can be given as follows:
AI is a family of techniques that aim at extracting knowledge from observations in order to solve automation tasks.
This definition might be too simple, but defining AI this way is convenient as it encompasses all algorithms and techniques that can be defined and implemented on a computer.
Using this definition, the following could be consider as AI:
- A mathematical function.
- A search engine.
- A navigation system that finds the shortest route between a starting point and a destination.
- An agent that navigates in a environment.
- A system that recommends music based on listening history.
- A chatbot.
- A system that recognizes bird species based on a photo or a recording of its song.
In the previous courses, you have seen several examples of algorithms (tree search, sorting, …) that can fall into this definition, because they automate a certain task. Many algorithms can be defined in the context of discrete mathematics (e.g., using graphs, tree, paths, …) in order to define deterministic algorithms, or can also rely on stochastic (probabilistic) algorithms.
1.2 — What are we talking about?
More broadly, AI can also be defined as allowing a machine to reason about things, which has been a pillar of science fiction for centuries. Thus, the term “artificial intelligence” is generally pretty vague, and tends to denote something different across time.
In our current period, for most people, AI generally denotes “intelligent” assistants (e.g., ChatGPT, GitHub Copilot) but also generative models for images (e.g., Midjourney), audio (e.g., Suno) videos (e.g., Sora), etc. While these tools may seem different, they all rely on a common technique, called “machine learning”.
You will see below and in other articles of this session that machine learning itself can be organized in subcategories, depending on which kind of data is available, what task is to be solved, and what sort of algorithm is used. The following diagram (source) gives a nice overview of some keywords you may find in the wild:
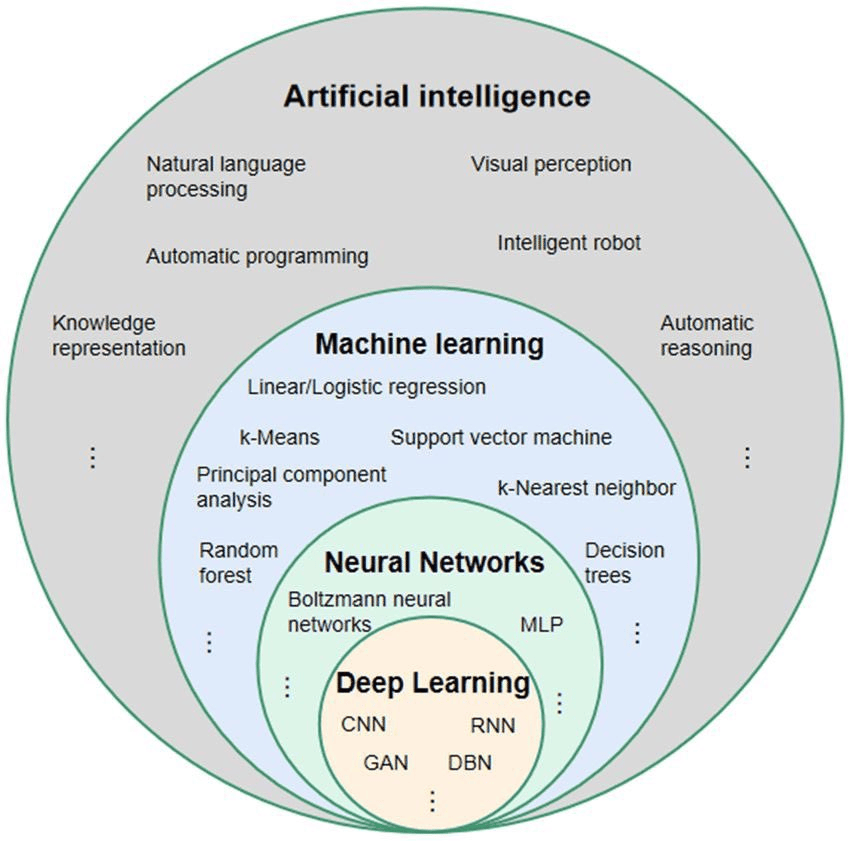
2 — Machine learning
2.1 — General definition
As mentioned above, we are mostly interested in machine learning, which aims at learning a model of a broad concept, from data, with some degree of automation.
Formally, in most cases we can model knowledge extraction as a function $f:\mathbb{R}^d \to \mathbb{R}^p $ that maps a $d$-dimensional input $x$ to a $p$-dimensional output $y = f(x)$. In general, $f$ is a parametric function, i.e., its output depends on some parameters that have to be set prior to using the function.
Machine learning (ML) is a family of techniques that attempt at learning this mapping directly from data, during a so-called training phase.
During the training phase, a dataset is used to estimate the parameters of $f$. The goal of this phase is to obtain parameters that will generalize to new datasets that have not been used during training. These parameters are obtained by minimizing a loss function $\mathcal{L}$, which is defined according to the problem at hand (see examples in the next pages on supervised learning and unsupervised learning).
Once the parameters are set through this training phase, the function (generally called model) can be used to make predictions.
ML generally involves multidimensional data, usually represented in matrix form. A dataset of samples $x \in \mathbb{R}^d$ is thus represented as a matrix $X \in \mathbb{R}^{N \times d}$, where $N$ is the number of samples (i.e., available data). The $d$ dimensions of each sample are also called features (i.e., number of attributes representing the data).
Using only this defintion, it is already clear that ML is a very difficult task, for at least the following reasons:
- ML is ill-posed, in the sense that there are many possible solutions for a given problem.
- ML is highly dependent on the data that is used in the training phase.
- The input space is typically of a very high dimension (e.g., a grayscale image of size 224x224 pixels).
2.2 — Types of ML
ML is typically considered in three main types (detailed in next pages):
- Supervised Learning – Learning $f$ from examples of inputs $x$ knowing the corresponding outputs $y$.
E.g., we have a dataset of pictures of animals, and corresponding names. We can train a model for a classification task, by learning to predict “dog” when we show the picture of a dog.
- Unsupervised Learning – Learning $f$ from examples of $x$ only (also includes “self-supervised learning”).
E.g., we have a lot of songs, but we do not have the names and styles of the songs. We can learn to group songs that share the same rythm to determine coherent groups, using descriptors of groove, vibe, etc., based on songs similarity. This is called clustering.
- Reinforcement Learning – A dynamic form of learning that considers the function $f$ to navigate in an environment, and gets reward signals as a result of actions.
E.g., in a PyRat maze, we can make multiple games and learn from our errors, so that we gradually do better in the next game.
2.3 — Using features to represent data
A classical approach in ML is to reduce the complexity and dimensionality of the input by extracting features. Feature extraction can be done using predefined processes such as:
- Frequency or time-frequency analysis, such as Fourier transform or wavelet transform.
- Statistics, such as counts, averages, variances of individual dimensions across samples.
- Expert-defined features, such as specific filters to detect colors or edges, or preprocessing based on expert knowledge specific to a field.
- Learned features from a previously trained ML method, such as a foundation model trained using deep learning.
Since the number of features is generally smaller than the dimension of data, it is a lot easier to train a ML model from features than from the data itself. In addition, it makes the prediction more understandable from a human point of view. Indeed, if we predict the species of a tree based on its height only, we know that the prediction is just linked to that feature.
Still, note that more recent models based on deep learning do not rely on custom features to make predictions. On the contrary, these methods assume that the model will learn better feature than a human would produce. Thus, they directly make predictions from data, and compute their own intermediary features to prepare their decisions.
Such models are thus less interpretable, but generally outperform other models in performance (by a large margin).
To go further
4 — Misconceptions about AI
Importantly, the term “AI” is often misused, and subject to misconception or fantasy, which are fueled by science-fiction, exaggerated news reports or other events. At the core of such misconceptions are philosophical questions related to anthropomorphism (i.e., the process of considering as human the behavior of an AI agent), or questions about how AI can be considered as artificial life or consciousness. This can lead to unrealistic expectations about what AI can achieve, such as the assumption that it possesses consciousness, self-awareness, or intentions similar to humans. Such questions, while philosophically intriguing, are not typically the focus of computer science and fall outside the scope of this course. For those interested in exploring these themes, resources like Alan Turing’s seminal paper “Computing Machinery and Intelligence” and Shannon Vallor’s work on AI ethics provide foundational insights.
Adding to the confusion is the ongoing debate about Artificial General Intelligence (AGI), the theoretical concept of machines capable of performing any intellectual task that a human can. AGI remains a controversial and poorly defined idea, with no consensus among researchers about its feasibility, timeline, or even its core characteristics. Discussions about AGI often become intertwined with global narratives about existential risk, job displacement, and the future of humanity, which can amplify fears and misconceptions. Such questions, while philosophically and socially significant, are not the focus of this course. For further exploration of AGI and its implications, works like Nick Bostrom’s “Superintelligence” and critiques by AI practitioners like Gary Marcus provide varied perspectives.
5 — Ethical Considerations
When discussing Artificial Intelligence (AI), ethical considerations are paramount. Key topics include fairness, accountability, transparency, and the societal impact of AI systems. Fairness ensures AI does not perpetuate or amplify biases, while accountability demands clear responsibility for AI’s decisions. Transparency involves making AI systems understandable to users and stakeholders, and societal impact considers consequences like job displacement or privacy concerns.
A few excellent ressources on AI ethics:
- Weapons of Math Destruction - Kathy O’Neil.
- Science4all playlist on ethics and algorithms (in French).
On governance, check out initiatives like the AI Ethics Guidelines from the European Commission and resources from the Partnership on AI provide frameworks for ethical AI design. For further reading, explore the AI Now Institute. These tools offer practical insights to integrate ethical principles into AI development.
To go beyond
- RL Course by David Silver Lecture 1 Introduction to Reinforcement Learning.
A good introduction to reinforcement learning, not covered in this course.