Calculer les positions gagnantes dans un jeu
Temps de lecture20 minEn bref
Résumé de l’article
Dans cet article, nous vous expliquons comment trouver les positions gagnantes dans un jeu, c’est-à-dire, comment trouver des configurations qui mèneront sûrement à la victoire.
À retenir
-
Gagner un jeu consiste à atteindre une configuration de jeu où le jeu est gagné.
-
Plus largement, les régions gagnantes désignent des configurations à partir desquelles une configuration gagnante peut sûrement être atteinte.
-
Les régions gagnantes peuvent être construites en partant des configurations gagnantes.
-
Des algorithmes tels que Maximin peuvent être utilisés pour trouver une bonne stratégie dans un jeu.
Contenu de l’article
1 — Vidéo
Veuillez consulter la vidéo ci-dessous (en anglais, affichez les sous-titres si besoin). Nous fournissons également une traduction du contenu de la vidéo juste après, si vous préférez.
Information
Cliquez ici pour afficher la traduction de la vidéo.

Bonjour ! Bienvenue à la leçon d’aujourd’hui, dans laquelle je vais vous montrer comment identifier les positions gagnantes dans un jeu. Cela vous aidera à améliorer la stratégie de votre intelligence artificielle dans PyRat.

Comme vous le savez, PyRat est un jeu à deux joueurs entre un rat et un python, où chaque joueur doit naviguer dans un labyrinthe pour trouver des morceaux de fromage cachés dans le labyrinthe.

On dit qu’une stratégie pour le rat est “gagnante” si le rat est sûr de gagner la partie, quelle que soit la manière dont le python décide de se déplacer. En d’autres termes, c’est une stratégie telle que, pour toute stratégie de l’adversaire, la partie est gagnée.
Au début d’une partie de PyRat, il n’y a pas de stratégie gagnante pour aucun des joueurs, car le labyrinthe est symétrique. Par conséquent, si les deux joueurs choisissent la même stratégie, alors le résultat sera une égalité.

Mais une fois que le jeu a commencé, et si les joueurs à un moment donné font des mouvements différents et brisent la symétrie, le jeu ultérieur admettra probablement des stratégies gagnantes pour l’un des joueurs.
Déterminer si une stratégie gagnante existe est un problème de calcul très complexe. Pour ce faire, nous devons considérer deux facteurs combinatoires entrelacés, qui sont les stratégies possibles du rat et les stratégies possibles du python. En conséquence, le nombre de parties possibles dans PyRat est énorme.
En pratique, cela signifie que le calcul des stratégies gagnantes ne peut être effectué que lorsque la variabilité du jeu est réduite, par exemple lorsqu’il ne reste que quelques morceaux de fromage dans le labyrinthe.
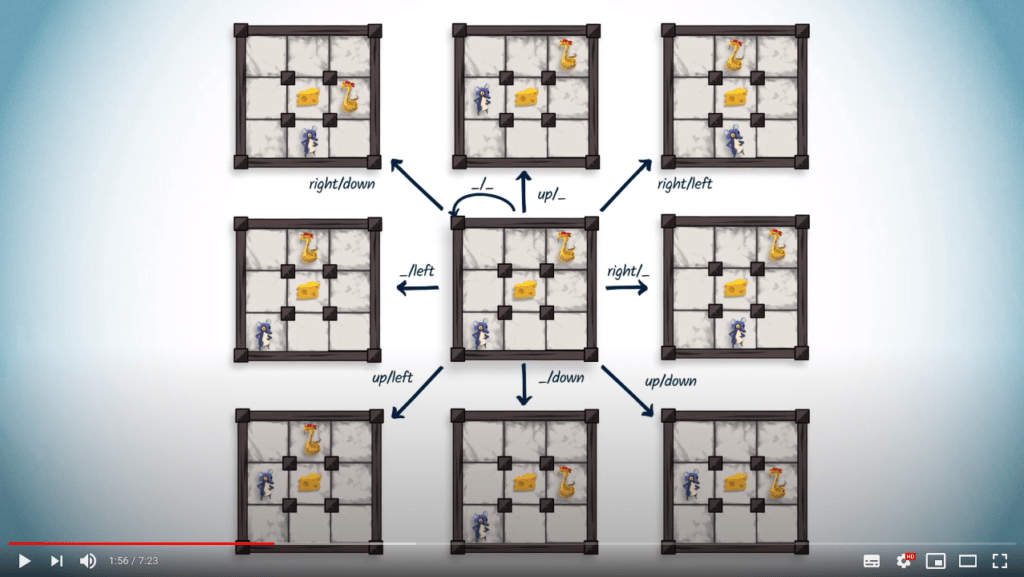
Revenons maintenant au concept d’arène. Vous vous souvenez probablement de la leçon précédente que l’arène est un graphe où chaque sommet résume l’état actuel du jeu.
Un sommet dans l’arène est une position gagnante pour un joueur si, en partant de ce sommet, le joueur a une stratégie gagnante.
Bien sûr, un sommet ne peut pas être gagnant pour les deux joueurs. Si c’était le cas, cela signifierait que les deux joueurs ont une stratégie qui gagne contre toute stratégie de l’adversaire. Cela impliquerait que lorsqu’ils jouent tous les deux avec leurs stratégies gagnantes, ils gagnent tous les deux, ce qui n’est pas possible. Donc un sommet ne peut être gagnant que pour un seul joueur.
Voyons maintenant comment calculer les stratégies gagnantes. Prêt ?
Si vous êtes à un sommet donné dans l’arène, pour trouver le meilleur mouvement, celui qui vous maintient dans la région gagnante de l’arène, vous devez prendre en compte tous les choix ultérieurs possibles de l’adversaire. Dans un jeu comme PyRat, le nombre de telles combinaisons est probablement trop grand pour être traité.

Imaginez une partie de PyRat qui est limitée à 2 000 décisions pour chaque joueur. À chaque étape, les deux joueurs choisissent une direction dans laquelle se déplacer. Au strict minimum, chaque joueur a l’un des deux choix à faire : se déplacer ou ne pas se déplacer. Dans ce cas, le nombre de parties possibles est au moins $(2 \cdot 2)^{2000}$, ce qui est énorme.
Une meilleure approche consiste à stocker des connaissances partielles sur les stratégies et positions gagnantes. Ce type d’approche est appelé “programmation dynamique”.
Il est possible de caractériser l’état d’un jeu par la position du rat, la position du python, les emplacements des morceaux de fromage restants et le score de chaque joueur.

Encore une fois, imaginez une instance de PyRat dans laquelle le labyrinthe contient $15 \times 11$ cellules, soit 165 cellules, et disons qu’il y a 7 morceaux de fromage. Notez que nous n’avons pas besoin de conserver les emplacements réels des morceaux de fromage, car ils ne bougeront pas pendant le jeu, mais nous devons seulement retenir lesquels ont été mangés et lesquels sont encore dans le labyrinthe. Donc dans cet exemple, il y a 2 configurations possibles pour chacun des 7 morceaux de fromage, ce qui fait un total de $2^7$ configurations possibles. De plus, il y a 165 positions possibles pour chaque joueur. Concernant les scores, nous n’avons besoin de stocker que le score d’un joueur, car cela, avec les morceaux de fromage restants, peut être utilisé pour récupérer le score de l’autre joueur. Il y a donc 5 scores possibles pour un joueur, entre 0 et 4. Finalement, il y a un maximum de $2^7 \cdot 165 \cdot 165 \cdot 5 \approx 17~\text{millions}$ de sommets dans l’arène.
Rappelez-vous que les sommets dans l’arène représentent des configurations de jeu.
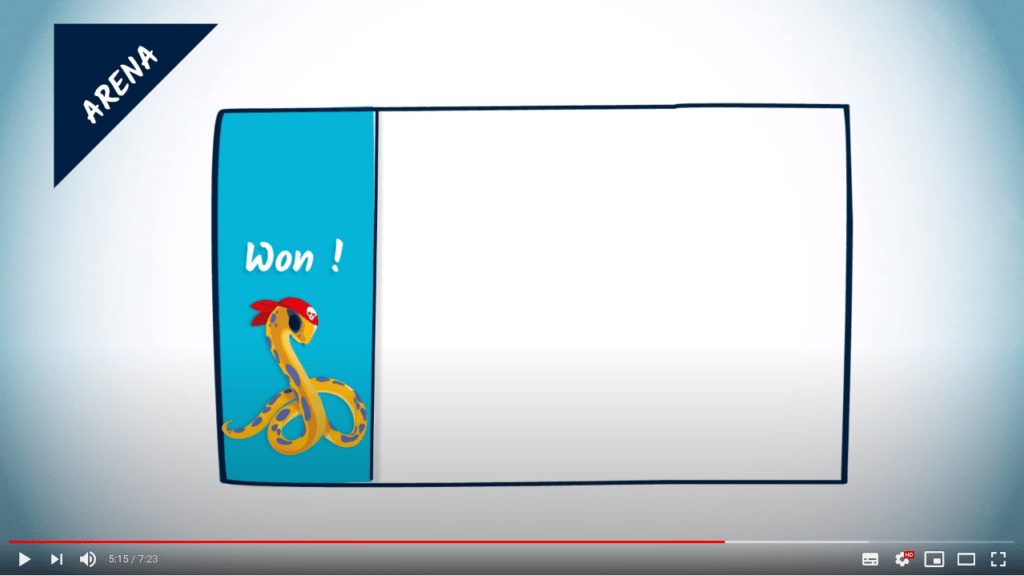
Donc une façon de calculer les stratégies gagnantes commence par identifier d’abord les sommets dans l’arène, ici représentés par le rectangle, dans lesquels le jeu est déjà gagné pour un joueur. Dans l’exemple précédent, cela revient à déterminer tous les sommets où l’un des joueurs, par exemple le python, a un score de 4.
Maintenant, nous pouvons essayer d’identifier d’autres sommets de l’arène où l’un des joueurs est assuré de gagner.
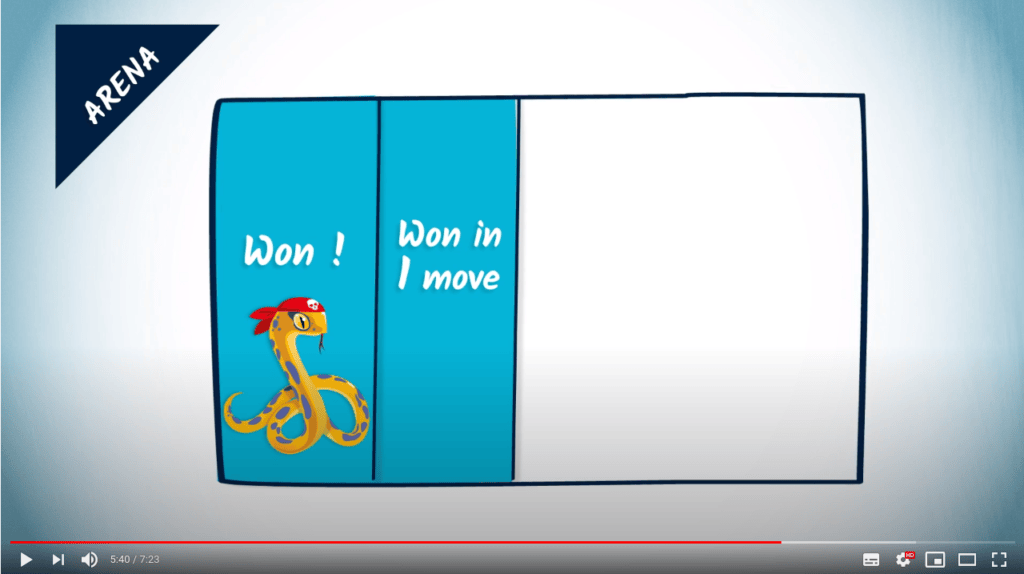
Par exemple, ce sont tous les sommets à partir desquels le joueur peut choisir un mouvement tel que, quel que soit le choix de l’adversaire, le joueur atteint un sommet dans l’arène déjà identifié comme étant gagnant.
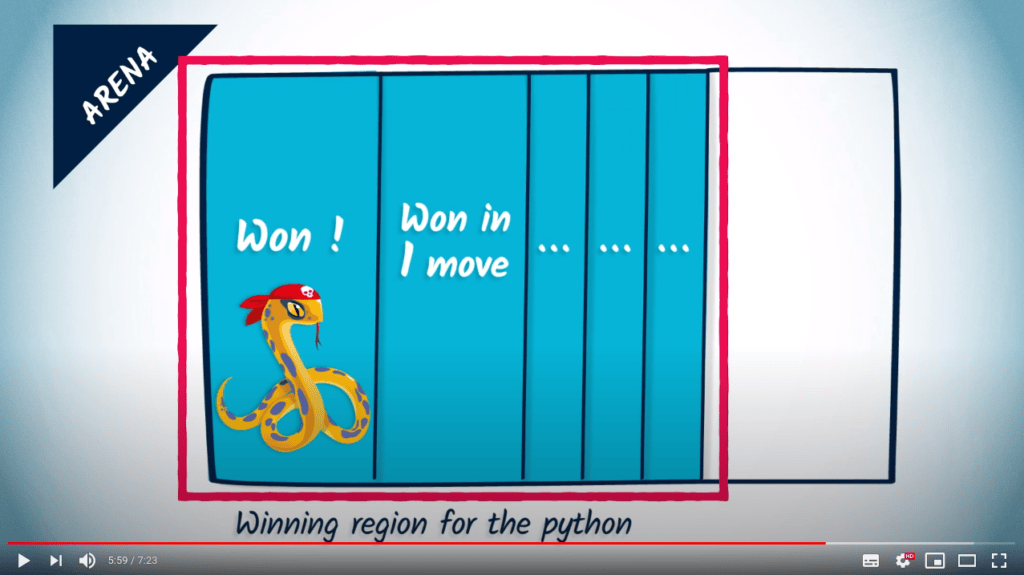
En répétant ce processus jusqu’à ce qu’aucun sommet ne puisse être ajouté à la liste des sommets gagnants, nous construisons en fait une stratégie gagnante pour le joueur et en même temps nous calculons sa région gagnante de l’arène.
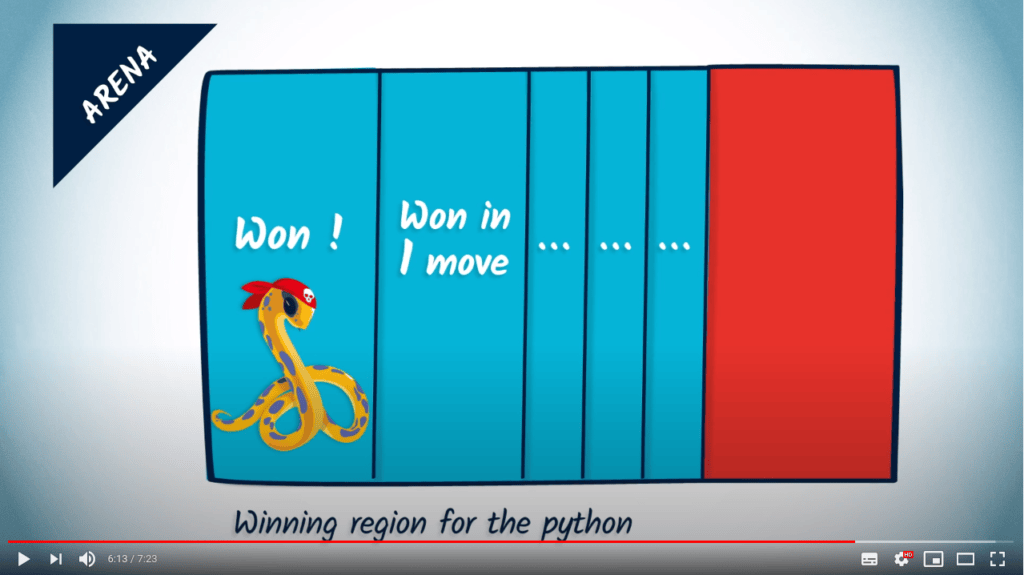
Dans la région restante de l’arène, quoi que fasse le python, le rat peut toujours se déplacer de manière à éviter d’entrer dans la région bleue de l’arène. En conséquence, il n’y a pas de stratégie gagnante pour le python dans la région rouge.
Vous devez noter que cette façon de construire une stratégie gagnante ne peut être calculée que pour un petit labyrinthe avec un nombre limité de morceaux de fromage, et n’est pas vraiment réalisable pour de grands labyrinthes. Quand il s’agit de grands labyrinthes, une meilleure approche consisterait à faire des hypothèses sur les décisions de l’adversaire, ce qui réduirait les facteurs combinatoires.
Ceci termine la leçon d’aujourd’hui. Vous avez appris comment les stratégies gagnantes peuvent être générées, mais aussi que, pour des jeux plus grands et pour certains problèmes de calcul, il pourrait être nécessaire de prendre en compte la stratégie de l’adversaire.
C’est maintenant à vous de mettre tout cela en œuvre dans votre IA dans PyRat !
Malheureusement, cette vidéo était la dernière de ce MOOC. J’ai vraiment apprécié d’explorer les sujets de ce cours avec vous ! Vincent, Nicolas et moi espérons que vous avez appris beaucoup de choses fascinantes sur les algorithmes, et que votre IA sera suffisamment intelligente pour battre de nombreux adversaires.
Que le fromage soit avec vous !
Pour aller plus loin
2 — L’algorithme maximin
En théorie des jeux (plus précisément dans les jeux à information complète et à somme nulle), l’algorithme maximin vise à trouver le meilleur coup à jouer à chaque étape, en supposant que l’adversaire jouera de manière optimale. L’objectif pour l’adversaire est donc de minimiser notre gain, tandis que le nôtre est de le maximiser.
Concrètement, l’idée principale de l’algorithme est de partir des feuilles de l’arbre des solutions, et de donner un score à chacune de ces feuilles, correspondant au gain qu’elle nous procure.
Ensuite, nous allons remonter l’arbre jusqu’à atteindre la racine, en alternant des minimisations des scores et des maximisations. Cette alternance modélise les choix soit du joueur, soit de l’adversaire.
2.1 — Exemple
Décrivons ce qui se passe sur un exemple, tiré de la page Wikipédia sur l’algorithme Minimax (minimax est juste le problème symétrique de maximin dans lequel nous voulons minimiser une fonction de perte plutôt que maximiser un gain) :
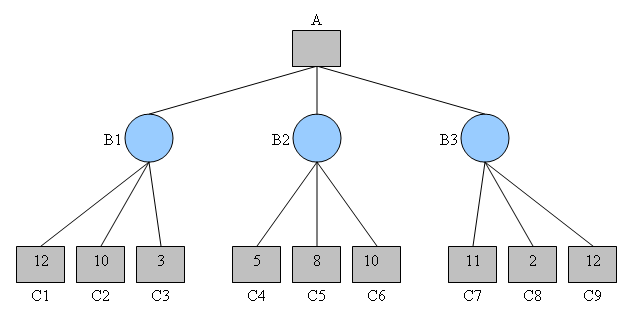
Ici, nous avons un arbre d’exécutions possibles d’un jeu, dans lequel les profondeurs modélisées par des carrés indiquent notre tour de jouer, et les cercles indiquent le tour de l’adversaire.
Pour chaque nœud cercle, l’adversaire essaiera de minimiser notre gain, en choisissant d’effectuer l’action qui mène au gain minimum pour nous. Par conséquent, l’algorithme minimax supposera les choix suivants :
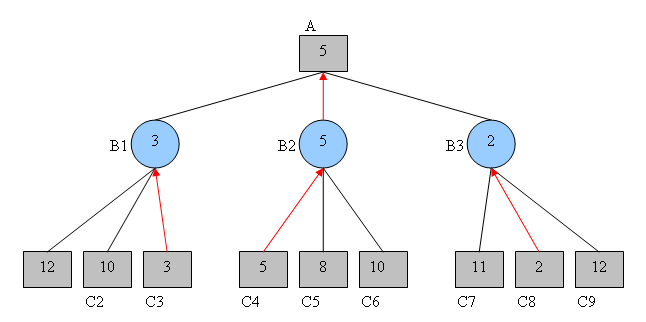
Ce que cela signifie maintenant, c’est que, si j’atteins l’état du jeu $B1$, l’adversaire jouera de sorte que notre gain total soit 3, obtenu à partir de l’état $C3$. Si nous faisons en sorte que le jeu aille à l’état $B2$, notre adversaire peut jouer de sorte que le gain soit 5 en imposant l’état $C4$. Enfin, si nous jouons pour atteindre la situation $B3$, l’adversaire peut jouer de sorte que le gain soit 2 en imposant l’état $C8$.
Le choix optimal pour nous est donc de maximiser le gain, et de jouer de sorte que nous atteignions l’état $B2$. En faisant ce choix, le meilleur gain que l’on peut espérer face à un adversaire optimal est 5 :
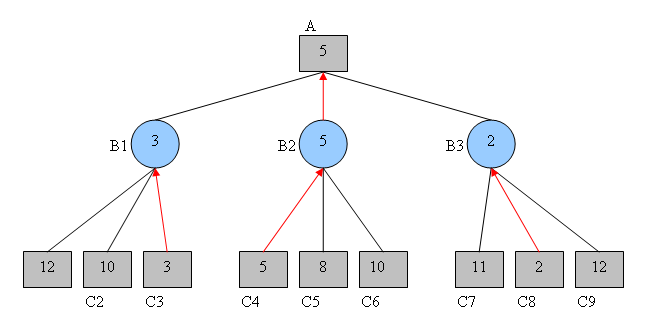
L’algorithme minimax consiste à alterner ces étapes de minimisations et de maximisations, afin de maximiser le gain que nous attendrions finalement en prenant une décision.
Il est important de noter que l’algorithme maximin ne retournera pas la séquence de coups qui mène au gain le plus élevé possible (qui dans l’exemple ci-dessus serait $C9$ avec un gain de 12), mais la séquence de jeu la moins pire, i.e., celle qui mène de manière réaliste à notre meilleur gain.
Pour conclure, notez qu’ici nous alternons les décisions entre les joueurs, ce qui implique qu’ils prennent leurs décisions à tour de rôle. Néanmoins, il existe des résultats équivalents pour les jeux simultanés tels que PyRat.
Pour aller encore plus loin
- Minimax Algorithm in Game Theory.
Quelques codes pour implémenter un algorithme minimax.